是一篇通过为不同层设计不同学习率衰减算法,从而加速神经网络训练的方法。
对于一个给定的随机初始化的神经网络,不同的层设置不同的训练 epoch/ learning rate,从而实现网络训练的加速(训练时间减少)。主要动机是:神经网络浅层尽管计算量大但是参数少,讲道理应该需要更少的训练时间就可以让其收敛,不需要像深层那样疯狂 fine-tune。

算法
方法很简单 —— FreezeOut employs cosine annealing without restarts with a layer-wise schedule, where the first layer’s learning rate is reduced to zero partway through training (at $t_0$ ), and each subsequent layer’s learning rate is annealed to zero some set time thereafter. Once a layer’s learning rate reaches zero, we put it in inference mode and exclude it from all future backward passes, resulting in an immediate per-iteration speedup proportional to the computational cost of the layer.
- I. Loshchilov and F. Hutter. Sgdr: Stochastic gradient descent with warm restarts. ICLR 2017.
- X. Gastaldi. Shake-shake regularization of 3-branch residual networks. ICLR 2017 Workshop.
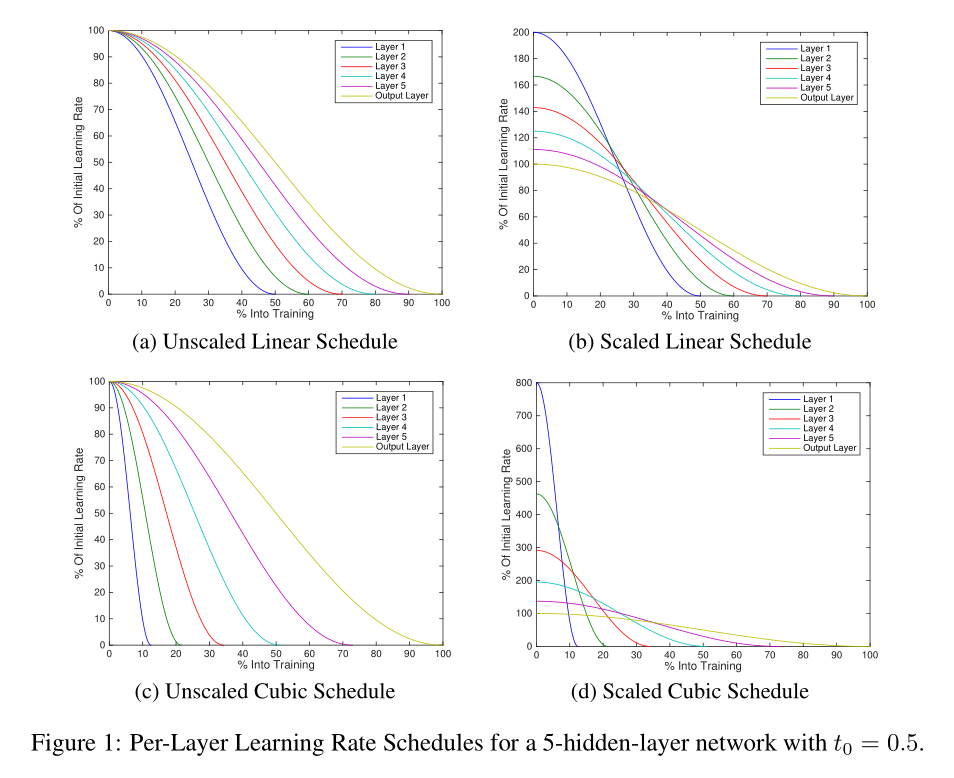
上图展示了四种淬火的方法,但是没有比较哪一种更好。
实验结果与分析
在第3章实验部分,作者修改了卷积层的结构为:ReLU-BatchNorm-Convolution,但也没说这样做的原因。
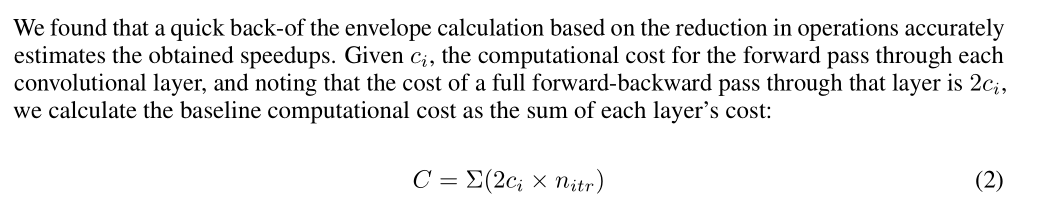

以上两图介绍了 speedup 的计算方法,C 代表 baseline computational cost,C_f 代表 freezeout computational cost,个人认为此计算方法是有问题的,只是一种理论加速比。
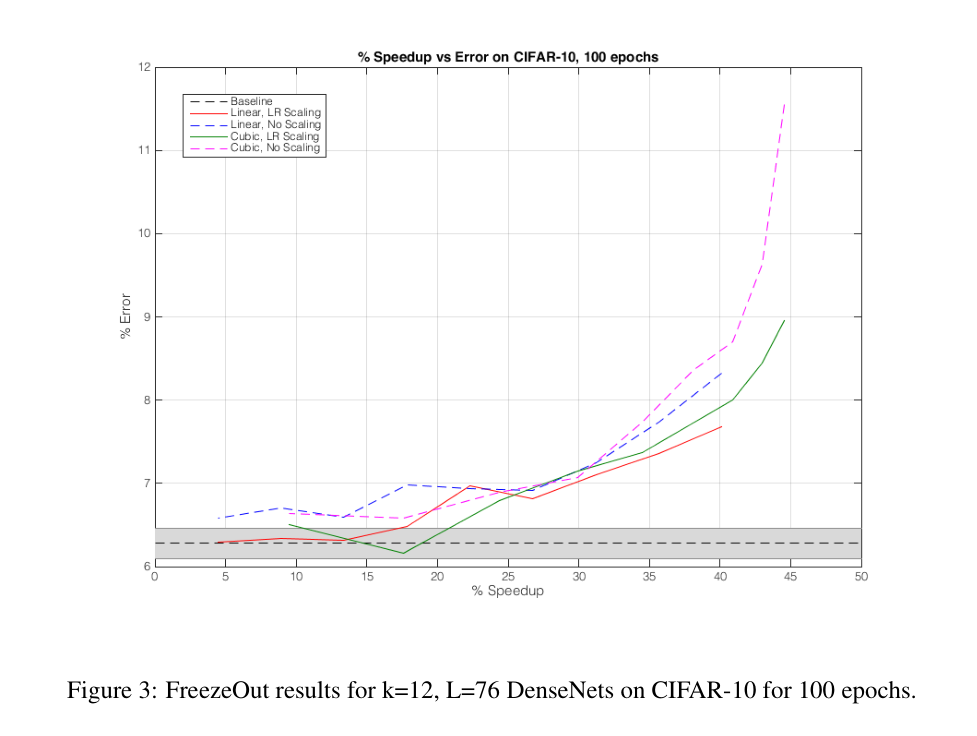
以上是关于训练时间的比较,与 baseline 方法相比确实有加速。
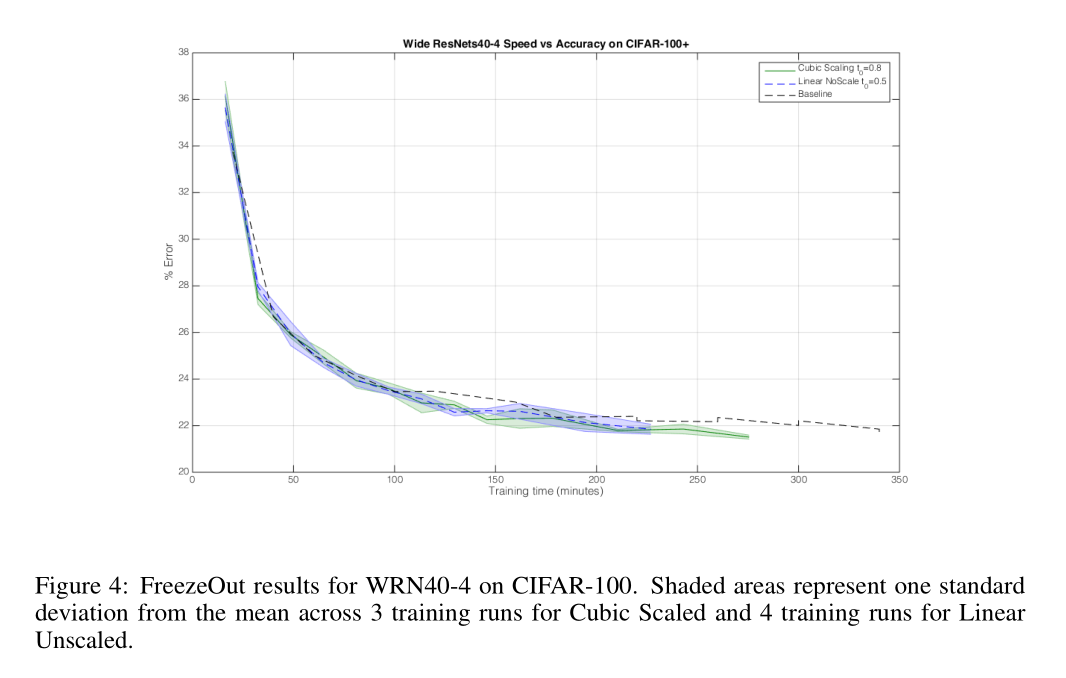
以上是对四种淬火方法的比较,横轴对应上述的 theoretical speedup 计算公式,个人认为精度掉点有点多。
引用过此工作(总引用28)的文章包括:
在所有引用过此工作的文章中我认为只有这一篇《Greedy Layerwise Learning Can Scale to ImageNet》还有让我阅读的兴趣,但扫了一眼也只是在 AlexNet 和 VGGNet 上做了一些实验。
文档信息
- 本文作者:Mengqi Cao
- 本文链接:https://rogercmq.github.io//2020/06/17/%E8%AE%BA%E6%96%87%E7%AC%94%E8%AE%B0-Freezeout/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)