通过对 81 篇剪枝论文的归纳总结,我们发现该领域缺少 standardized benchmarks 和 metrics,于是作者提出了一个开源框架 ShrinkBench。本框架开源地址为:HERE。

Sec.2 Overview of Pruning
作者在2.3节讨论了剪枝策略的不同:
- 结构:非结构化 & 结构化剪枝
- 打分方法(scoring):局部算法 & 全局算法
- 调度方法(scheduling):one-shot & 迭代算法
- 微调(fine-tuning):有些方法并不涉及到微调,比如 rewinding (ICLR2020) 和 rethinking (ICLR2019)。
作者指出传统的 FLOPs 和 PARAMs 并不能代表实际应用时的 latency / throughout / memory usage / power consumption 都有差,该领域的公认 metric 存在问题。当然这已不是什么新鲜事了。
Sec.3 Lessons from the Literature
81 = 79 篇 2010 年之后发表的工作 + 2 篇老工作:
- LeCun, Y., Denker, J. S., and Solla, S. A. Optimal brain damage. In Advances in neural information processing systems, pp. 598–605, 1990.
- Hassibi, B., Stork, D. G., and Wolff, G. J. Optimal brain surgeon and general network pruning. In IEEE international conference on neural networks, pp. 293–299. IEEE, 1993.
总结如下:
- 压缩率较小时模型一般会涨点
- 大部分剪枝算法都会超越 random pruning 和 uniform pruning
- 参数的重要性 —— when holding the number of fine-tuning iterations constant, many methods produce pruned models that outperform retraining from scratch with the same sparsity pattern —— 似乎是在说剪枝过程中调出来的参数也很重要,从头训练稀疏网络往往达不到这种精度。但是这违背了《the lottery ticket hypothesis》《rethink the value of network pruning》的结论。
- 参数量相同的条件下,sparse net 精度往往高于 dense net —— Another consistent finding is that sparse models tend to outperform dense ones for a fixed number of parameters.
在3.3节讨论了与轻量级网络部署相比,剪枝的 effectiveness。统计了在 ImageNet 验证集的精度,发现剪枝模型往往可以超过全模型,但是很少可以超过一个与其 FLOPs/PARAMs 相当的全新架构(比如 EfficientNet):
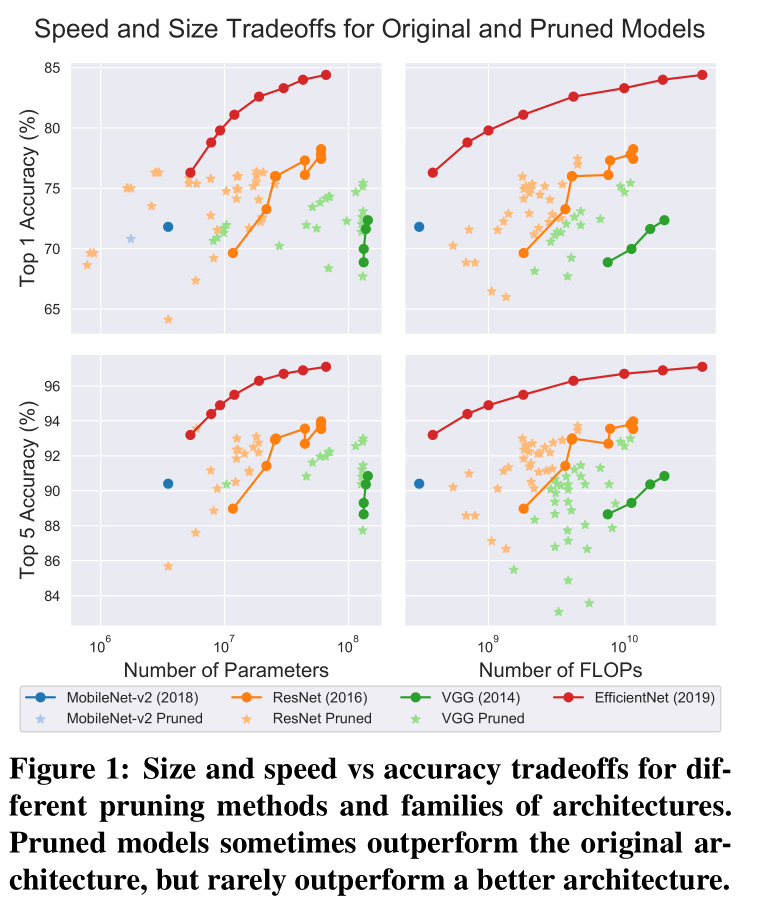
但是此图还表明 —— it suggests that pruning is more effective for architectures that are less efficient to begin with.
Sec.4 Missing Controlled Comparisons
在4.1节中,作者发现目前大多数剪枝算法并没与2010年之前的工作进行比较。
Indeed, multiple authors have rediscovered existing methods or aspects thereof, with Han et al. (2015) reintroducing the magnitude-based pruning of Janowsky (1989), Lee et al. (2019b) reintroducing the saliency heuristic of Mozer & Smolensky (1989a), and He et al. (2018a) reintroducing the practice of “reviving” previously pruned weights described in Tresp et al. (1997).
- Deep Compression
- Lee, N., Ajanthan, T., and Torr, P. H. S. Snip: single-shot network pruning based on connection sensitivity. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 69, 2019. OpenReview.net, 2019b
- Soft Filter Pruning
作者发现目前大多数剪枝算法并没有真正与SOTA的结果进行比较 —— Nearly all papers compare to three or fewer. This might be adequate if there were a clear progression of methods with one or two “best” methods at any given time, but this is not the case。
作者认为要在 large-scale benchmark dataset 上进行验证,MNIST 不靠谱。
作者发现很少有工作会绘制 metric-accuracy-trade-off 曲线,并与其它工作进行比较。哪怕有绘制曲线也没有意义 —— Even when methods are nearby on the x-axis, it is not clear whether one meaningfully outperforms another since neither reports a standard deviation or other measure of central tendency. Finally, most papers in our corpus do not report any results with any of these common configurations.
作者在4.5节讨论了导致剪枝算法无法比较的各种因素(Confounding Variables),包括:
- 模型初始化/预训练模型的选择 Accuracy and efficiency of the initial model 在第7章有讲
- 数据增强方法 Data augmentation and preprocessing
- 超参数 Random variations in initialization, training, and finetuning. This includes choice of optimizer, hyperparameters, and learning rate schedule.
- 调度 Pruning and fine-tuning schedule
- 开发框架 Deep learning library. Different libraries are known to yield different accuracies for the same architecture and dataset and may have subtly different behaviors.
- 代码习惯 Subtle differences in code and environment that may not be easily attributable to any of the above variations.
Sec.5 Further Barriers to Comparison
在5.1节,作者发现大家对模型的定义都不一样(ResNet Identity or Shortcut, VGGNet w. or w.o. BN/FC)。
在5.2节,作者发现大家对 compression ratio, speedup 的定义不同,尤其是 FLOPs 的算法不同 —— We found up to a factor of four variation in the reported FLOPs of different papers for the same architecture and dataset, with (Yang et al., 2017) reporting 371 MFLOPs for AlexNet on ImageNet, (Choi et al., 2019) reporting 724 MFLOPs, and (Han et al., 2015) reporting 1500 MFLOPs.
Sec.6 Summary and Recommendations
第6章总结了上述的内容,提出了他们的推荐实验 configuration。
值得一提的是,作者建议同时 report FLOPs 和 PARAMs,认为二者 correlation 不强。
Sec.7 ShrinkBench
其实就是集成了最基本的 baseline method,但好像是非结构剪枝的:
- Global Magnitude Pruning - prunes the weights with the lowest absolute value anywhere in the network.
- Layerwise Magnitude Pruning - for each layer, prunes the weights with the lowest absolute value.
- Global Gradient Magnitude Pruning - prunes the weights with the lowest absolute value of (weight × gradient), evaluated on a batch of inputs.
- Layerwise Gradient Magnitude Pruning - for each layer, prunes the weights the lowest absolute value of (weight × gradient), evaluated on a batch of inputs.
- Random Pruning - prunes each weight independently with probability equal to the fraction of the network to be pruned.
其中 Gradient Magnitude Pruning 是泰勒近似那篇文章的方法。
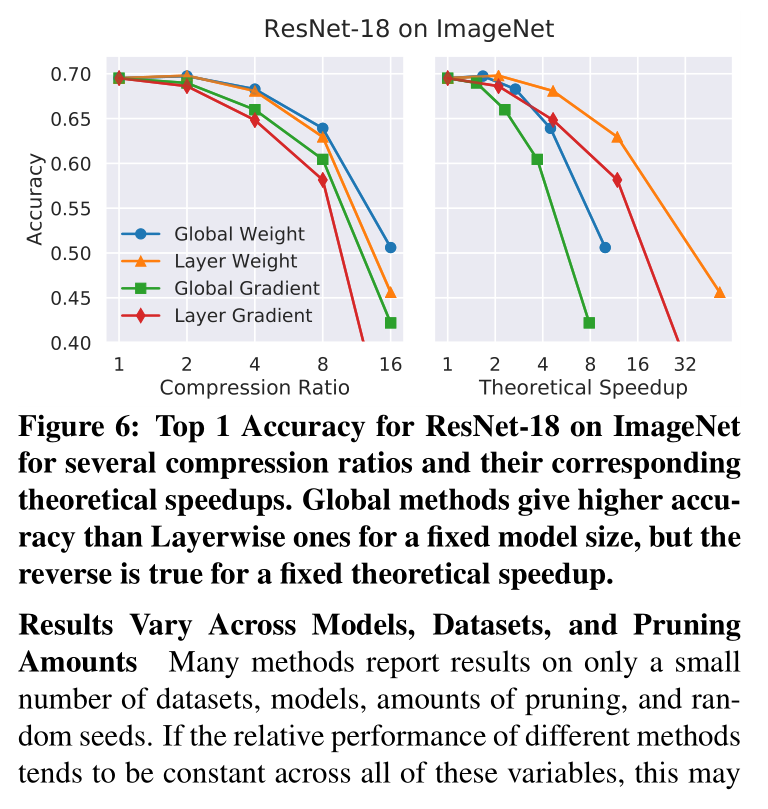
上图发现对于给定的 model size,global 优于 layerwise;但是在给定 FLOPs 时则相反。
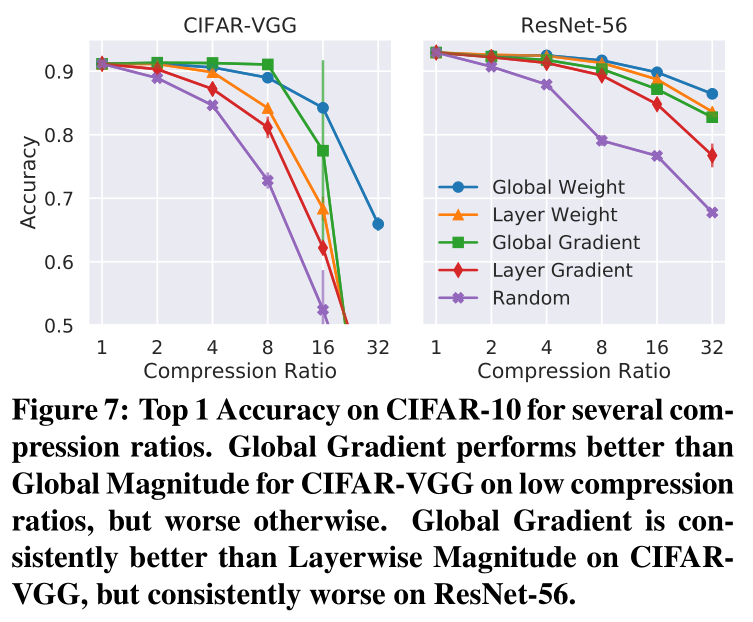
上图发现四种方法在不同的网络里表现是不同的。
以上两图,作者都没有提及实验超参的选择,是 one-shot 还是 iterative,但我认为是同一 configuration 。
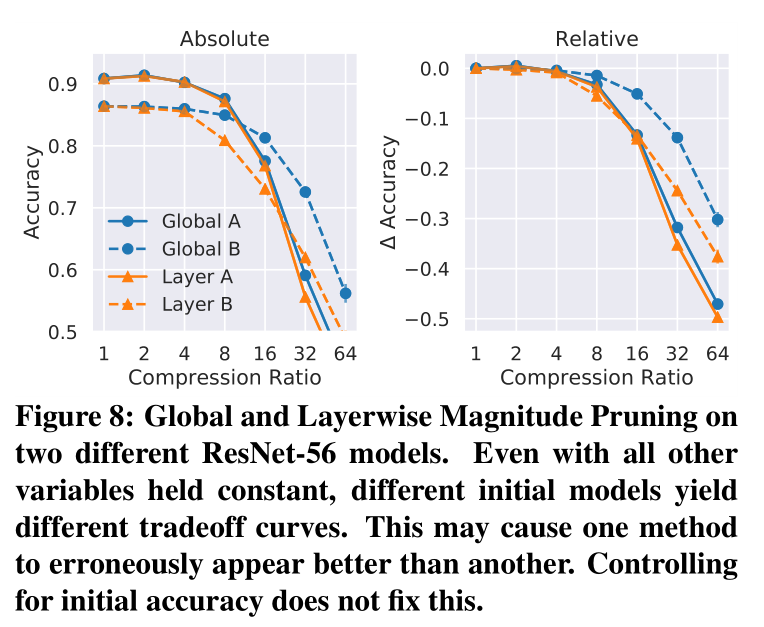
上图发现预训练模型的参数对剪枝结果有影响(左),accuracy drop 这个 metric 可能也有问题(右)—— We see this on the right side of Figure 8, where Layerwise Magnitude with Weights B appears to outperform Global Magnitude with Weights A, even though the former never outperforms the latter when initial model is held constant.
这个图还是挺牛逼的。
我的评价
作者的野心很大,提出了一个可以统一整个 community 的 benchmark,但目前只有五个 magnitude-based baseline method 有点 weak,而且结构化非结构化应该都考虑进来。
预训练模型对剪枝结果的影响,这个部分确实应该在后续的工作中有提及,应该注意一下。
主要创新点在对81篇文章进行分析那里,客观地评价了现有的工作都是在“微调”,并不存在真正的 SOTA;并且各有各的 benchmark,值得反思。而且最关键的是,到底是剪枝,还是换一个新模型(EfficientNet 牛逼),是时候有结论了。