乔宇:复杂视频序列的深度表征与理解方法 (1)
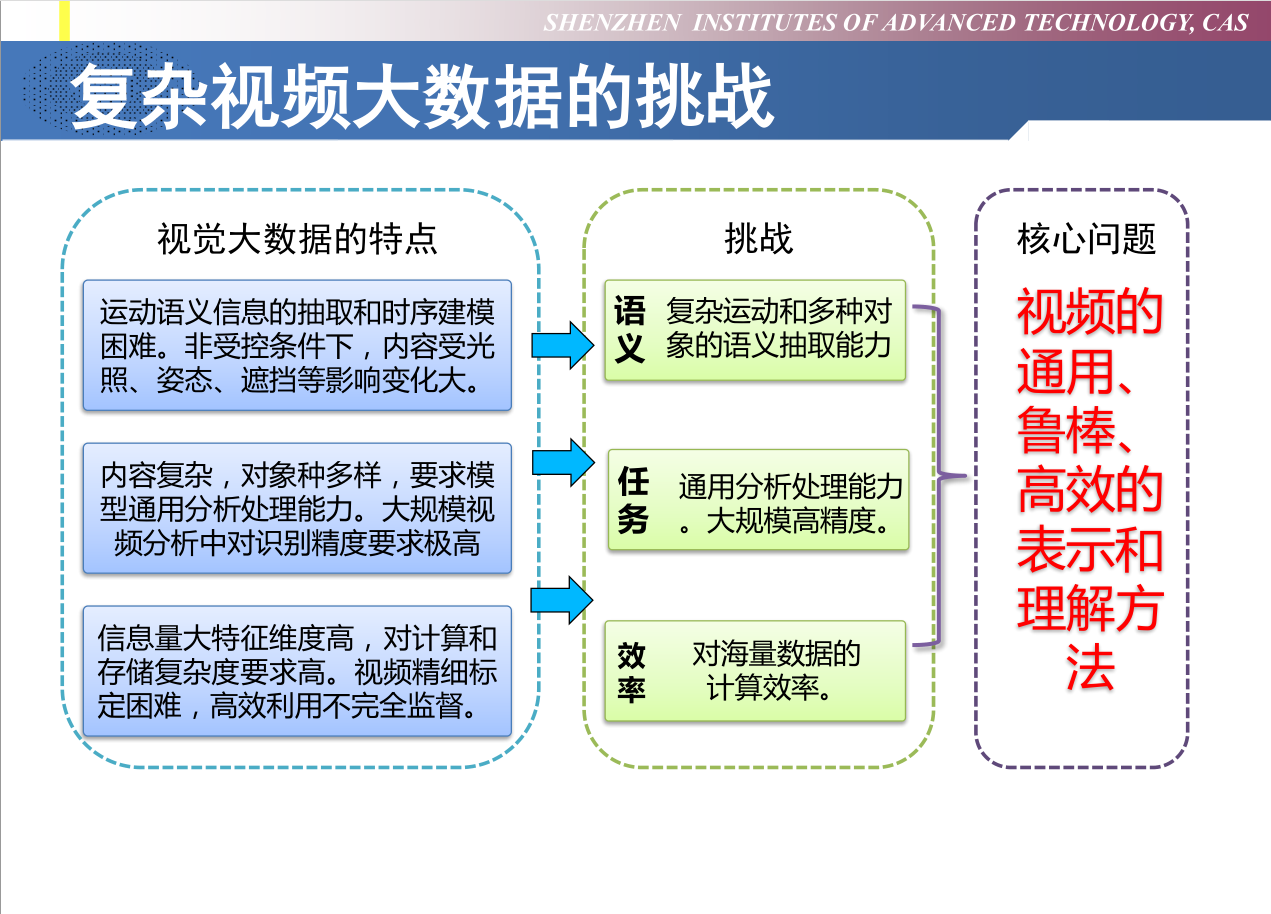
复杂视频大数据的挑战:
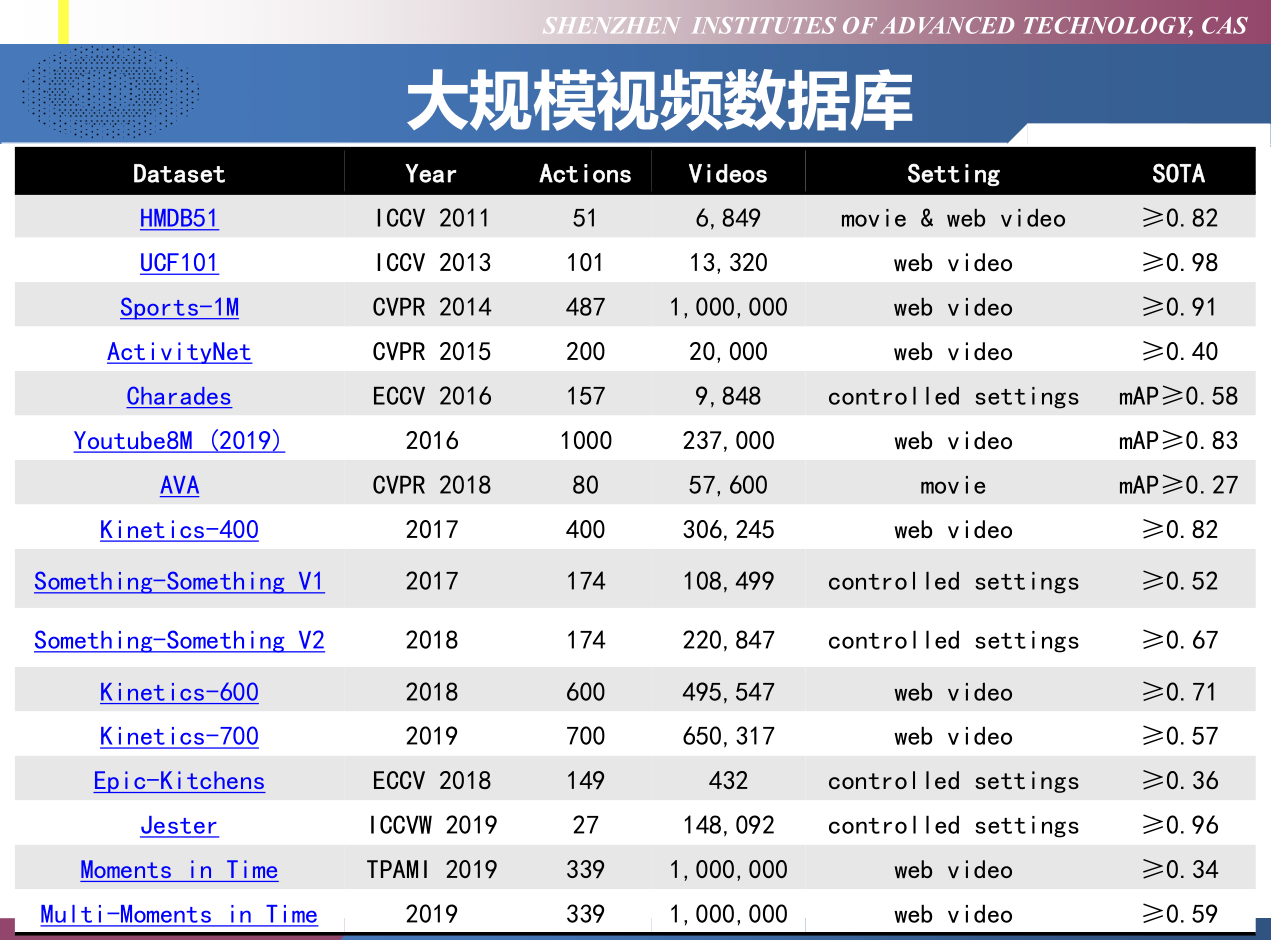
常用数据集:
| Dataset | Size | Notes |
|---|---|---|
| KTH (2014) | 包括在 4 个不同场景下 25 个人完成的 6 类动作 (walking, jogging, running,boxing, hand waving and hand clapping)共计 2391 个视频样本,是当时拍摄的最大的人体动作数据库,它使得采用同样的输入数据对不同算法的性能作系统的评估成为可能。 | 数据库的视频样本中包含了尺度变化、 衣着变化和光照变化,但其背景比较单一,相机也是固定的。 |
| Hollywood Dataset (2008,2009) | Hollywood (2008年发布)、Hollywood-2 数据库是由法国IRISA研究院发布的。早先发布的数据库基本上都是在受控的环境下拍摄的,所拍摄视频样本有限。2009 年发布的 Hollywood-2 是 Hollywood 数据库的拓展版,包含了 12 个动作类别和 10 个场景共 3669 个样本,所有样本均是从 69 部好莱坞电影中抽取出来的。 | 视频样本中行为人的表情、姿态、穿着,以及相机运动、光照变化、遮挡、背景等变化很大,接近于真实场景下的情况,因而对于行为的分析识别极具挑战性。 |
| UCF-101 | 美国 University of central Florida (UCF) 自2007年以来发布的一系列数据库:1UCF sports action dataset(2008); 2UCF Youtube(2008); 3UCF50; 4UCF101 引起了广泛关注。这些数据库样本来自从 BBC/ESPN 的广播电视频道收集的各类运动样本、以及从互联网尤其是视频网站 YouTube 上下载而来的样本。其中 UCF101 是目前动作类别数、样本数最多的数据库之一,样本为 13320 段视频,类别数为 101 类。 | |
| HMDB51 | Brown university 大学发布的 HMDB51 于 2011 年发布,视频多数来源于电影,还有一部分来自公共数据库以及 YouTube 等网络视频库。数据库包含有 6849 段样本,分为 51 类,每类至少包含有 101 段样本。 | |
| Youtube8M | 为了保证数据集的质量,在选取视频时,做了一些限制 – 每一个视频都是公开的,且每个视频至少有 1000 帧; 每一个视频的长度在 120s 到 500s 之间; 每一个视频至少与一个 Knowledge Graph entities(知识图谱实体)相联系; 成人视频由自动分类器移除 | Large-scale (8 Million video); |
| ActivityNet | 视频时序动作检测(temporal action detection); ActivityNet 是当前时序动作检测任务最大的数据集,也是最通用的数据集之一。ActivityNet 听名字与ImageNet十分相似,是目前视频动作分析方向最大的数据集,包含分类和检测两个任务。目前的 ActivityNet 包括20000个 Youtube 视频(训练集包含约10000个视频,验证集和测试集各包含约 5000 个视频),共计约700小时的视频,平均每个视频上有1.5个动作标注(action instance)。ActivityNet 涵盖了200种不同的日常活动 | Large-scale |
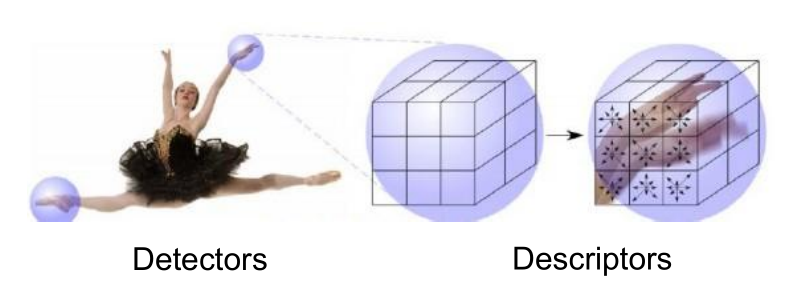
传统非深度学习方法:Local features provided a popular and effective representation for action video.
- Detectors of interest points/ trajectories(轨迹)
- Motion and Appearance Descriptors of 3d cuboids
推荐的文章: Action Recognition by Dense Trajectories (CVPR11)
论文笔记出处:CNBLOGS
通过光流场获取视频序列轨迹,沿轨迹提取形状特征、HOF、HOG、MBH特恒,再利用 BoF (Bag of features) 方法对特征编码,最后训练 SVM 分类器。主要分为三个阶段:密集特征采样、特征点轨迹跟踪、基于轨迹的特征提取。
Dense Sampling (密集采样): 在多空间尺度通过网格划分的方式密集采样特征点,多空间尺度保证了采样特征点覆盖所有空间位置及尺度。通常取8个空间尺度。后续的特征提取在各个尺度上分别进行,特征点采样间隔(W)大概为5。
Trajectory Shap Descriptor (轨迹形状描述子):
\[P_{t+1} = (x_t, y_t) + (M * \omega_t)|_{x_t, y_t}\\\] \[\omega_t = (u_t, v_t)为密集光流场,由I_t,I_{t+1}计算得到; M为中值滤波器,大小为3*3;\]可以看出,计算特征点领域内的光流中值得到特征点的运动方向。
轨迹本身也可以构成轨迹形状特征描述子:对于长度为L的轨迹,
\[用(\Delta P_t,..., \Delta P_{t+L-1})描述, \Delta P_t = (P_{t+1} - P_t) = (x_{t+1} - x_t, y_{t+1} - y_t)\]正则化后获得轨迹描述子T: \(T = \frac{(\Delta P_t,..., \Delta P_{t+L-1})}{\sum _{j = 1} ^{t+L-1} ||\Delta P_j||}\)
Motion and Structure Descriptors (运动和结构描述子):
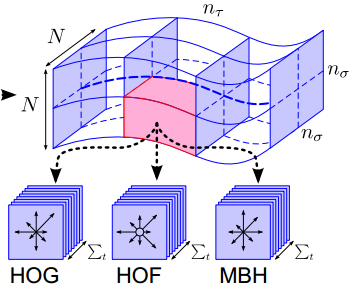
沿着某特征点长度为L的轨迹,
\[每帧图像取特征点周围N \times N区域(N=32),构成时空体(volume)\]对于时空体进行网格划分,
\[空间上每个方向划分为n_{\sigma}份(n_{\sigma} = 2); 时间上均匀选取n_{\tau}(n_{\tau} = 2),共分出 n_{\sigma} \times n_{\sigma} \times n_{\tau} 份。\]对各个区域进行特征提取特征, 在计算完后还需要进行特征的归一化,Dense Trajectories 算法中对 HOG/HOF/MBH 均使用 L2 范数归一化。对得到的特征组(T,HOG,HOF,MBH)编码,得到一个定长的编码。
Bag of Features 模型:仿照文本检索领域的Bag-of-Words方法
- 把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。
- 使用某种聚类算法(如K-means)将局部特征进行聚类,每个聚类中心被看作是词典中的一个视觉词汇(Visual Word),相当于文本检索中的词,视觉词汇由聚类中心对应特征形成的码字(code word)来表示(可看当为一种特征量化过程)。
- 所有视觉词汇形成一个视觉词典(Visual Vocabulary),对应一个码书(code book),即码字的集合,词典中所含词的个数反映了词典的大小。
- 图像中的每个特征都将被映射到视觉词典的某个词上,这种映射可以通过计算特征间的距离去实现,然后统计每个视觉词的出现与否或次数,图像可描述为一个维数相同的直方图向量,即Bag-of-Features。
在训练码书时,DT算法随机选取了100000组特征进行训练。码书的大小则设置为4000。在训练完码书后,对每个视频的特征组进行编码,就可以得到视频对应的特征。
推荐的文章: On Space-Time Interest Points (IJCV 2005)
基于时空关键点的核心思想是:视频图像中的关键点通常是在时空维度上发生强烈变化的数据,这些数据反应了目标运动的重要信息。
比如一个人挥舞手掌,手掌一定会在前后帧中发生最大移动,其周围图像数据发生变化最大。而这个人的身体其他部位却变化很小,数据几乎保持不变。如果能将这个变化数据提取出来,并且进一步分析其位置信息,那么可以用于区分其他动作。

时空关键点的提取方法是对空间关键点方法的扩展,空间关键点的提取则是基于多尺度的图像表达,这里的时空关键点就是将2D Harris角点的检测方法拓展到了3D(具体求解方法非常复杂)。得到了这些点之后,基于点的一次到四次偏导数,组合成一个34维的特征向量,使用k-means对这些特征向量进行了聚类。
本文利用 Harris 角点检测器检测时空兴趣点,即在图像局部区域空间和时间轴上像素值都有显著变化的点作为时空兴趣点。该检测器能够检测出关节的运动(articulated motion),能够检测出物体的分离和融合,不会检测出在时间轴上做匀速直线运动的点。除此之外,还能检测出一些噪声点,例如行人的外套上的一些点也会被当成兴趣点。
- 检测出的兴趣点与选取的时间尺度与空间尺度有关,尺度与动作发生的范围(人本身的行为特点)有关。为了使该检测器能够自适应尺度变化,先对视频在时间和空间做了尺度变换,即采用了不同尺度的高斯滤波函数。
- 时空兴趣点的求解采用如下思想:把视频看作三维的函数,寻找到一个映射函数,通过这个映射函数,将三维视频的数据映射到一维空间中,然后通过求此一维空间的局部极大值的点,而这些点也就是我们所需要的兴趣点。类比经典的 Harris 算法,这里扩展了一个时间维,采用高斯窗口,同理后面转换为计算一个3*3的矩阵的3个特征值,最后用这 3 个特征值的和以及积构成一个响应函数H,对H设定阈值来计算对应点是否为兴趣点。
常用(非深度学习)特征:
Reference: CSDN
- HoG (Histogram of Gradients)

- HoF (Histogram of Optical Flow)
- MBH (Motion Boundary of Histogram)
- 对于HOG特征,其统计的是灰度图像梯度的直方图;对于HOF特征,其统计的是光流(包括方向和幅度信息)的直方图。而对于MBH特征,它的处理方法是将x方向和y方向上的光流图像视作两张灰度图像,然后提取这些灰度图像的梯度直方图。即MBH特征是分别在图像的x和y方向光流图像上计算HOG特征。
- 由下图可以看出,MBH特征的计算效果就是提取了运动物体的边界信息(也因此被称为Motion Boundary Histograms),在行人检测这个应用场景能起到不错的效果。此外,其计算也非常简单方便,易于使用。

文档信息
- 本文作者:Mengqi Cao
- 本文链接:https://rogercmq.github.io//2020/06/19/%E8%AE%B2%E5%BA%A7%E7%AC%94%E8%AE%B0-VALSE-Action-Recognition(1)/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)