乔宇:复杂视频序列的深度表征与理解方法 (3)
Inflated 3D (I3D) ConvNets —— 3D卷积模型
Joao Carreira et al., Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset, CVPR2017
Reference: 简书
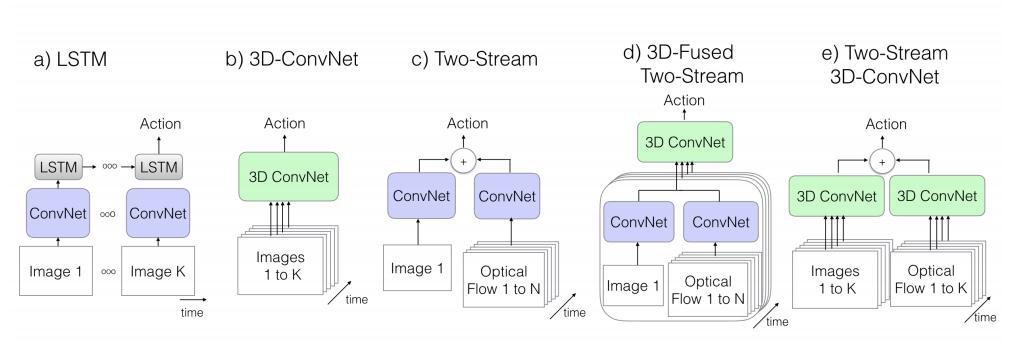
背景:3D卷积

有趣的地方:2D卷积拓展为3D:本文选用的网络结构为 BN-Inception (上一篇深度时序分割模型 TSN 也是),但做了一些改动。如果 2D 滤波器为 NxN 的,那么 3D 的则为 NxNxN 的。具体做法是沿着时间维度重复 2D 滤波器权重 N 次,并且通过除以 N 将它们重新缩放。这样来确保滤波器的响应相同。每一个卷积层的输出在时域上是固定的,对于非线性层和池化层和2D的相同。
2D 卷积其实包含了 x 和 y 两个方向,一般来说这两个方向的步长可以一致,但对于 3D 来说,时间维度不能缩减地过快或过慢。因此改进了 BN-Inception 的网络结构。在前两个池化层上将时间维度的步长设为了1,空间还是2x2。最后的池化层是 2x7x7。训练的时候将每一条视频采样 64 帧作为一个样本,测试时将全部的视频帧放进去最后 average_score。除最后一个卷积层之外,在每一个都加上 BN 层和 Relu。
文章中的 3D 网络并不是随机初始化的,而是将在 ImageNet 训好的 2D 模型参数展开成 3D,之后再训练。因此叫 Inflating 3D ConvNets。
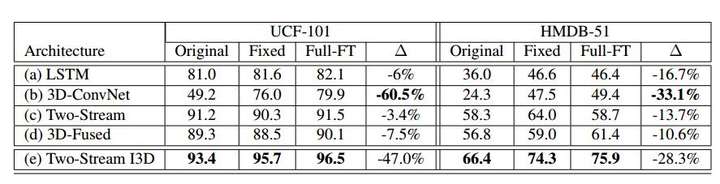
实验结果如下:
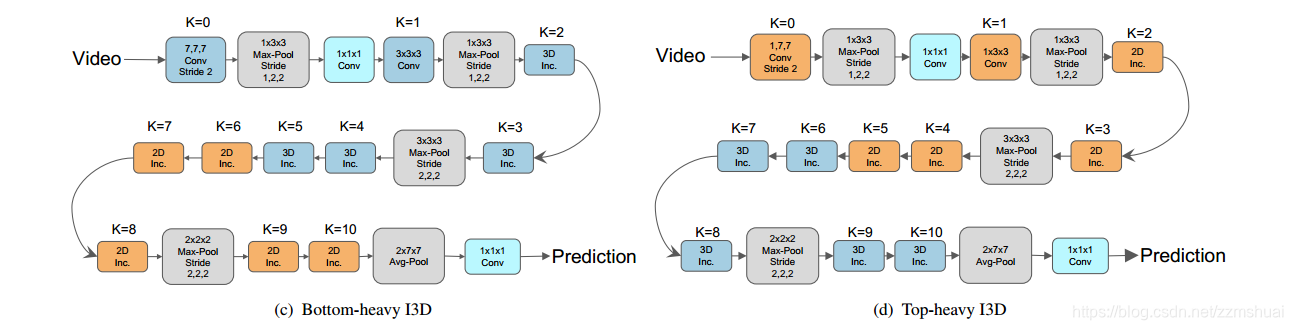
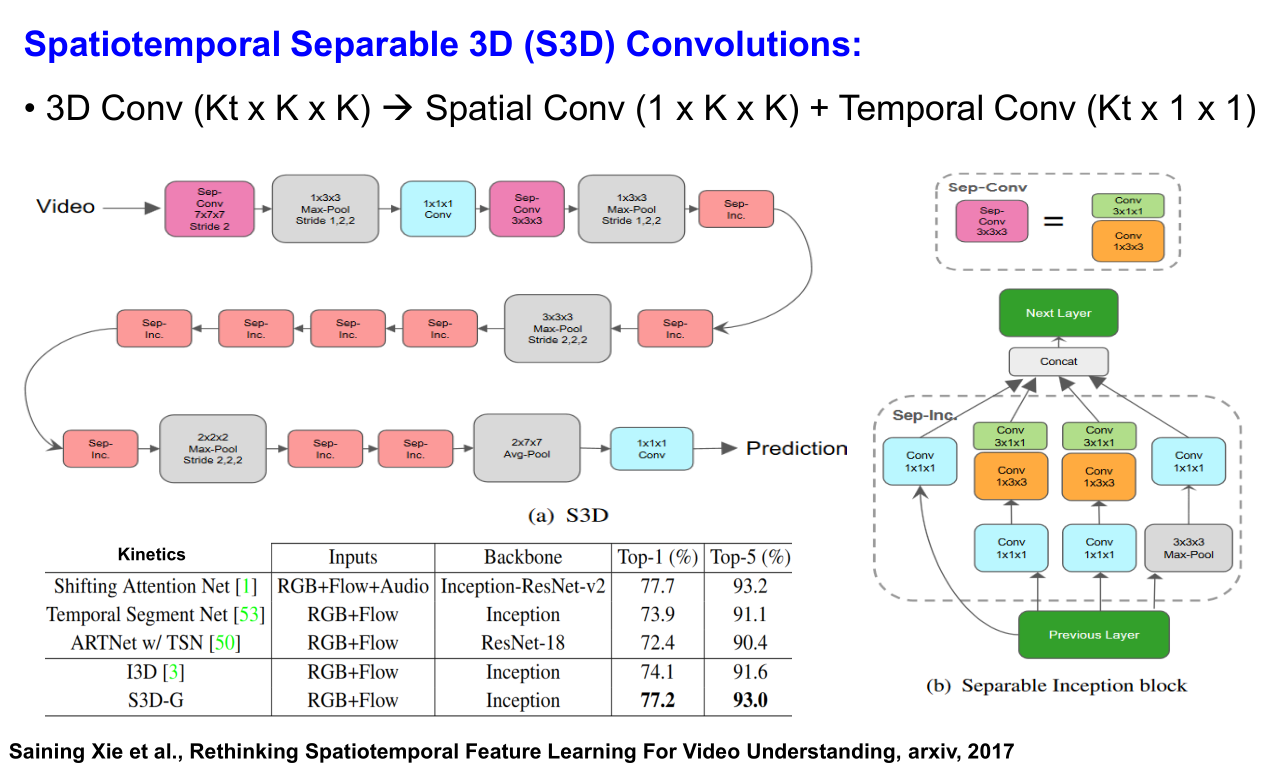
Spatiotemporal Separable 3D (S3D) Convolutions —— 3D分解模型
Saining Xie et al., Rethinking Spatiotemporal Feature Learning For Video Understanding, arxiv, 2017
3D卷积网络与2D卷积网络相比,始终存在着网络参数量太大而且计算效率不高的问题,但是3D卷积网络的准确率又明显好于2D卷积网络,所以为了解决这个问题,我们需要思考以下几个点:
- 3D卷积网络中是否需要全部都是3D卷积核?是否可以设计一个网络同时包含 2D卷积核和3D卷积核,来达到准确率与计算效率的 trade-off 呢?
- 是否可以通过分解3D卷积核为 2D+1D 卷积核的形式来解决这个问题呢?
设计了两种 2D+3D 的 I3D 网络。
R(2+1)D —— 3D分解模型
Tran, Du, et al. “A closer look at spatiotemporal convolutions for action recognition.” Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2018.
作者是FAIR的工作人员,其中包括 Du Tran(C3D) 作者,Heng Wang(iDT) 作者和 Yann LecCun 等。
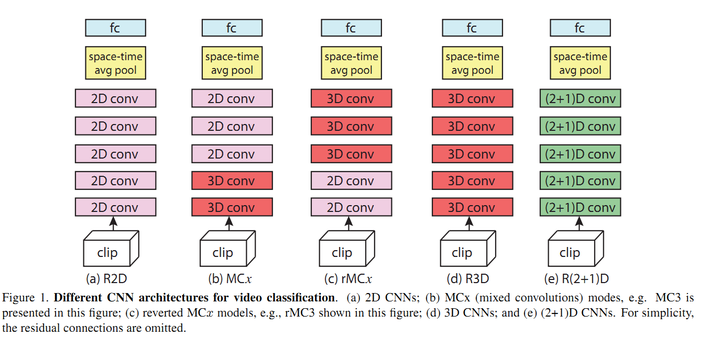
R 代表 ResNet, 即残差网络。
关于 R2D :
- 第一种将时间维度合并到 channel 维度中,比如将 C×T×H×W 的输入转变成 CT×H×W 的输入,然后直接输入到2D卷积网络中就可以得到最后的分类结果。这种方法称为R2D。
- 第二种方法不将时间维度和 channel 维度合并,而是使用参数共享的 2D 卷积网络得到输入视频中每一帧的分类结果,最后对所有帧的结果融合得到最终的结果,这种方法称为 f-R2D 的方法。
- 实验表明纯2D网络(包括R2D和f-R2D)比含3D的网络(包括R3D, MCx,rMCx, R(2+1)D)性能要差
关于 MC 和 rMC:
- 有一种观点认为卷积网络较低层对motion的建模比较好,而高层由于特征已经很抽象了,motion和时序信息建模是不需要的,因此作者提出了MCx网络,即将第x以及后面的3D卷积group换为2D的卷积group。注意此时MC1等效于f-R2D,即所有的层都是2D卷积。
- 同时还有一种假设认为高层的信息需要用3D卷积来建模,而底层的信息通过2D卷积就可以获取,因此作者提出了rMCx结构,前面的r代表reverse。rMCx表示前面的5-x层为2D卷积,后面的x层为3D卷积。
- 实验表明 MCx 性能优于 rMCr,因此说明在网络底层的3D卷积层更有用,而后面用2D卷积更合理。
关于 R(2+1)D:
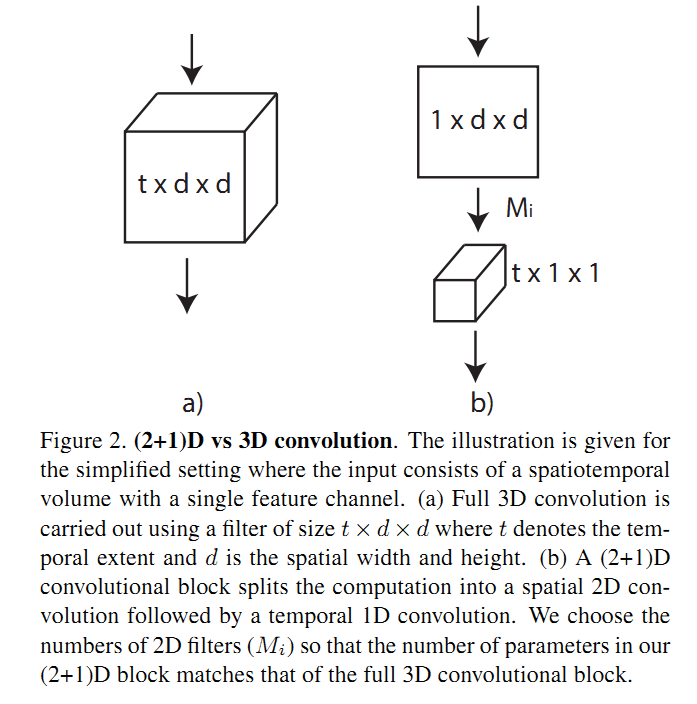
- 增加了非线性的层数,原先的1个卷积变成2个卷积,而2个卷积之间多了非线性层(通过ReLU来得到), 因此总体的非线性层增加了。用同样的参数来得到增加非线性的目的。
- 使得网络优化更容易,实验表明 R(2+1)D 的训练错误率比 R3D 更低,说明网络更易于训练。
消融实验结果
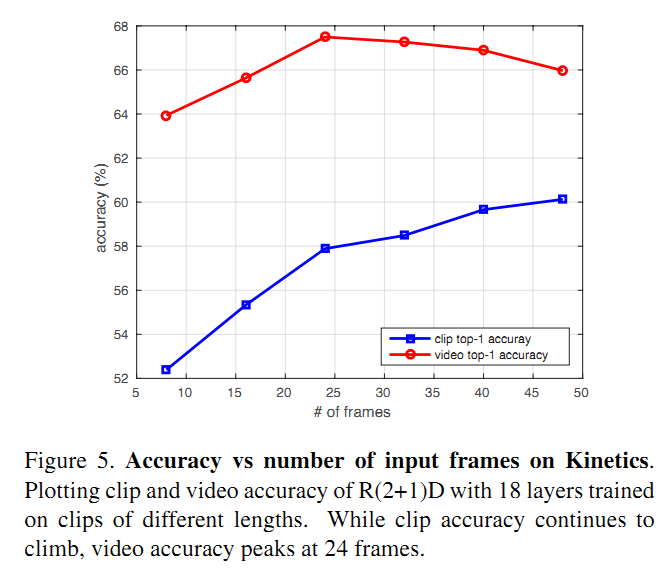
作者采用了8,16,24,32,40和48帧的clip进行实验,对clip-level的结果和video-level的结果进行分析,得到的准确率如Figure 5所示。可以看到,clip-level的准确率随着clip的长度增长在持续上升,而video-level的准确率则在24帧的时候达到最高,后面反倒有所下降,作者分析随着clip长度的增加,不同clip之间的相关性增加(甚至可能会产生重叠),所以video-level的准确率增益越来越小。 为了分析video-level准确率下降的原因,作者又做了两个实验:
- 采用8帧的clip训练网络,然后在32帧的的clip上测试,发现结果相比用8帧的clip做测试,clip-level的准确率下降2.6%
- 在8帧的clip上训练的网络的基础上,采用32帧的clip进行fine tune,得到的clip-level的准确率与32帧从头训练的结果相差不多(56.8% vs 58.5%),而比8帧的clip的clip-level结果高4.4%。因此用长的clip结果更高说明学到了long-term的时间域上的信息
作者采用了224x224的输入训练网路,发现和112x112的输入结果只有微小的差距。
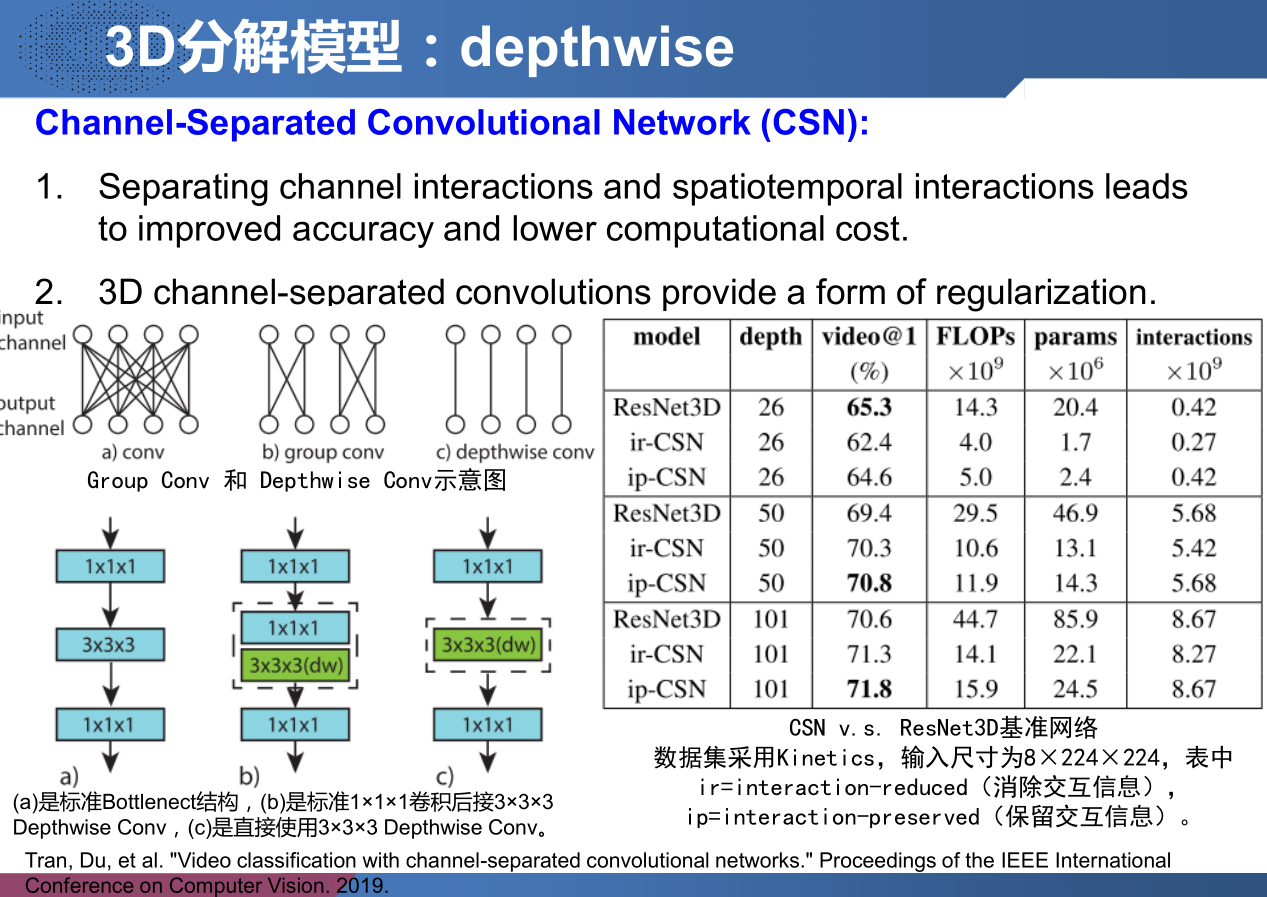
Channel-Separated Convolutional Network (CSN) —— 3D分解模型
Tran, Du, et al. “Video classification with channel-separated convolutional networks.” Proceedings of the IEEE International Conference on Computer Vision. 2019.
ARTNet —— 时空关系建模
Limin Wang et al., Appearance-and-Relation Networks for Video Classification, CVPR2018
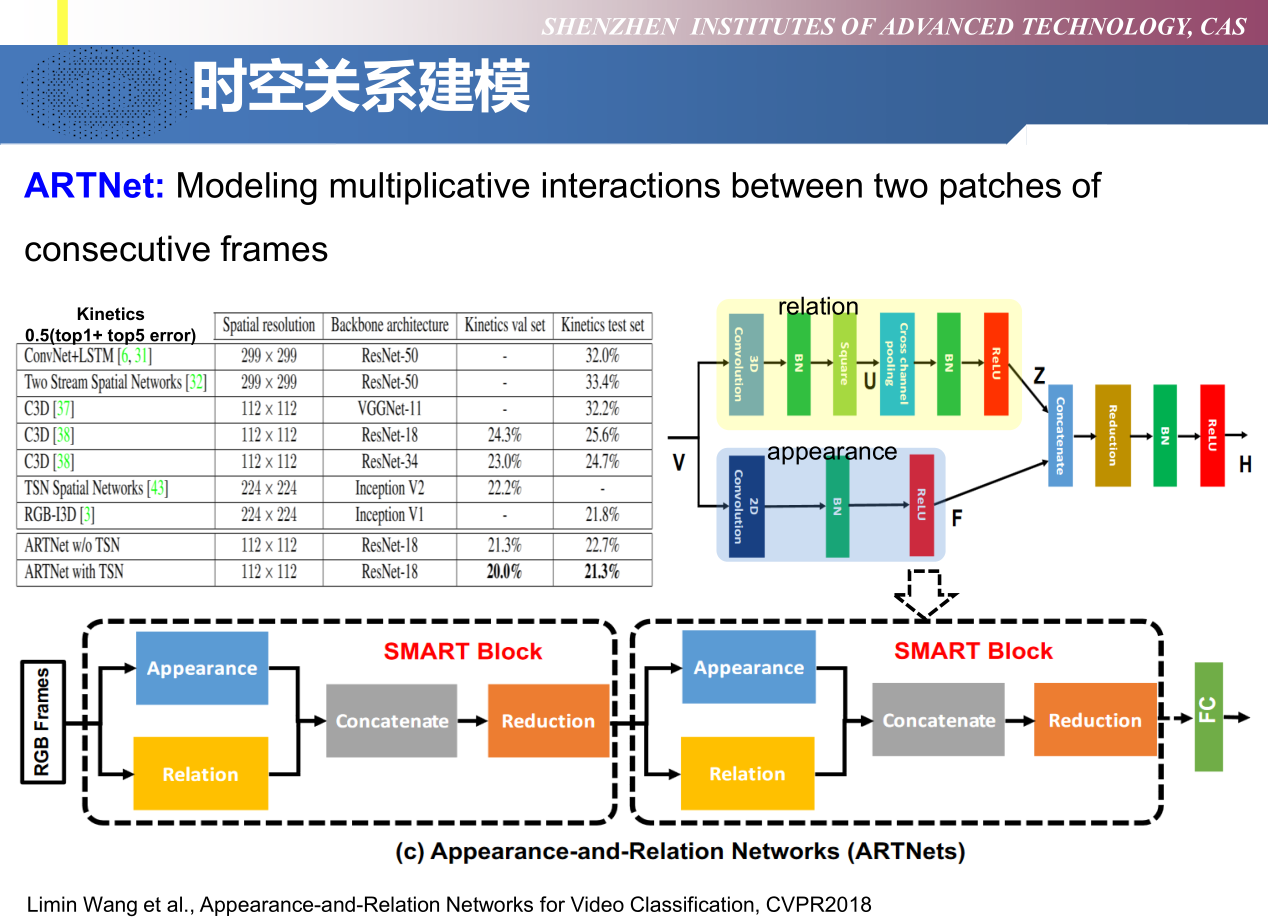
ARTNet是由多个名为SMART的block堆叠而成。SMART模块的目标是从RGB帧中分别学习到appearance和relation。它包含两个部分,appearance branch用于对spatial建模,relation branch用于对temporal建模。
- Appearance branch. 这个分支作用于单帧的图像上,即对输入的视频帧使用 2D conv 来捕获每一帧的 spatial 信息。然后后面接 BN 和 ReLU。
- Relation branch. 这个分支作用在 stacked连续帧 上,用于捕获帧与帧之间的关系。在paper中有讨论过对于Relation的建模用 multiplication interactions 比较合适(具体看原文),所以文章提出了 square-pooling 的结构用于建模 temporal 的信息。具体地,首先在视频上用 3D conv,然后做 square,再 cross-channel pooling。
Non-local —— 时空跨度依赖模型
Wang, Xiaolong, et al. “Non-local neural networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
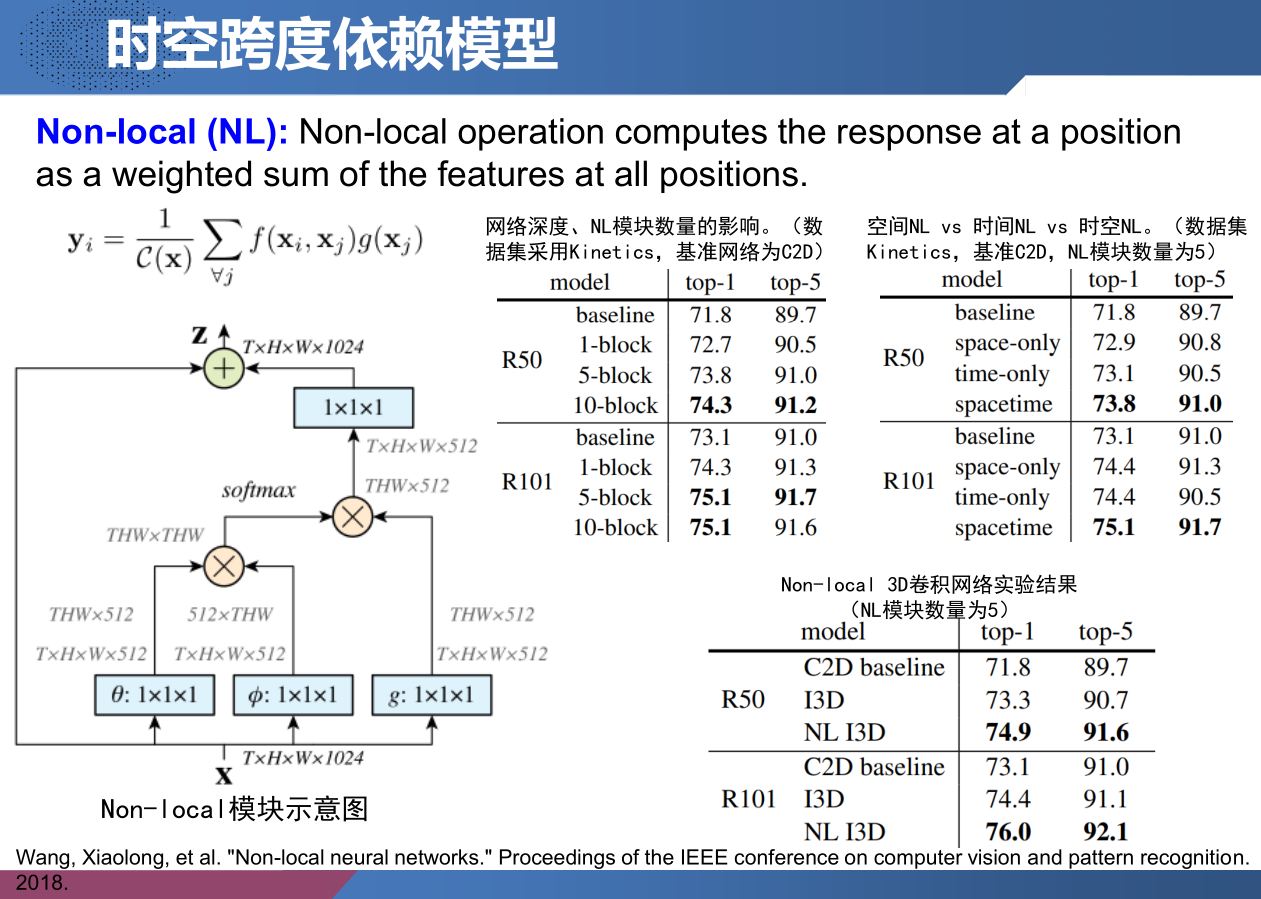
深层神经网络中,捕获远距离相关性是至关重要的:对于顺序数据(例如语音、语言),递归操作是建模远程依赖性的主要解决方案;对于图像数据,长距离依赖关系是由深层次的卷积运算所形成的大感受野来建模的。卷积操作和递归操作都会在空间或时间上处理一个局部邻域;因此,只有反复应用这些操作,逐步通过数据传播信号时,才能捕捉到长距离依赖关系。
但重复进行本地操作会有几个限制:首先,计算效率很低;其次,会造成优化方面的困难;最后,使得多跳跃的依赖性建模变得困难,例如,当需要在远程位置之间来回传递信息时。
在本文中,我们将非局部运算作为一种有效的、简单的、通用的部件来使深层神经网络捕获远距离依赖关系。我们提出的非局部运算是经典的非局部平均运算在计算机视觉中的推广,直观地说,非局部操作将某个位置的响应计算为输入特征映射中所有位置的特征的加权和。位置可以是在空间、时间或时空中,这意味着我们的操作适用于图像、序列和视频问题。
使用非局部操作有几个优点:
- 与循环和卷积操作的渐进行为相反,非本地操作通过直接计算任意两个位置之间的交互关系来捕获远程依赖性,不论它们的位置距离如何;
- 非局部操作效率很高,即使网络只有很少层也能取得最佳效果;
- 非局部操作输入大小是非固定的,可以很容易地与其他操作相结合(例如使用的卷积操作)。

SlowFast —— 多尺度融合模型
Feichtenhofer, Christoph, et al. “Slowfast networks for video recognition.” Proceedings of the IEEE International Conference on Computer Vision. 2019.
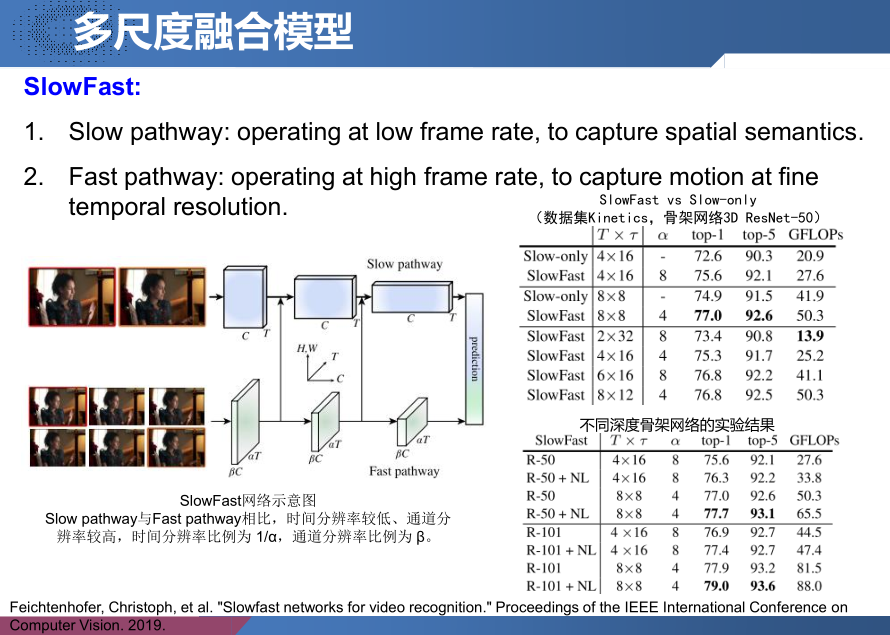
Slow pathway 的主要作用是做空间的语义处理,所以它的特点是分辨率高抽帧少(只关注图像特征),网络规模大(抽象语义特征)。Fast pathway 的主要作用是做时序的信息处理,所以它的特点是分辨率低抽帧多(考虑动作连续性),网络规模小(不需要获取复杂的特征)。
设计思想:
- 作者认为在以往对视频的处理中,大家都习惯性的认为视频处理是图像处理的自然延伸。在处理图像时,我们均衡的处理二维数据(x, y),毕竟x, y都是相同的图像属性。而在处理视频数据(x, y, t)时,t与(x, y)是不同属性, 所以我们不能简单的将它们均衡处理。
- 作者参考了生物学中关于视网膜神经细胞的研究,研究发现视网膜神经细胞中80%对空间和色彩信息敏感,20%对时序信息敏感。所以作者在设计SlowFast模型时,Slow网络规模占80%,Fast网络规模占20%。
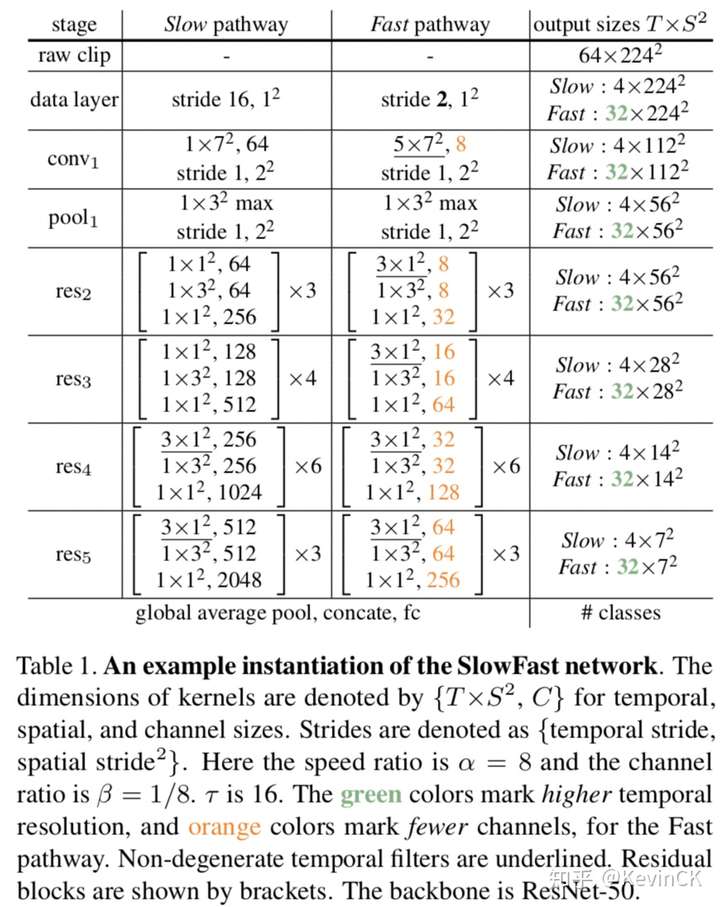
Slow 模型与 Fast 模型的拼接:
因为 Slow 输出为 {T, S^2, C},Fast 输出为{$\alpha$T, S^2, $\beta$C},两者无法直接融合。为此作者提出了三种reshape方式。两者输出匹配后可以通过拼接或(带权重)相加求和的方式进行融合。
- Time-to-channel: transpose {$\alpha$T, S^2, $\beta$C} to {T, S^2, $\alpha\beta$C}
- Time-strided sampling:从$\alpha$T中抽帧,每 $\alpha$ 帧中抽一帧,变为{T, S^2, $\beta$C}
- Time-stride convolution:通过3D卷积网络做reshape操作。


该方法甚至不需要预训练:

Temporal Shift Module (TSM) —— 面向3D任务的2D轻量化模型
Lin, Ji, Chuang Gan, and Song Han. “Tsm: Temporal shift module for efficient video understanding.” Proceedings of the IEEE International Conference on Computer Vision. 2019.

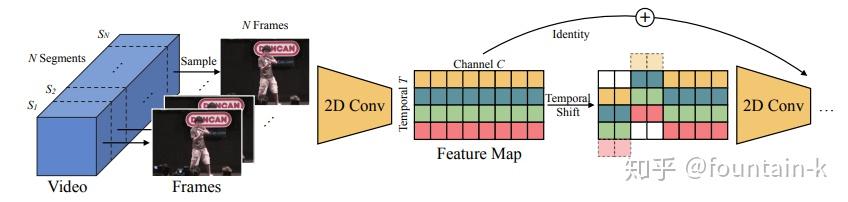
在推理阶段,对于每一帧,保存每个残差块的前1/8的特征图并缓存在寄存器中。对于下一帧,用缓存的特征图替换当前特征图的前1/8。即使用7/8的当前特征图和1/8的旧特征图组合来生成下一层并重复。使用单向TSM进行在线视频识别具有几个独特的优势:
- 低延迟推断。 对于每个帧,我们只需要替换和缓存1/8的特征,而不需要进行任何额外的计算。 因此,给出全帧预测的延迟几乎与2D CNN基线相同。 像ECO这样的现有方法使用多帧来给出一个预测,这可能在在线预测期间引入大的延迟。
- 内存消耗低。 由于我们只缓存了内存中的一小部分功能,因此内存消耗很低。 对于ResNet-50,我们只需要3.8MB内存缓存来存储中间功能。
- 多级时间融合。 大多数在线方法像TRN或中级时间融合ECO等特征提取后实现晚期时间融合,而我们的TSM能够实现所有级别的时间融合。 通过实验我们发现多级时间融合对于复杂的时间建模非常重要。
与
这两种方法我们必须要注意到一个事情,作者原文中也说到,循环的方式会打乱时序上的先后关系,所以在对时序上要求比较高的数据集,其效果不及
方法。
研究目的:
既然卷积操作包括了shift和multiply-accumulate, 所以考虑在时间维度上也进行相应的操作看看效果咋样。文章提到的这种shift的方法在spatial中也有用到过,但是通常会面临两个问题:
- 并不高效,尽管shift操作是基本zero FLOP的,但是这也同时会导致数据移动,这一步会产生延迟,而且尤其在视频文件中,该现象会更加显著,因为视频是5个维度的;
- 并不准确,如果shifting太多的channels的话将会损坏原有帧的空间,也就是移动了,那么就不完整了,并不包含所有的该张图片本身应该具有的信息
上面两个问题的解决:
- 改进的shifts策略:并不是shift所有的channels,而是只选择性的shift其中的一部分,该策略能够有效的减少数据移动所带来的时间复杂度;
- TSM并不是直接被插入到从前往后的干道中的,而是以旁路的形式进行,如下图(b),因此在获得了时序信息的同时不会对二维卷积的空间信息进行损害!

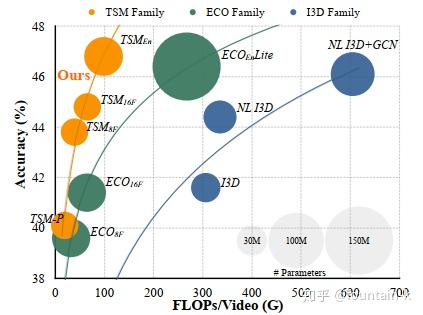
实验结果:
SmallBigNet —— 演讲者的工作
Xianhang Li , Yali Wang, Zhipeng Zhou, Yu Qiao SmallBigNet: Integrating Core and Contextual Views for Video Classification,CVPR 2020
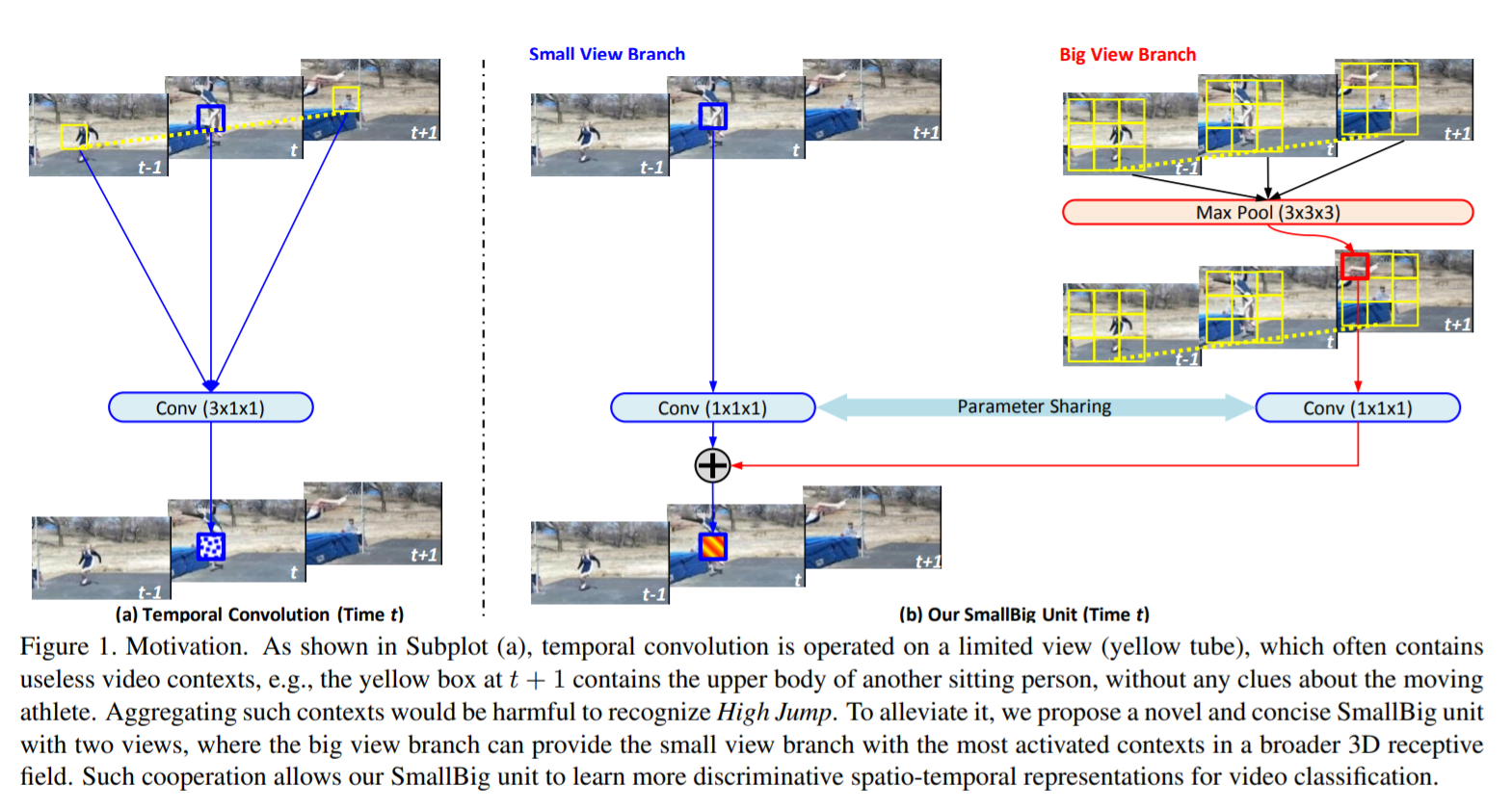
Temporal convolution has been widely used for video classification. However, it is performed on spatio-temporal contexts in a limited view, which often weakens its capacity of learning video representation. To alleviate this problem, we propose a concise and novel SmallBig network, with the cooperation of small and big views. For the current time step, the small view branch is used to learn the core semantics, while the big view branch is used to capture the contextual semantics. Unlike raditional temporal convolution, the big view branch can provide the small view branch with the most activated video features from a broader 3D receptive field. Via aggregating such big view contexts, the small view branch can learn more robust and discriminative spatio-temporal representations for video classification. Furthermore, we propose to share convolution in the small and big view branch, which improves model compactness as well as alleviates overfitting. As a result, our SmallBigNet achieves a comparable model size like 2D CNNs, while boosting accuracy like 3D CNNs. We conduct extensive experiments on the large-scale video benchmarks, e.g., Kinetics400, Something-Something V1 and V2. Our SmallBig network outperforms a number of recent state-of-the-art approaches, in terms of accuracy and/or efficiency. The codes and models will be available on https://github.com/xhl-video/SmallBigNet.
文档信息
- 本文作者:Mengqi Cao
- 本文链接:https://rogercmq.github.io//2020/06/19/%E8%AE%B2%E5%BA%A7%E7%AC%94%E8%AE%B0-VALSE-Action-Recognition(3)/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)