本节内容:CPU与GPU互动模式,GPU线程组织模型(不停强化),GPU存储模型,基本的编程问题。
CPU/GPU 互动模式
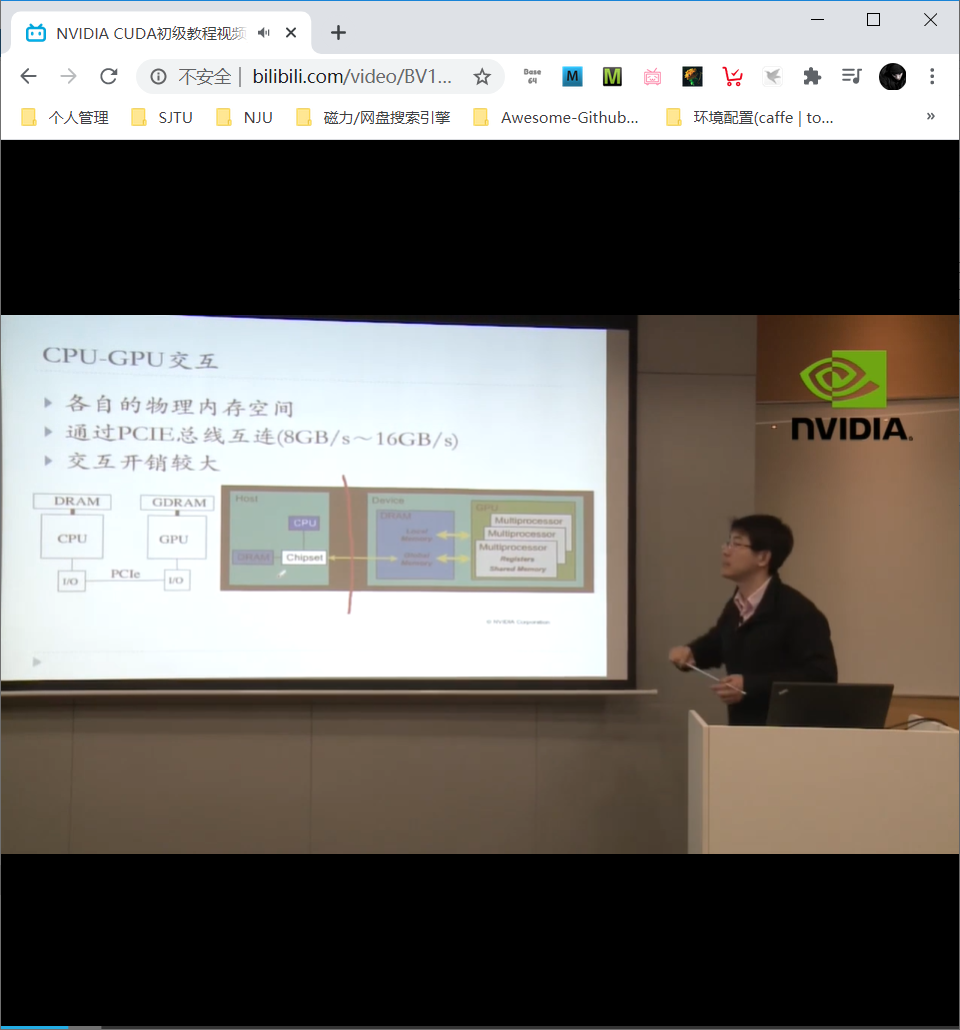
GPU 与 CPU 通过 PCIE 总线互连,开销较大。
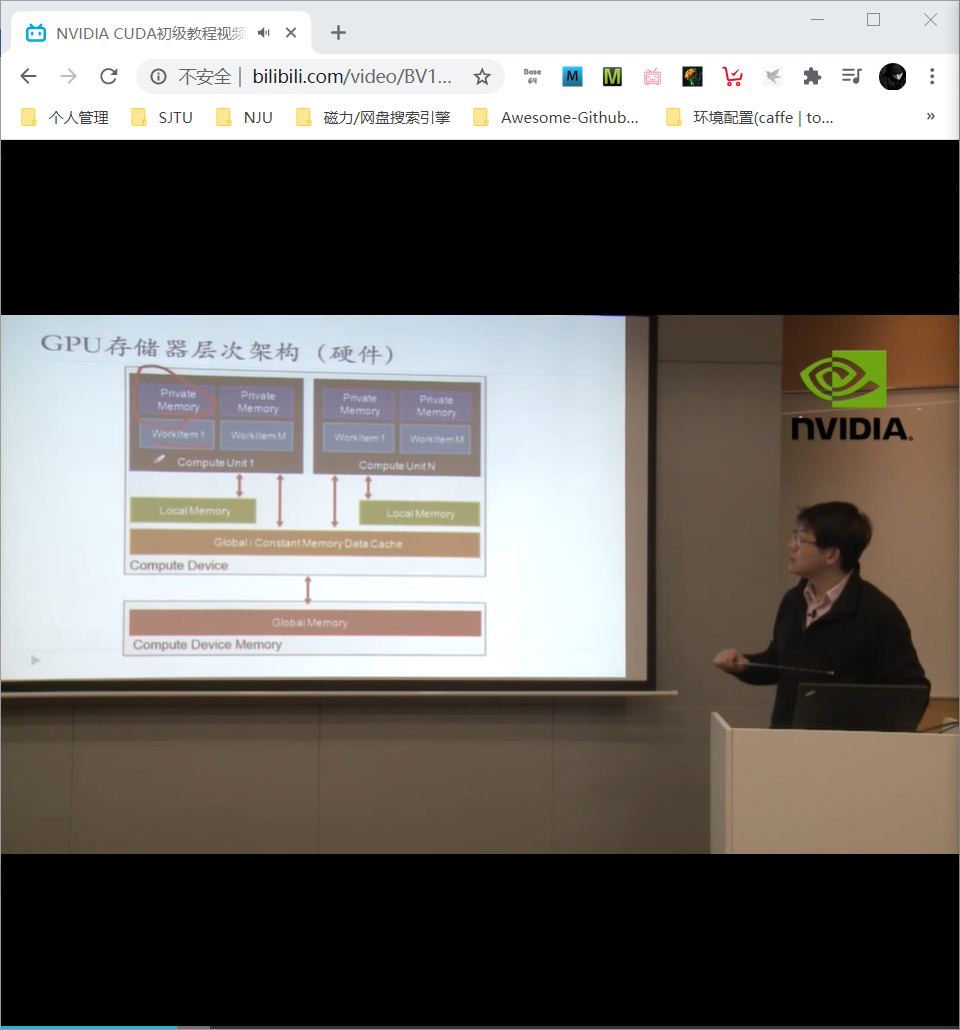
访存速度从快到慢:register > shared memory > local memory (DRAM, 每个线程SM有自己的缓存) > global memory (DRAM) > constant memory (DRAM, cached) > texture memory (also DRAM, cached) > instruction memory (invisible, DRAM, cached)
参考:CUDA 中的数组(Array)与纹理存储(Texture)介绍与使用
CUDA 中有不同的内存类型,包括全局存储(Global Memory)、共享存储(Shared Memory)、常数存储器(Constant Memory)、寄存器(Register)等。这些不同类型的存储器在物理位置、访问效率上各有不同,因此适合不同的应用场景,这里不展开。这篇文章主要介绍一种存储器:纹理存储器(Texture Memory),以及如何使用它加速访问线性内存与 CUDA 数组(Array)。
纹理存储可以在读取其中某个数据时将临近的值载入缓存(所谓的存储局部性 locality),这样下次访问时,则可以直接命中缓存,减少对 Global Memory 的访问,从而提高效率。
由于纹理存储器转为图像纹理渲染而设计,它特别适合图像处理、查找表等,对随机访问与非对齐访问有良好的加速效果,并且可以按需在返回时同时进行滤波等操作。
显存中可以分配的空间有两种:线性内存和 CUDA 数组,都可以与纹理参照系绑定,但是 CUDA 数组对纹理拾取(texture fetching)有优化,并且在设备端只能通过纹理拾取访问。
GPU线程组织模型
grid –> block (线程块) –> thread, 实现了快速有效的索引
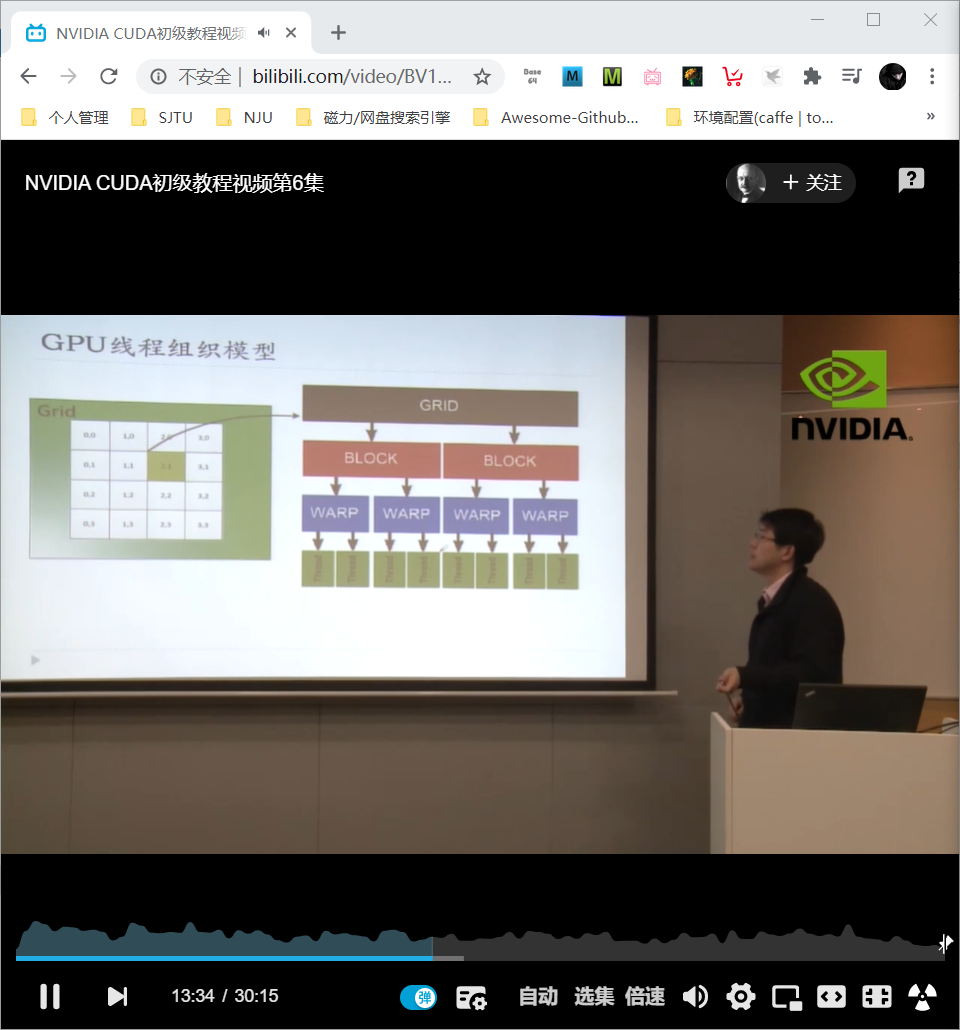
GPU线程映射关系
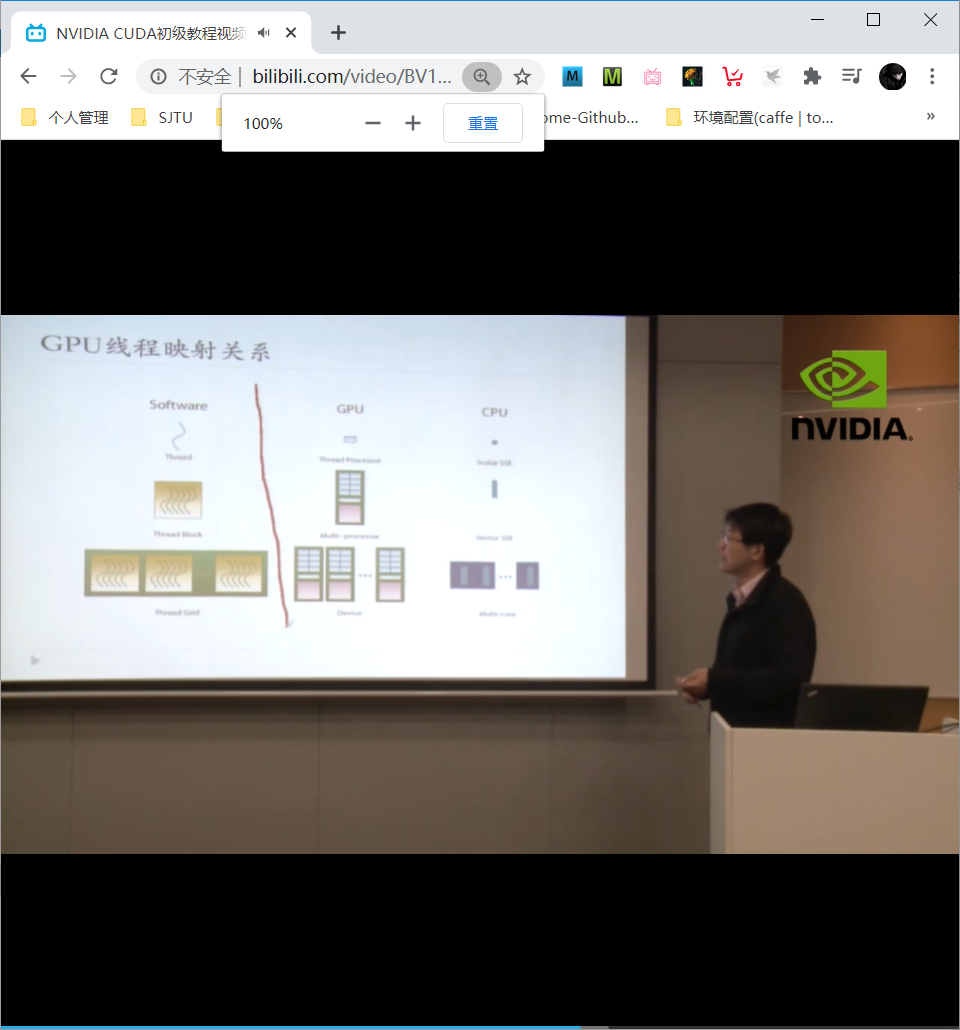
CPU: scalar SSE –> vector SSE –> multi cores
GPU内存和线程等关系

GPU编程模型
常规意义的GPU用于处理图形图像
操作于像素,每个像素的操作都类似
可以应用SIMD(数据并行分割)–> SIMT
关于SIMT:
- GPU版本的SIMD
- 大量线程模型获得高度并行
- 线程切换获得延迟掩藏
- 多个线程执行相同的指令流
- GPU大量线程承载与调度
CUDA编程模式
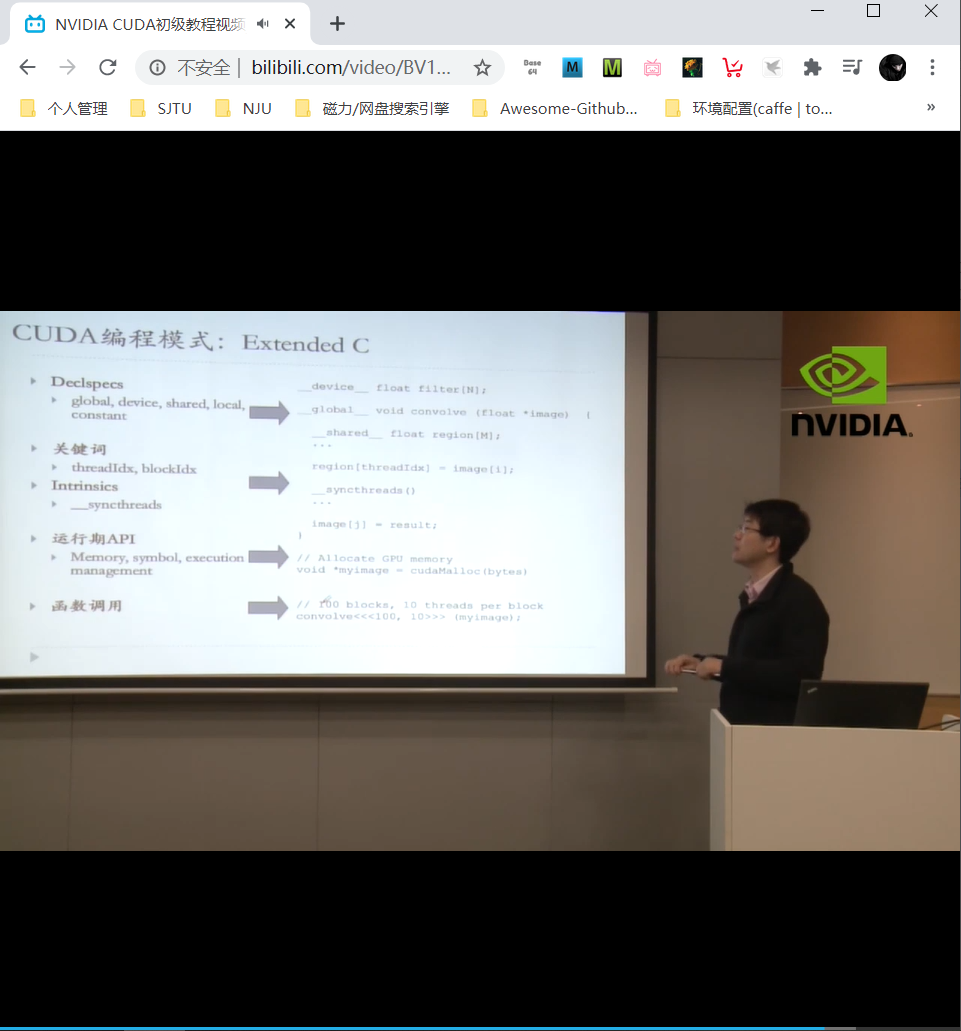
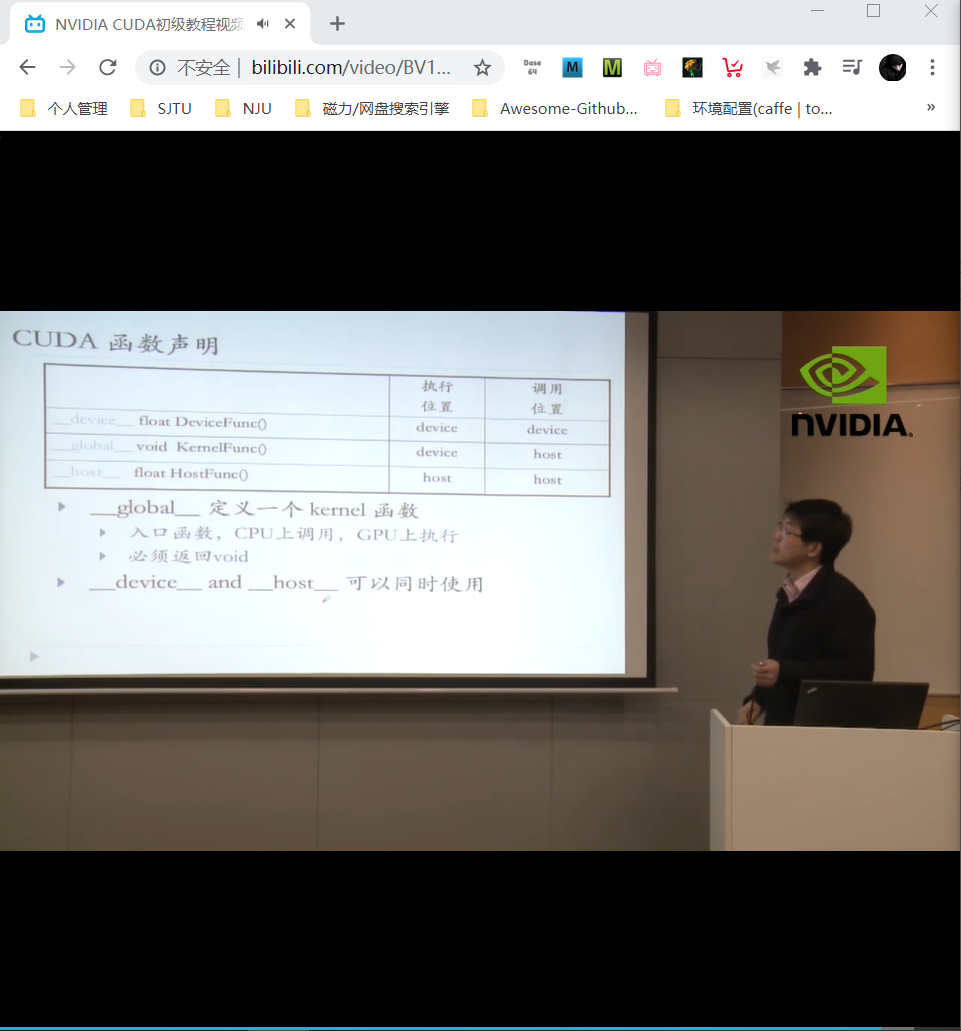
__device__, __global__, __host__
文档信息
- 本文作者:Mengqi Cao
- 本文链接:https://rogercmq.github.io//2020/06/24/CUDA-Day-4-GPU%E7%BC%96%E7%A8%8B%E6%A8%A1%E5%9E%8B/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)