本节内容:为什么需要GPU?三种方法提升GPU的处理速度?实际GPU设计举例(GTX480 Fermi & GTX680 Kepler)?GPU的存储器设计?
名词解释:
- FLOPS: Floating-point Operations per Second
- GFLOPS, TFLOPS
GPU是一个异构(heterogeneous)的多处理器(multi-processor)芯片,为图形图像处理优化。
执行单元(execute shader):Fetch/Decode,ALU,Execution Context。GPU 是一种“CPU-style Cores”,但与 CPU 不同的是 CPU 核具有巨大的 data cache,以及 out-of-order control logic,fancy branch predictor,memory pre-fetcher —— 这些部分占用了CPU大部分芯片面积。
三种提升GPU的处理速度
- slimming down:remove components that help a single instruction stream run fast. 精简之后剩余的面积可以多放N个核(同时执行 N 个程序片元 aka fragments)
- N个程序片元共享指令流(否则需要设计复杂的控制结构)
- 增加单个核内 ALU 数,SIMD 处理更多的数据
- modify the shader(e.g. precesses N fragments using vector ops on vector registers 但不改变指令执行逻辑)

分支处理:worst case 1/N peak performance,并不是所有的 ALU 在做有用的工作。
SIMD 处理方法:
- 显示的向量运算指令
- SSE 等
- 隐式的标量指令,但是硬件进行矢量化
- 硬件进行指令流共享
- NVIDIA 等架构
- 多个片元共享指令流
- 大量的独立片元相互切换,通过片元切换来掩藏延迟。
- 上下文存储池 pool of context storage
- small contexts == maximal latency hiding,占满等待时间,从而掩藏延迟
- 上下文切换(interleaving between contexts)可以软件也可以硬件管理,不同的体系结构设计时采用了不同的策略。
- 上下文存储池 pool of context storage
Fermi 架构细节
Kepler 架构也差不多,在课程中只是介绍了一下各自的参数,没有具体的知识点
- NVIDIA GeForce GTX 480
- SIMT execution
- 15 cores; 2 groups of 16 SIMD functional units per core
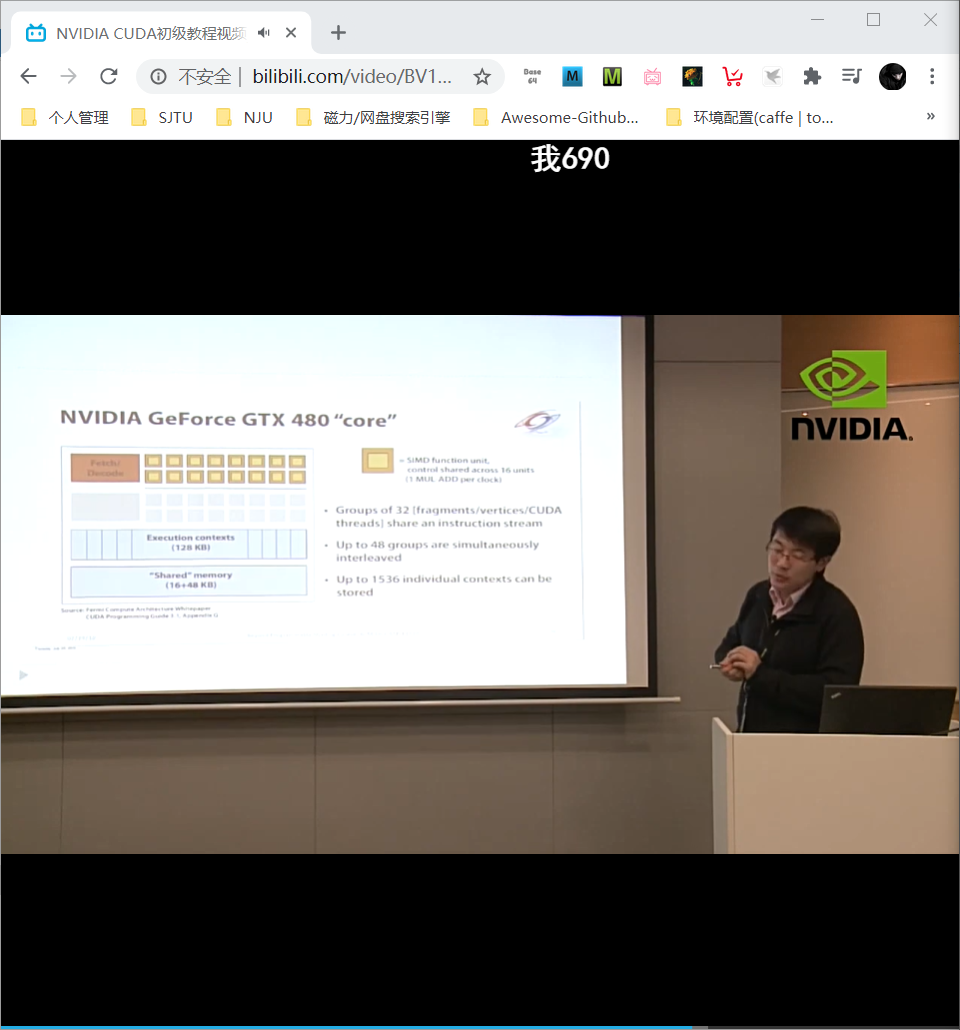
图中的 CUDA 核: 相当于一个复杂的 ALU
GPU 的存储和数据访问
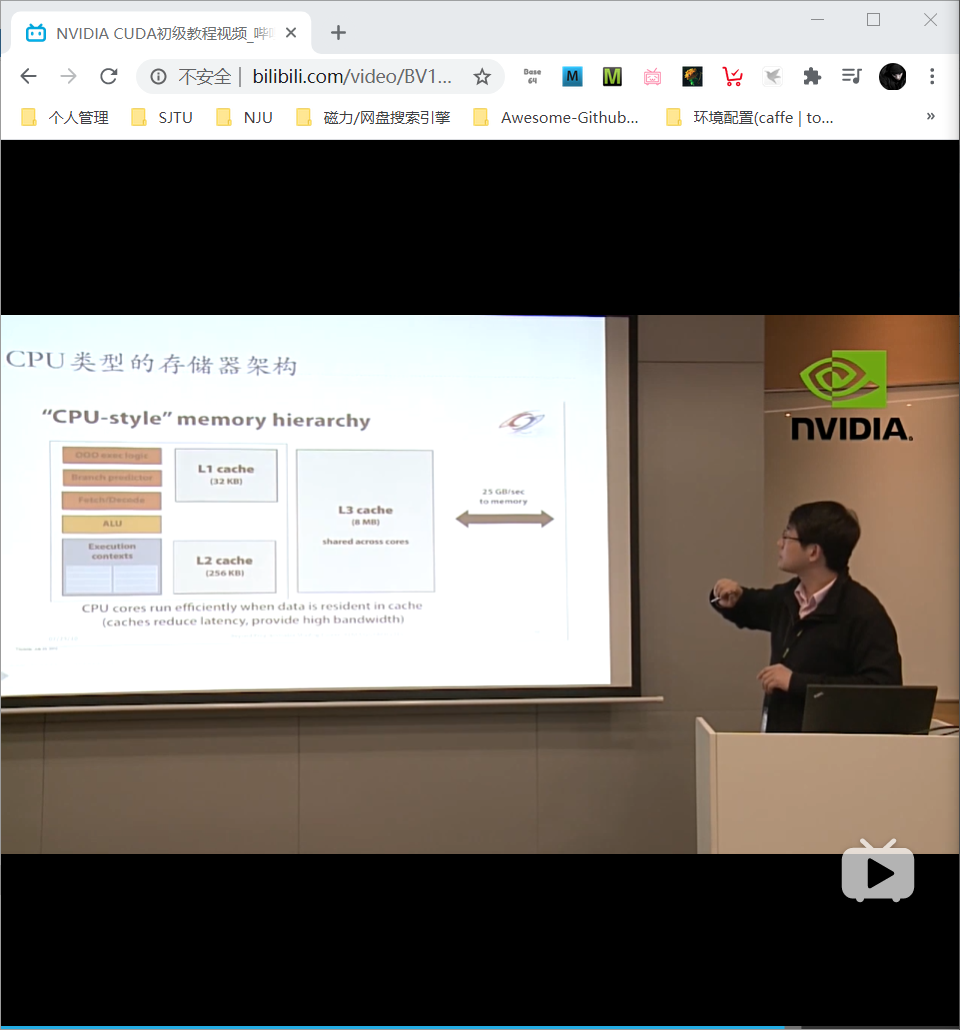
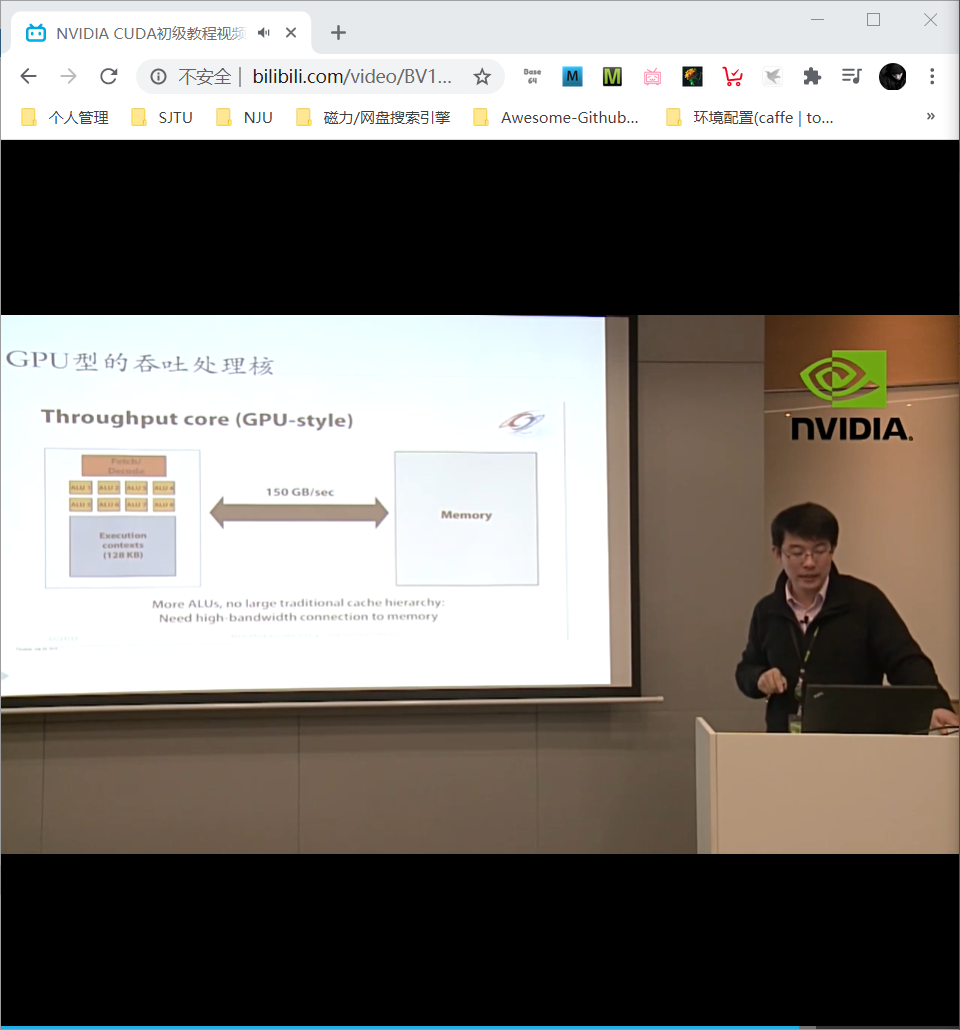
CPU 访存通过各级cache,而GPU是 throughput core 直接面对显存memory。
带宽 bandwidth 很重要:
- wide bus (150GB/sec)
- repack/reorder/interleave memory requests to maximize use of memory bus
- still, this is only six times the bandwidth available to CPU
如何减少带宽需求:
- request data less often (instead, do more math)
- fetch data from memory less often (share/reuse data across fragments)
- on-chip communication or storage
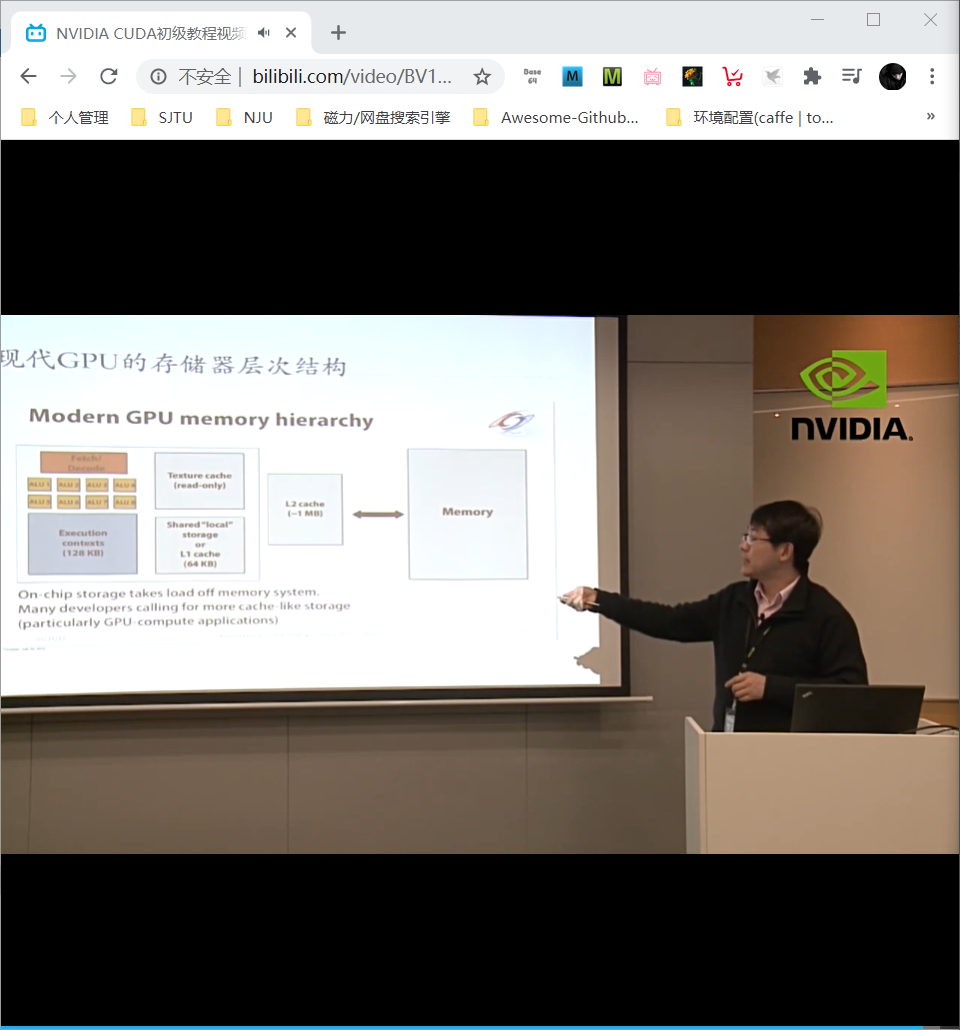
GPU 是异构多核处理器,针对吞吐优化。上图很重要!
文档信息
- 本文作者:Mengqi Cao
- 本文链接:https://rogercmq.github.io//2020/06/23/CUDA-Day-3-GPU%E4%BD%93%E7%B3%BB%E7%BB%93%E6%9E%84%E6%A6%82%E8%BF%B0/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)