2020-06-23-讲座笔记-VALSE Network Compression
VALSE Webinar 2020-14 期
VALSE: http://valser.org/article-368-1.html
录播地址:https://www.bilibili.com/video/av710990098/
AI on the Edge —— 王云鹤(华为诺亚)讲座摘录
压缩比≠加速比:Compressed networks can achieve the same performance compared to original baselines after fine-tuning. Cannot directly obtain a considerable speed-up on mainstream hardwares.
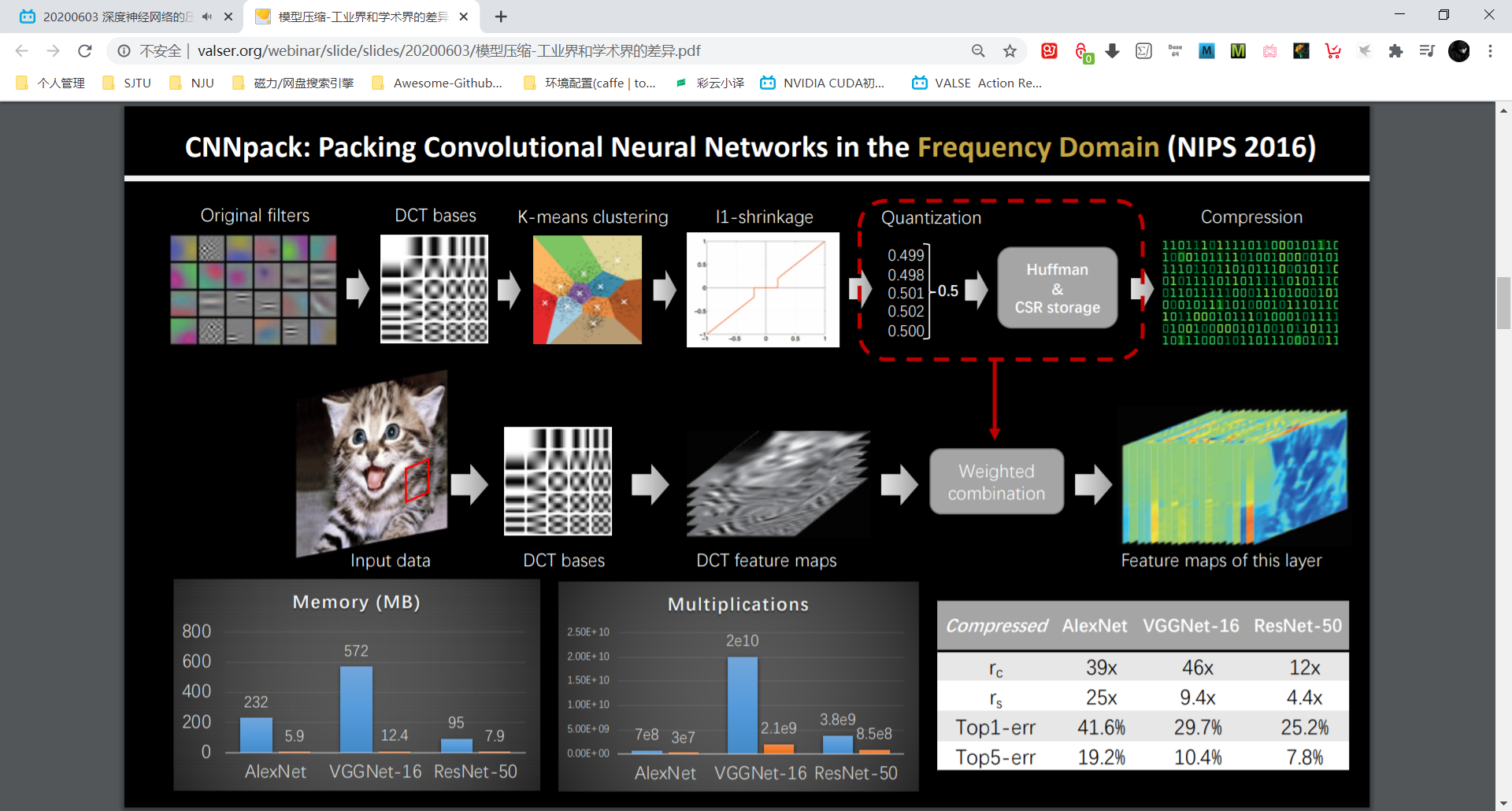
DCT-based 方法的问题:工业上用不了。
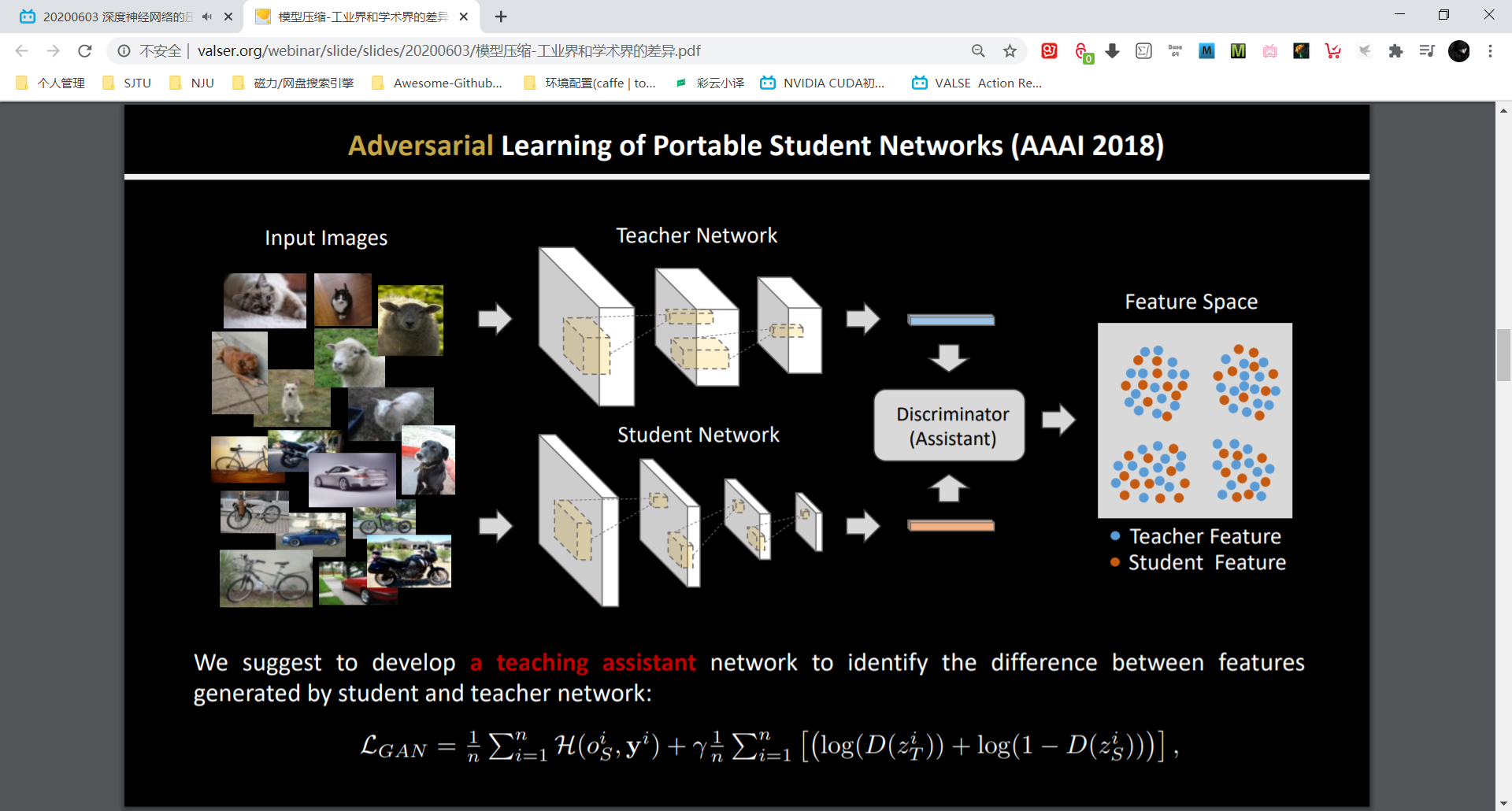
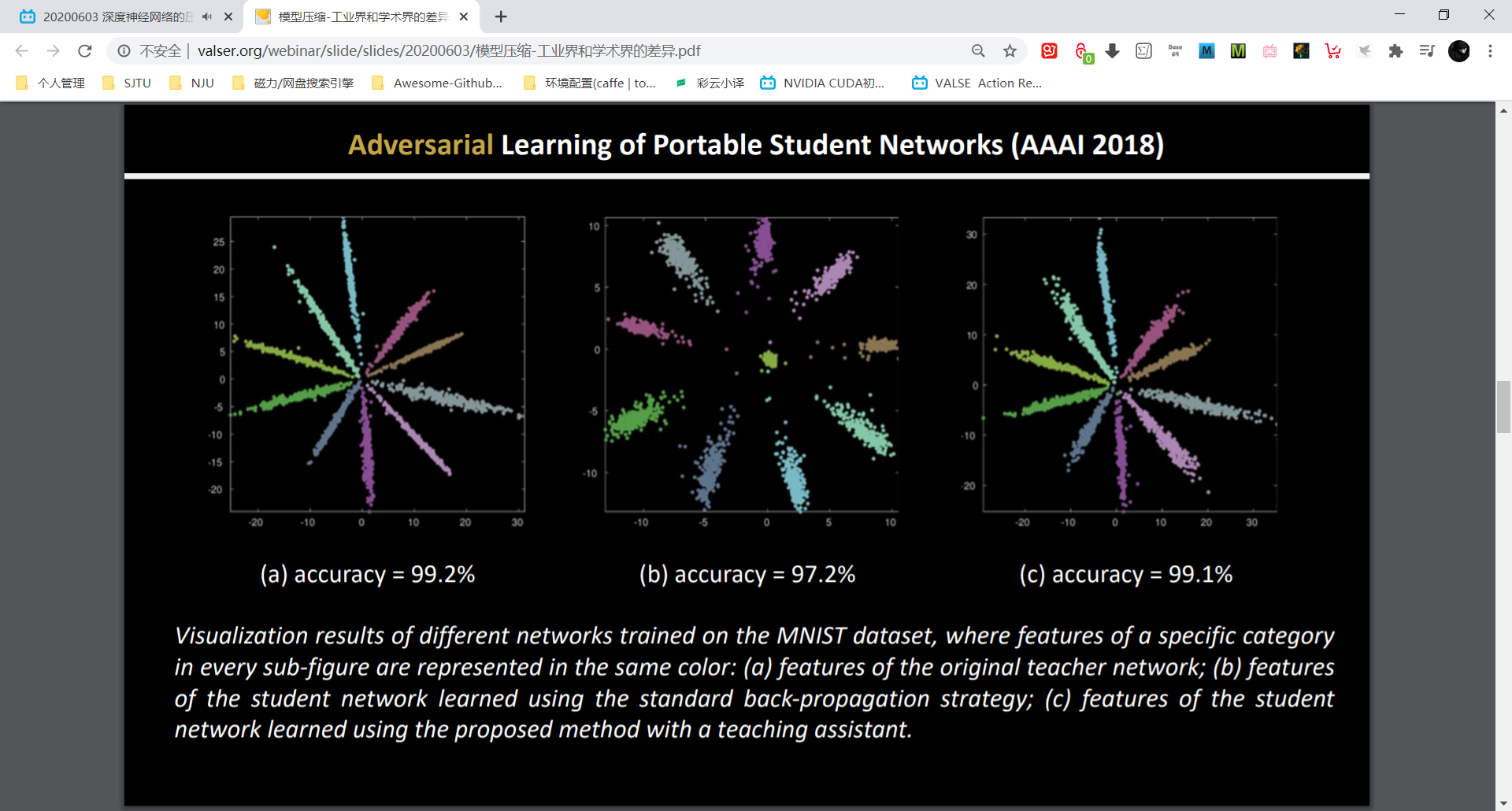
同时输入到 teacher net 和 student net,把中间特征输入到判别器网络里。
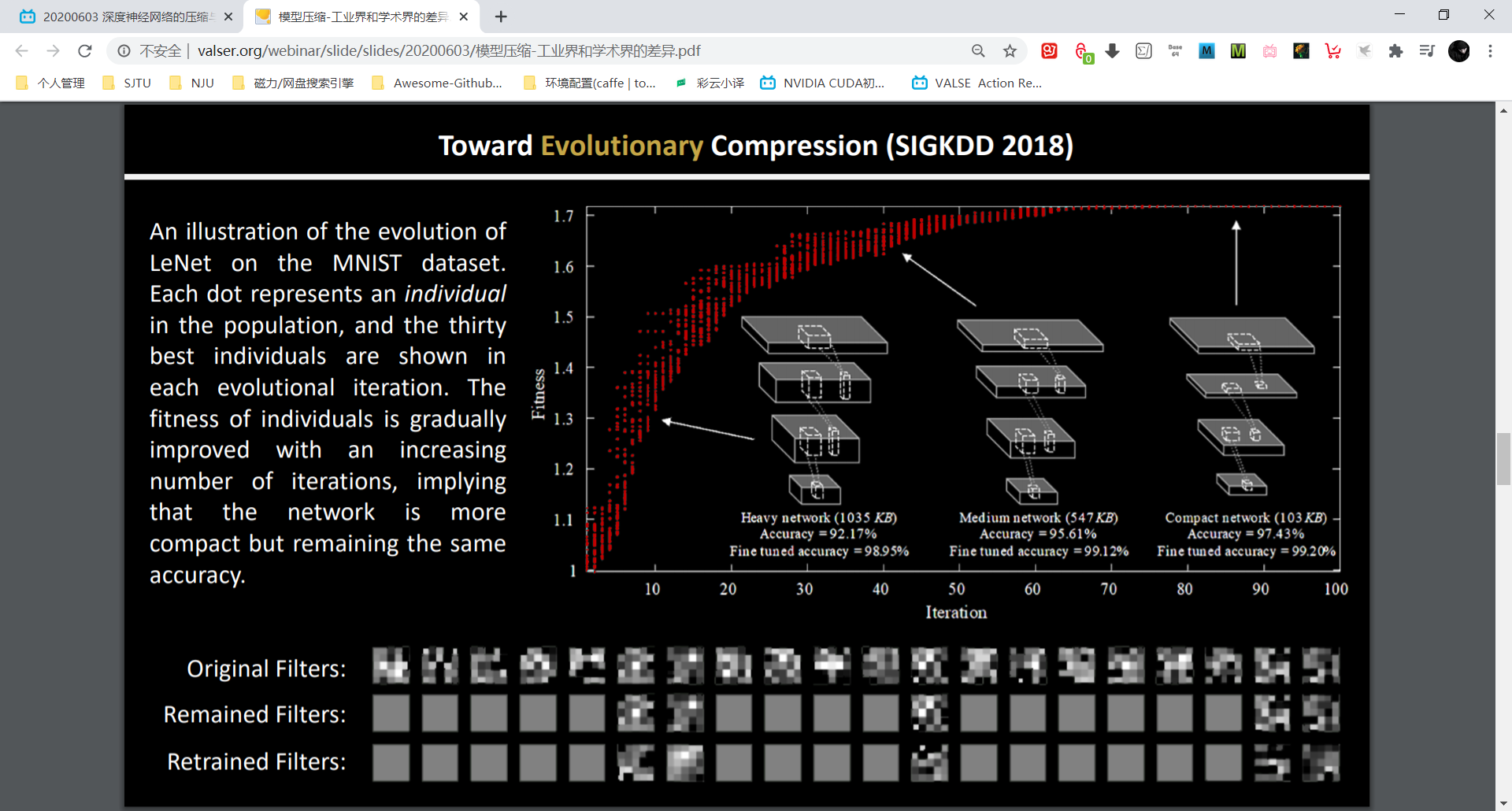
TEC: 利用遗传算法对神经网络进行裁剪,对神经元(filter)01编码,提出了 fitness 的概念
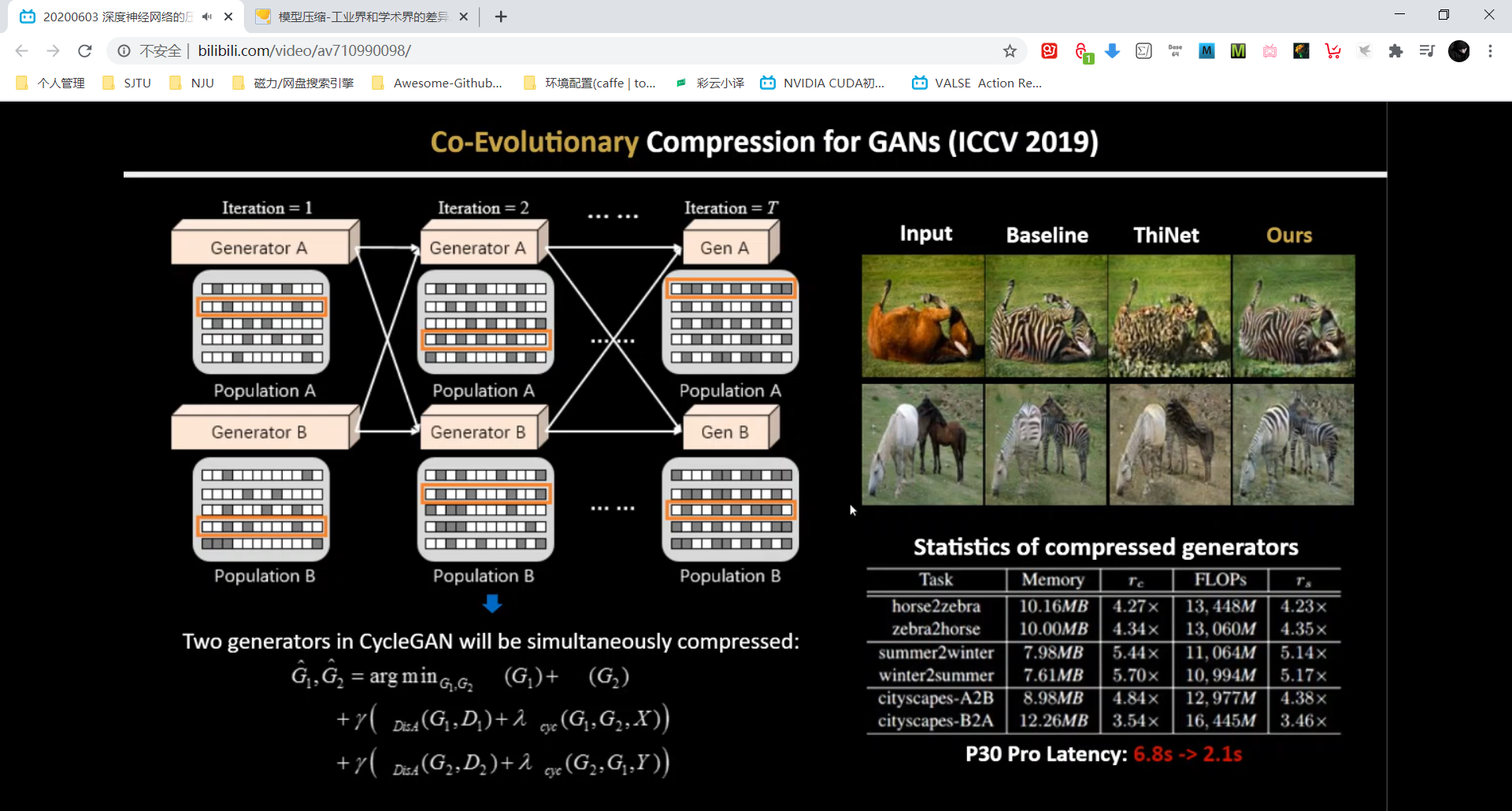
CCG: 对GAN网络进行模型压缩(生成神经网络计算量更大,因为输入与输出size相同),具体做法:生成了两个种群。
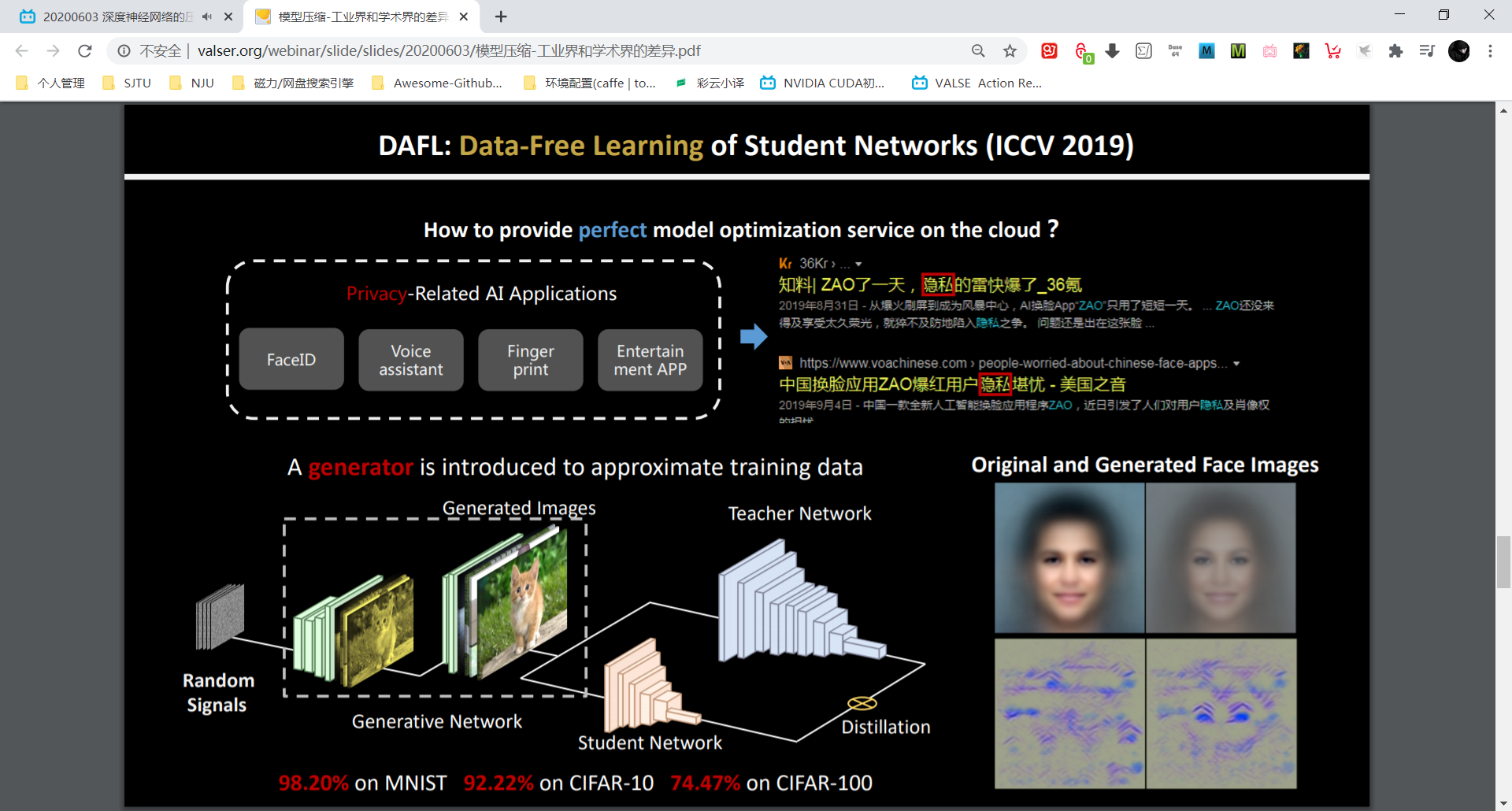
DAFL: data-free pruning technique。
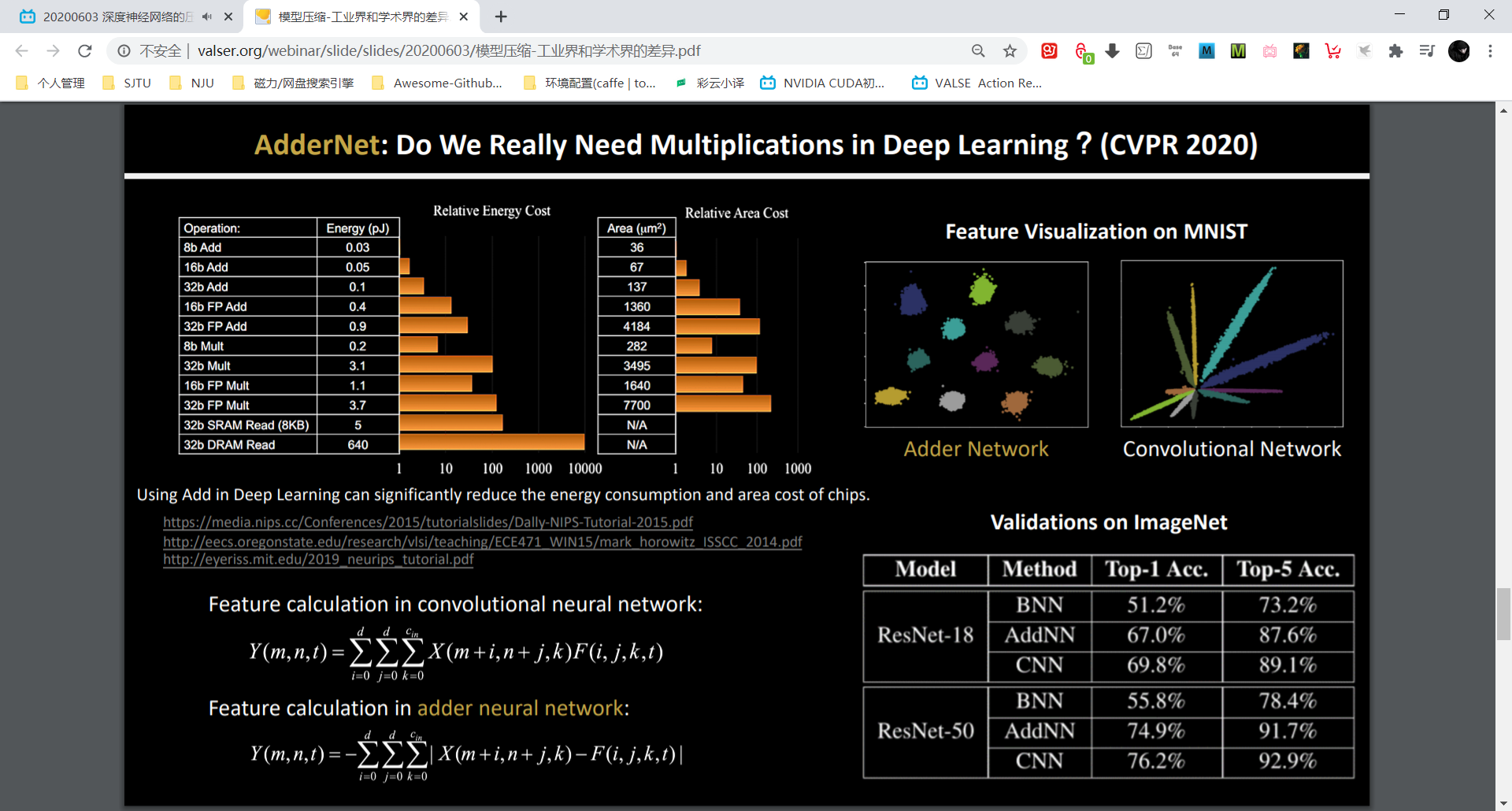
AdderNet: ResNet50 可达到 top-1 76% 的准确率。
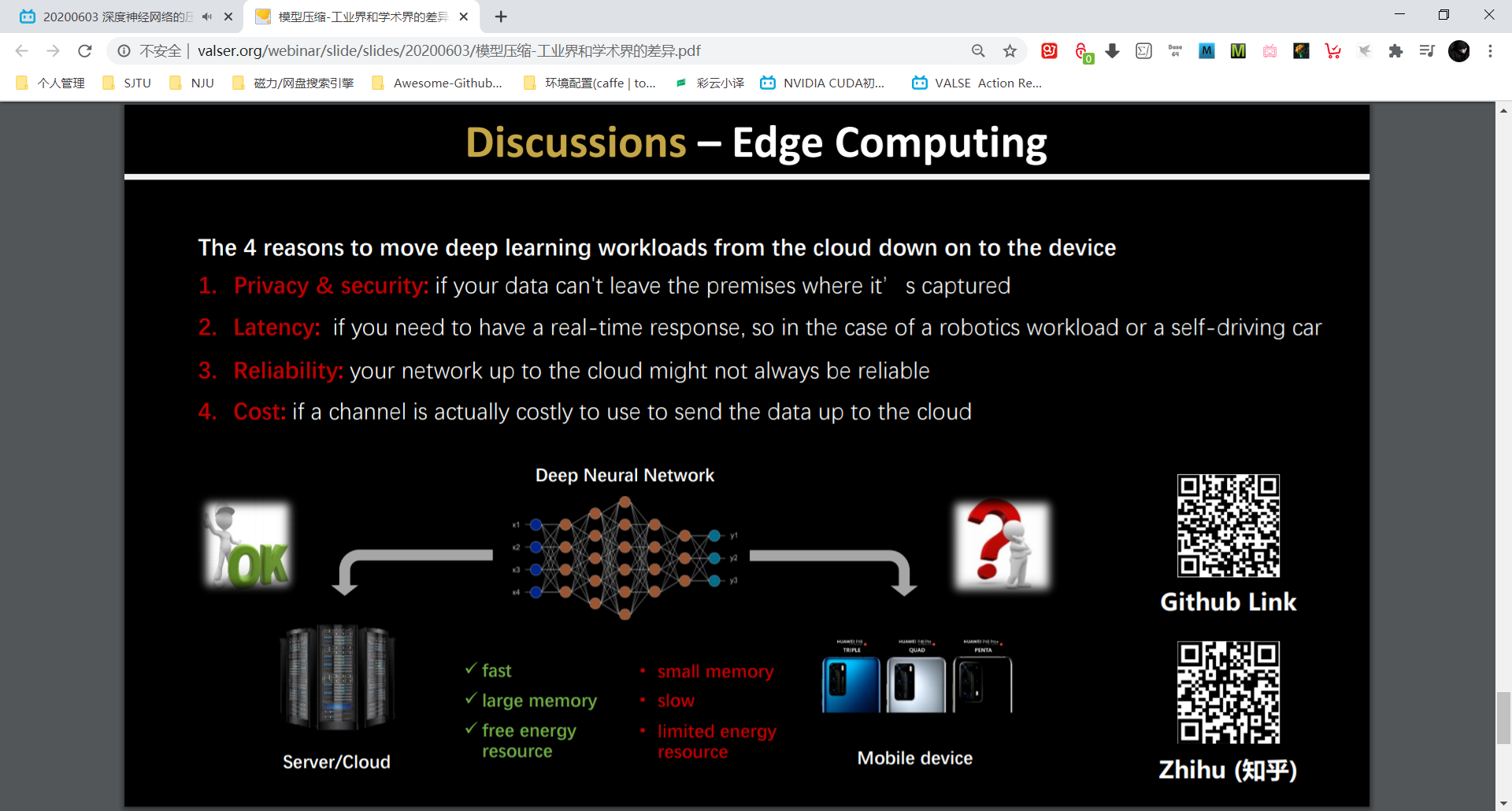
端侧 AI 必要性:地下车库,偏远地区。
Ultra-low-bit Neural Network Quantization —— 王培松(中科院自动化所)讲座摘录
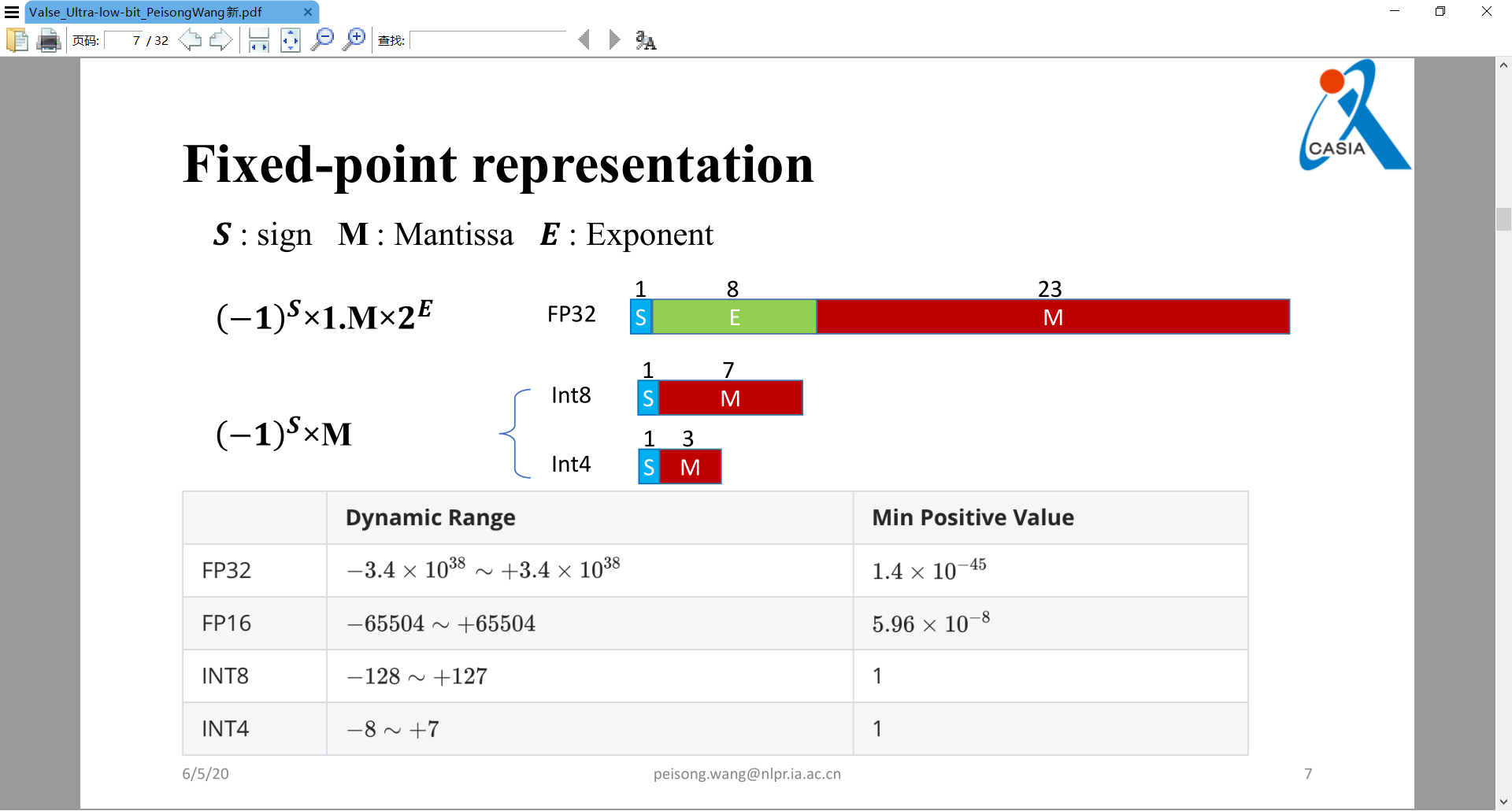
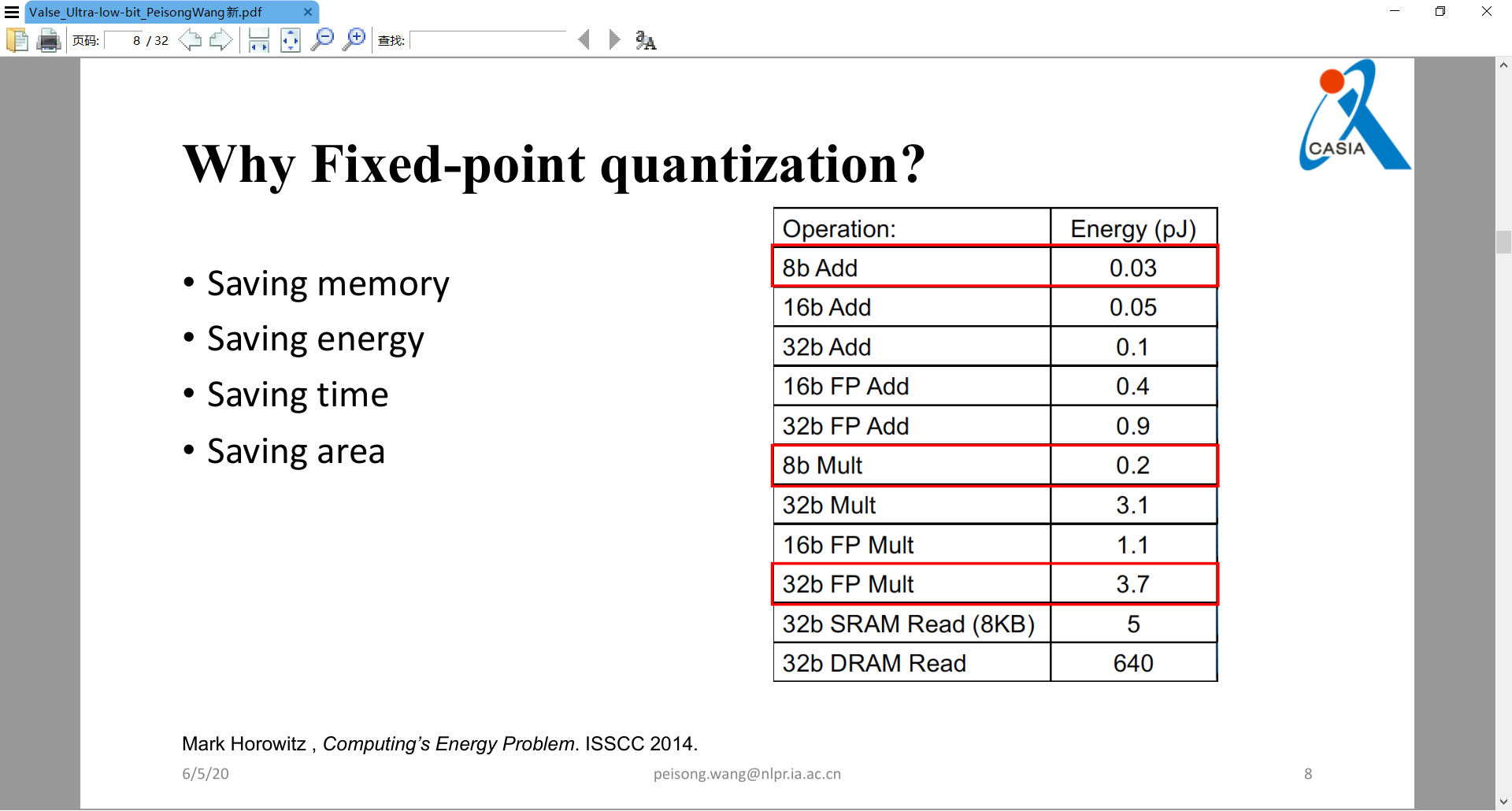
主要是讲定点量化的工作。定点数硬件友好,因此可提速并节省芯片面积。
Sparsity-inducing Binarized Neural Networks. AAAI, 2020
将激活量化为01,权重依然为±1。可以通过位运算进行加速。
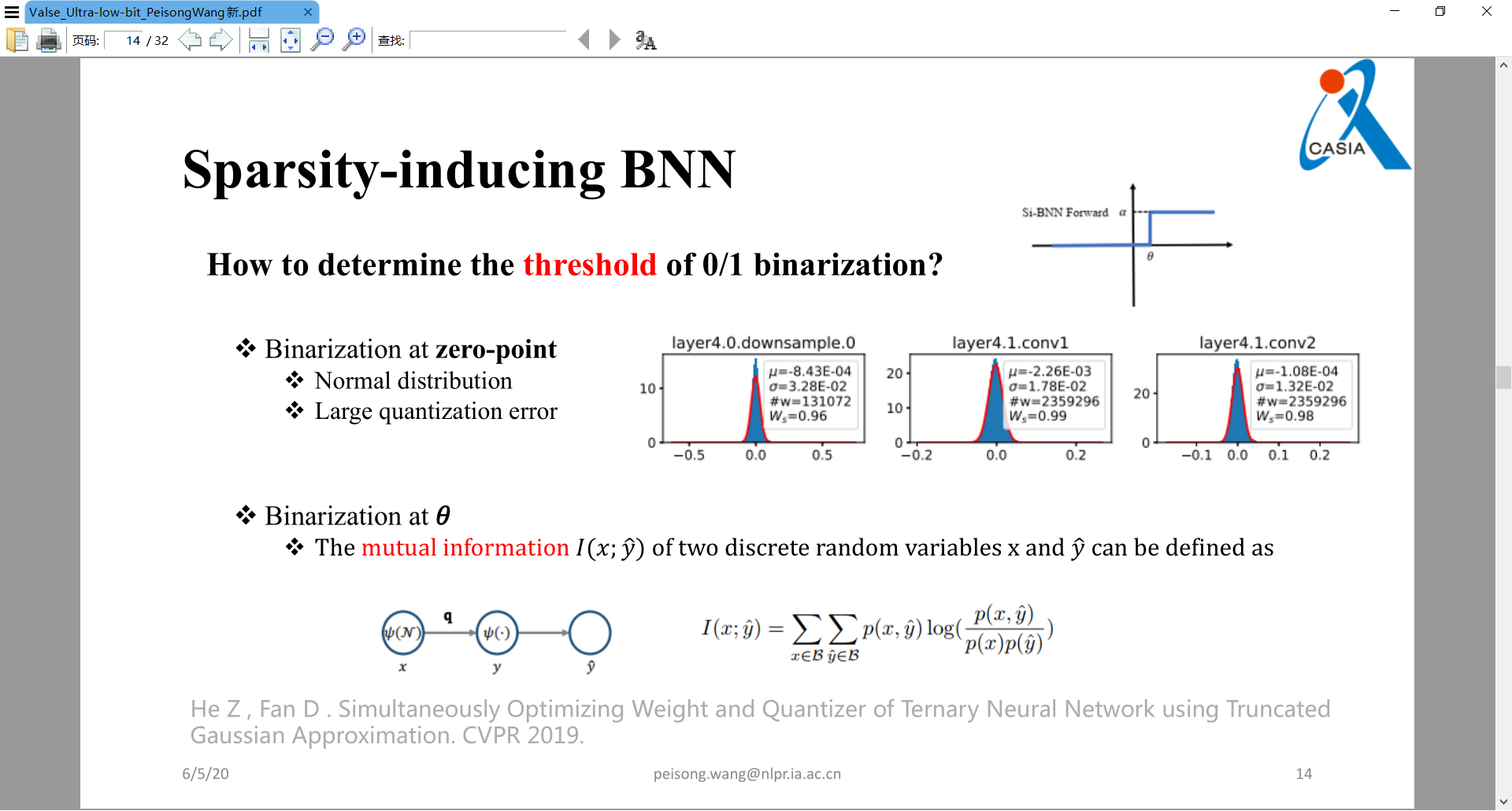
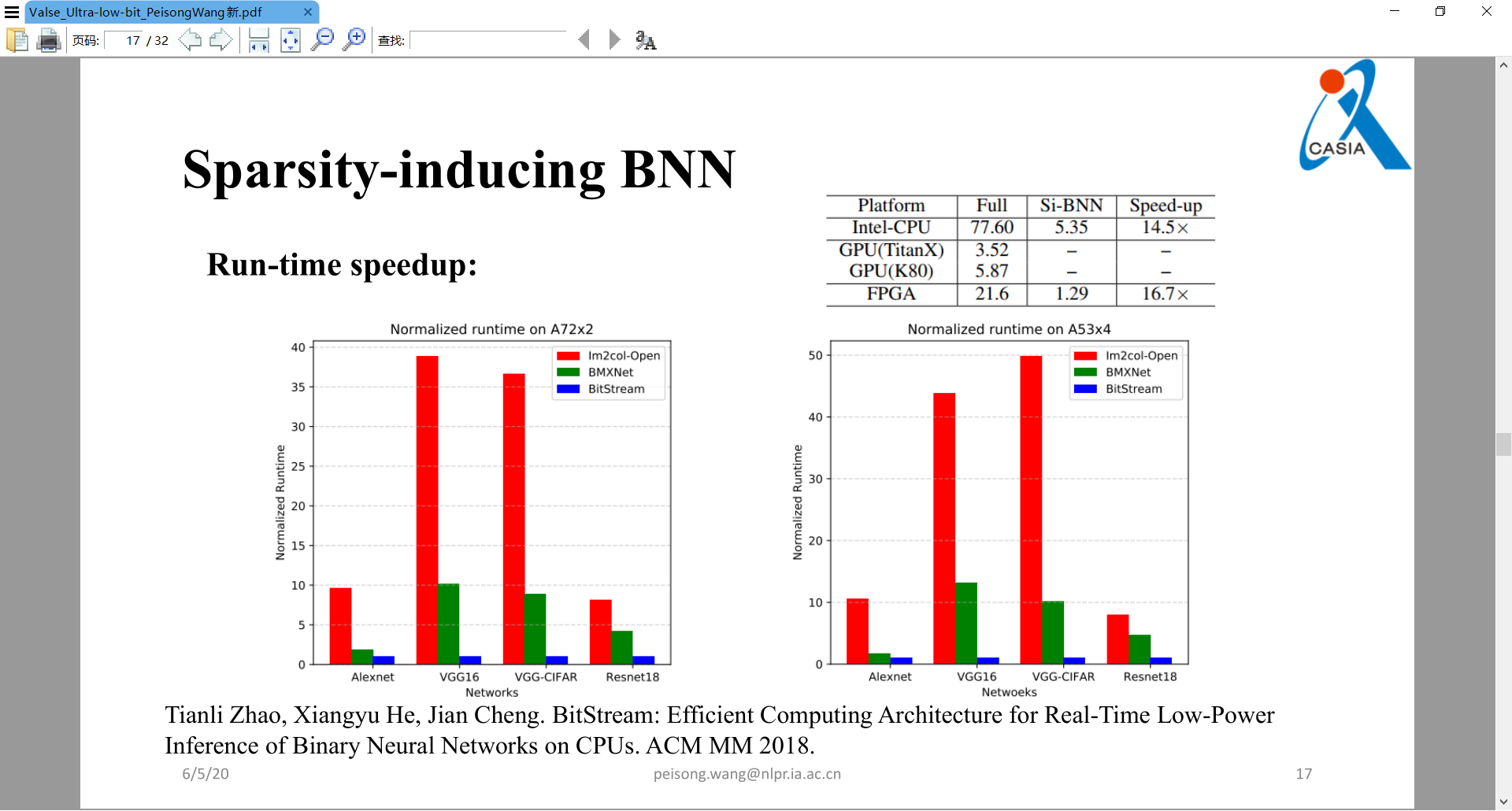
±1量化可以以0作为阈值点,但是01量化就不可,于是引入了互信息去找到阈值点theta。下图为实验结果,实际硬件加速非常明显:
Soft Threshold Ternary Networks. IJCAI, 2020
两个binary加起来可以得到一个ternary,所以变成了量化两个binary kernel。

Hardware Acceleration of CNN with One-Hot Quantization of Weights and Activations. DATE 2020
Towards Accurate Post-training Network Quantization via Bit-Split and Stitching. ICML, 2020
Panel 笔记
https://mp.weixin.qq.com/s/EZFjwqM5YEss61dw8MtdSw
议题1 —— 机器学习平台是公有云中增长最快的服务之一。是否有必要考虑将网络压缩算法集成为在线的机器学习服务,其中有哪些挑战与机遇?
模型压缩的计算成本与时间成本
- 非视觉应用场景
- data-free,privacy
议题2 —— 大多数网络压缩算法在GPU集群上进行训练学习,其压缩后的神经网络,如何 “无缝” 部署到其他“低功耗”设备上,如手机上的NPU、IoT设备上的单片机、FPGA等?
- 云端训练时目标函数优化时添加边缘端(资源受限的)信息
- 剪枝、蒸馏不好在低功耗设备上部署
### 议题3 —— 近年ICLR CVPR ICCV论文中,有指出压缩网络受网络结构影响,跟使用pretrained参数并没有很大关系,使用随机初始化也能达到好的效果。这是否意味着结构的重要性远远大于参数初始化?
- 持保留意见,可能预训练 baseline 模型不够好。而且在超分辨和 GAN 任务上,保留预训练参数依然很重要。
议题4 —— 我们可以通过NAS(Neural Architecture Search)技术搜索的到一个体积小并且性能不错的神经网络模型,那么进行网络压缩技术研究的意义在哪里?
- 评论里有问工业界现在用NAS的比较多还是网络压缩技术的比较多。从我观察的角度来看,现在应该还是用网络压缩技术比较多,因为毕竟有更长的历史。NAS相对来说比较新,还有一点非常重要的是,NAS现在所展示的一些应用,目前来看还是非常有限的,比如在视觉上,分类上,检测上,NAS是不是能在以RNN为基础的神经网络或者是LSTM相关的,还是很有待去验证的一件事情。所以目前来看,压缩技术用的稍微更多。
- 在很多的实际应用里面,我们会先用NAS去找一个大概的框架,在 NAS 找到大概的框架的情况下,之后我们还是要去做 filter pruning,去识别NAS出来的模型里面哪些的 channel 是没有必要的,通过这样的技术,两个结合的话,我觉得会产生一个更好的结果。
议题5 —— 遵循“没有免费午餐”定理,应根据实际问题选择合适的方法。对于具体的计算机视觉应用场景而言,如何针对性的进行网络压缩?
- 对于不同的视觉任务来说,有一点也是比较重要的,首先要寻找瓶颈是在哪个地方,是在于memory太大,计算量太大,还是模型存储太大。比如我们之前在做实际任务的时候,遇到一个问题,做超分的时候,计算量、模型的存储其实都是OK的,但是memory占用很大。这样的话,对于计算量和模型存储都不是问题,但是对于memory占用就很是问题。所以首先要找到这个瓶颈到底是在哪个地方,再去针对地做不同的压缩方案。但是如果知道了这个瓶颈在哪里,怎么去解决这个问题,就很难给出指导性的建议了,可能更多地靠尝试,或是一些经验性的东西。
文档信息
- 本文作者:Mengqi Cao
- 本文链接:https://rogercmq.github.io//2020/06/23/%E8%AE%B2%E5%BA%A7%E7%AC%94%E8%AE%B0-VALSE-Network-Compression/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)