作者 Zhuang Liu,是《network slimming》《densenet》和《rethinking》的作者,清华姚班 + 伯克利博士。

Sec.1 Introduction
In this paper, we propose deep networks with stochastic depth, a novel training algorithm that is based on the seemingly contradictory insight that ideally we would like to have a deep network during testing but a short network during training. We resolve this conflict by creating deep Residual Network architectures (with hundreds or even thousands of layers) with sufficient modeling capacity; however, during training we shorten the network significantly by randomly removing a substantial fraction of layers independently for each sample or mini-batch. The effect is a network with a small expected depth during training, but a large depth during testing. Although seemingly simple, this approach is surprisingly effective in practice.
We also observe that similar to Dropout, training with stochastic depth acts as a regularizer, even in the presence of Batch Normalization. On experiments with CIFAR-10, we increase the depth of a ResNet beyond 1000 layers and still obtain significant improvements in test error.
Sec.3 Deep Networks with Stochastic Depth

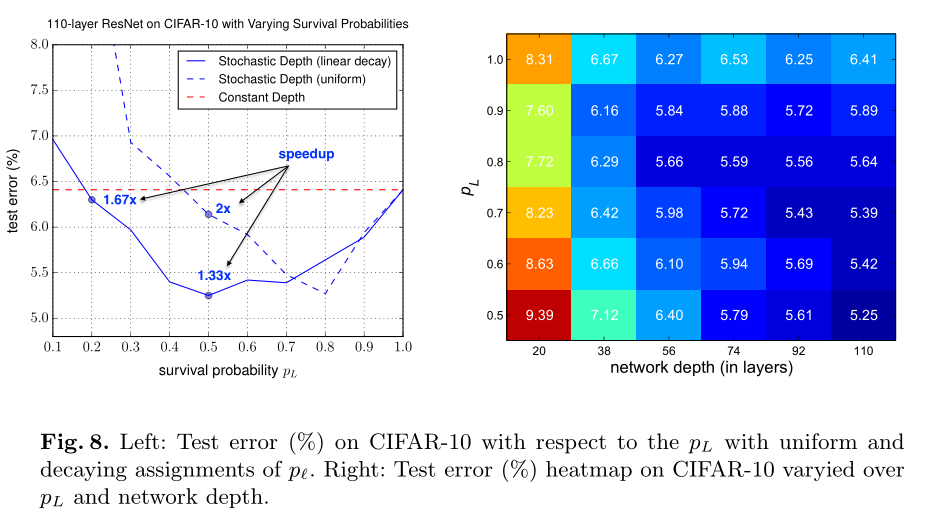
对于伯努利变量 b,其概率(The survival probabilities)有两种方案:
- uniform assignment
- layer-wise linear decaying assignment
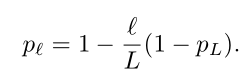

Sec.4 Results
CIFAR10 实验没看,关注的还是 Large-scale dataset 的情况,如下图。
上图的实验设置 —— We train the constant depth baseline for 90 epochs (following He et al. and the default setting in the repository) and obtain a final error of 23.06%. With stochastic depth, we obtain an error of 23.38% at epoch 90, which is slightly higher. We observe from 上图 that the downward trend of the validation error with stochastic depth is still strong, and from our previous experience, could benefit from further training. Due to the 25% computational saving, we can add 30 epochs (giving 120 in total, after decreasing the learning rate to 1e-4 at epoch 90), and still finish in almost the same total time as 90 epochs of the baseline. This reaches a final error of 21.98%. We have also kept the baseline running for 30 more epochs. This reaches a final error of 21.78%.
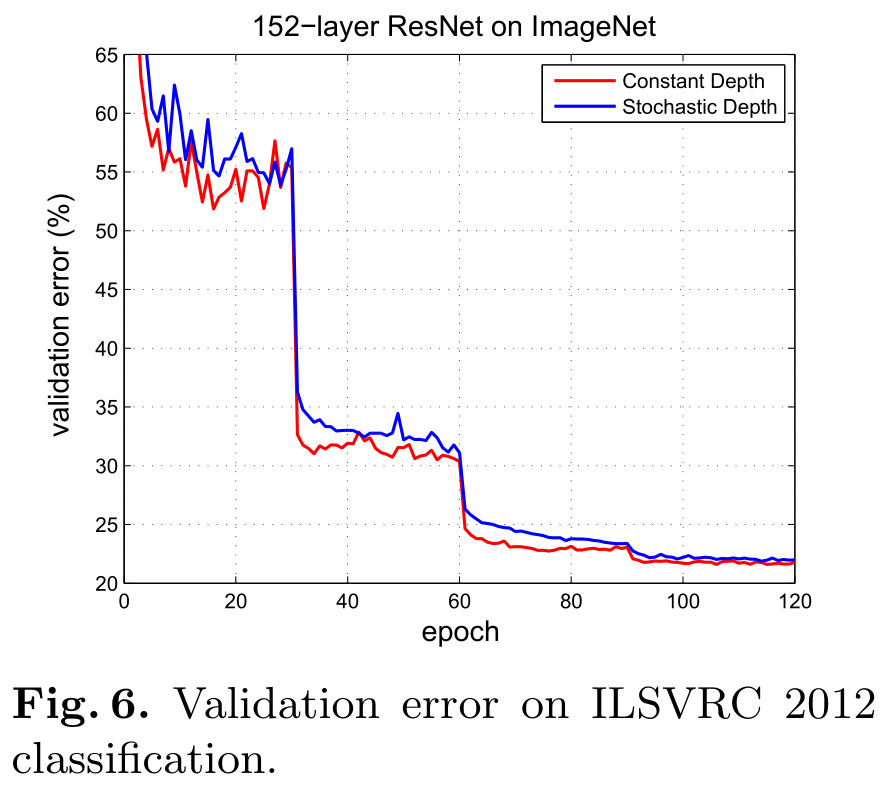
上图的实验结论 —— It can be observed that the magnitude of gradients in the network trained with stochastic depth is always larger, especially after the learning rate drops. This seems to support out claim that stochastic depth indeed significantly reduces the vanishing gradient problem, and enables the network to be trained more effectively.
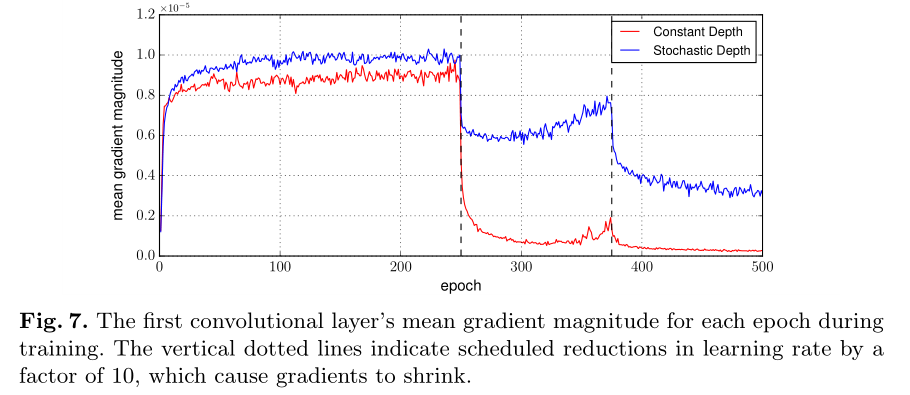
上图结论 —— layer-wise linear decaying assignment 效果更好。
引用过此工作(引用量832)的相关工作:
CVPR2019《RePr: Improved Training of Convolutional Filters》
ICCV2019《CutMix: Regularization Strategy to Train Strong Classifiers With Localizable Features》
ICCV2019《Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation》
NIPS2019《E2-Train: Training State-of-the-art CNNs with Over 80% Energy Savings》
TNNLS《Regularizing Deep Neural Networks by Enhancing Diversity in Feature Extraction》
ASPLOS2019《Split-CNN: Splitting Window-based Operations in Convolutional Neural Networks for Memory System Optimization》
NIPS2019《SCAN: A Scalable Neural Networks Framework Towards Compact and Efficient Models》
《Pruning of Network Filters for Small Dataset》
《Fast Deep Learning Training through Intelligently Freezing Layers》
WACV2020《ADNet: Adaptively Dense Convolutional Neural Networks》
《Adaptive Deep Reuse: Accelerating CNN Training on the Fly》
《Training convolutional neural networks with cheap convolutions and online distillation》
文档信息
- 本文作者:Mengqi Cao
- 本文链接:https://rogercmq.github.io//2020/06/17/%E8%AE%BA%E6%96%87%E7%AC%94%E8%AE%B0-Deep-Networks-with-Stochastic-Depth/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)