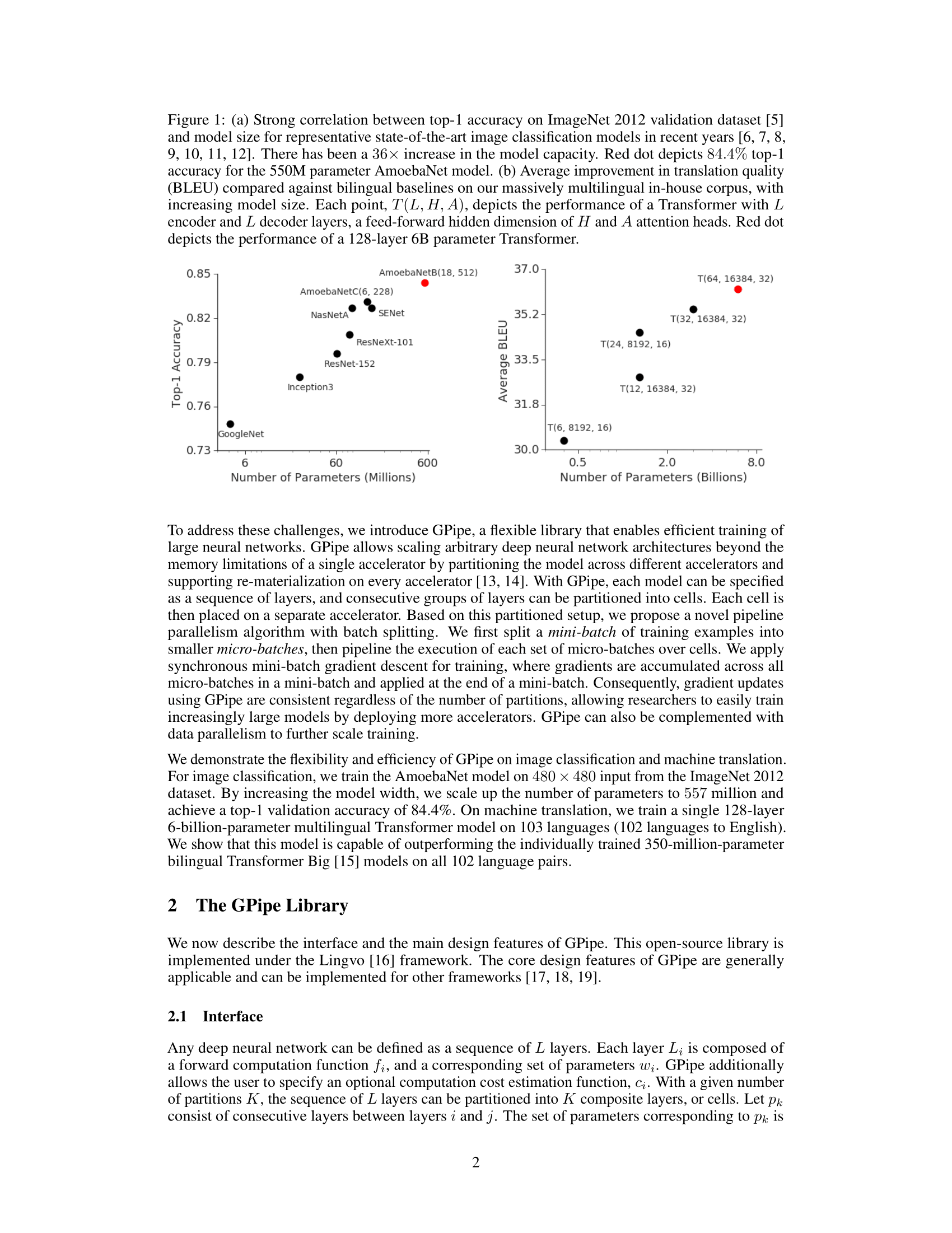
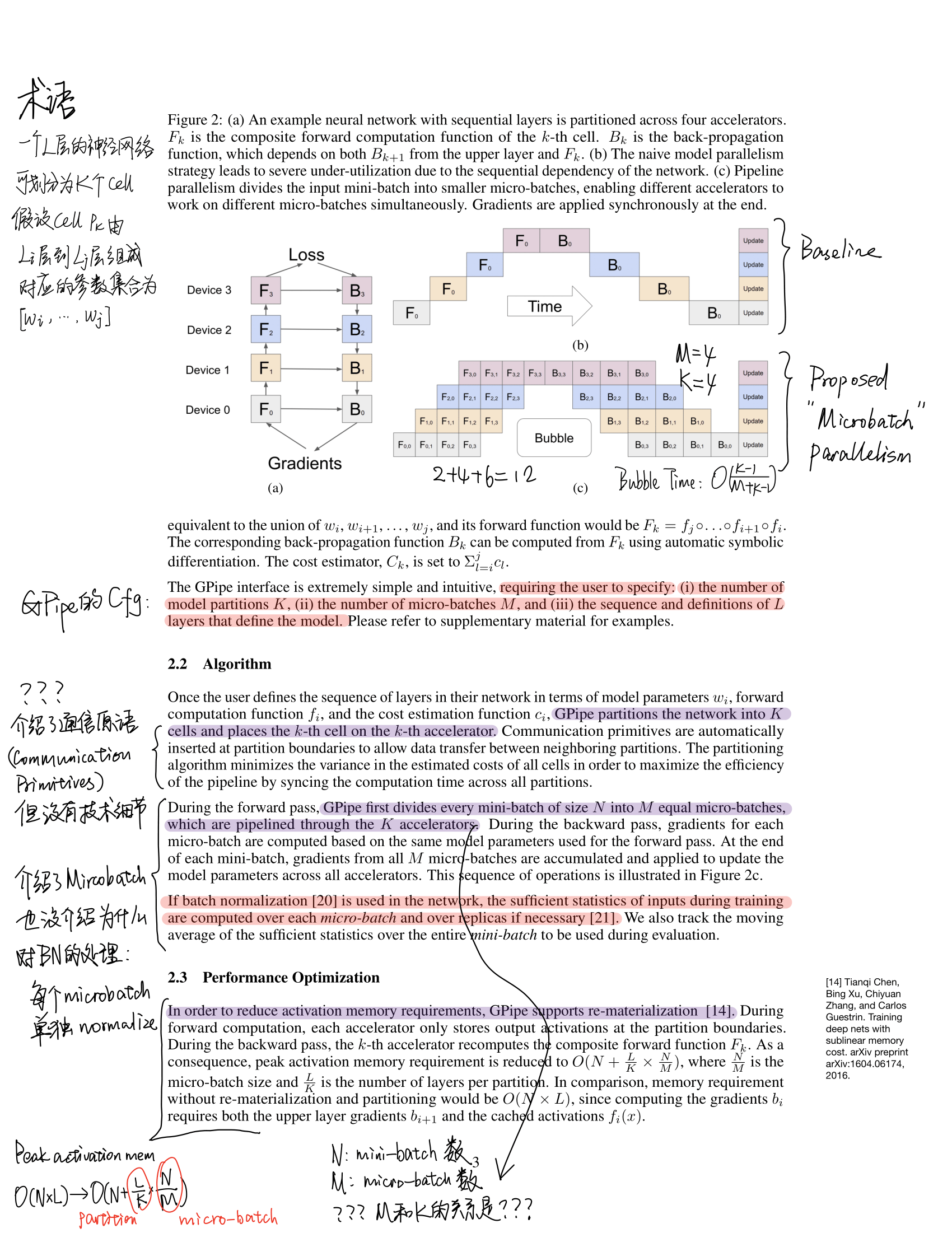
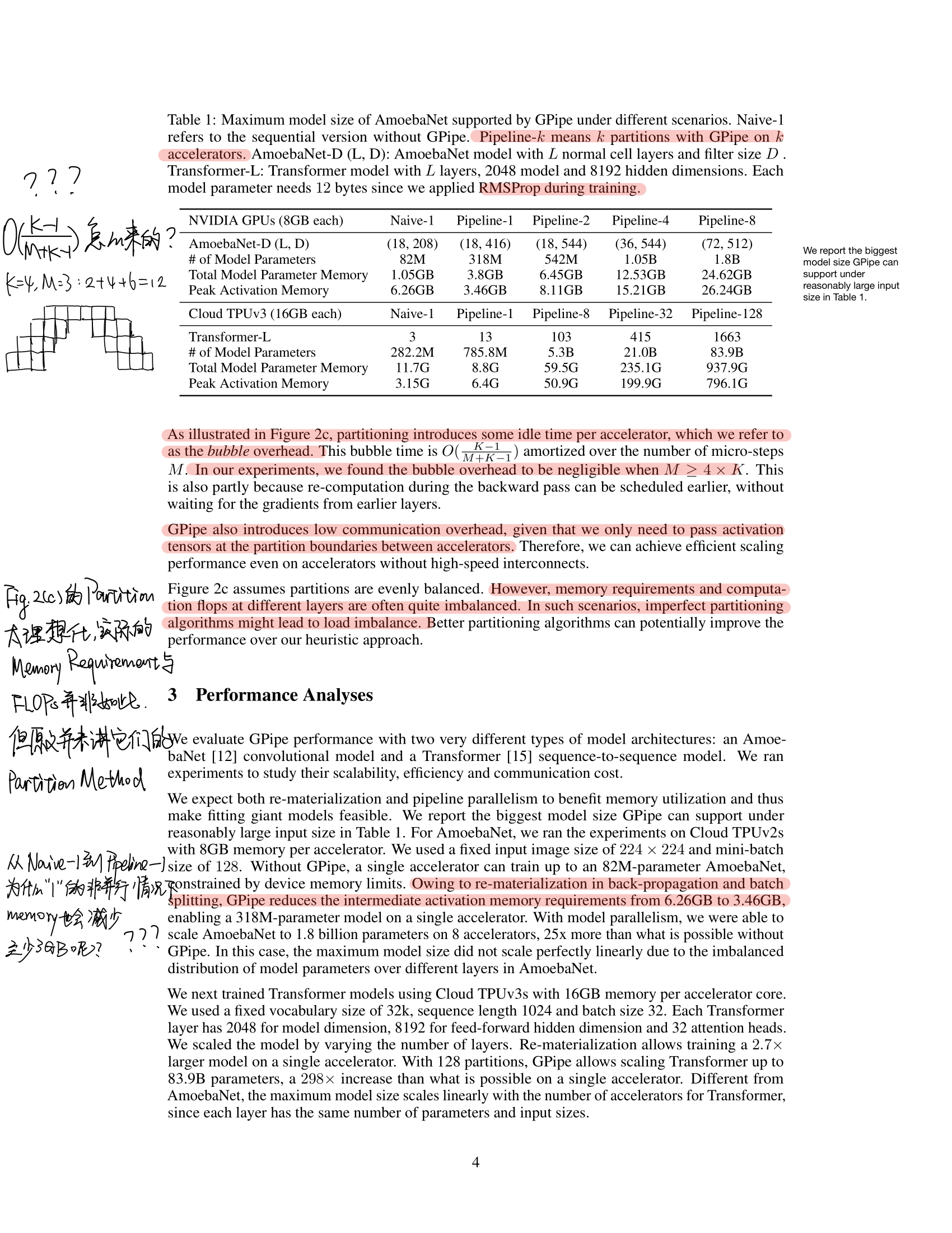
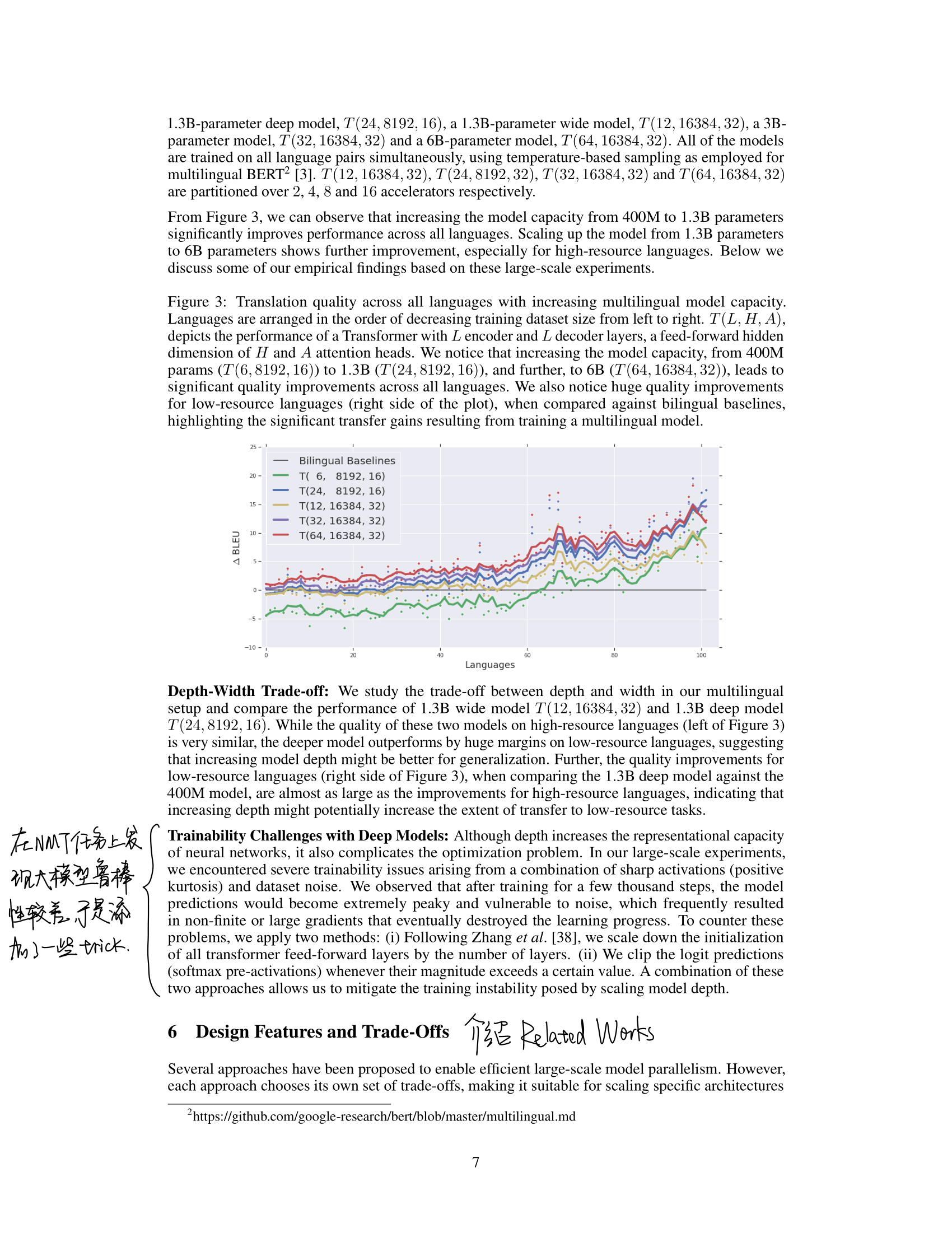
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism (NIPS2019)
2020年又添加了部分功能,结果发表于文章《torchgpipe: On-the-fly Pipeline Parallelism for Training Giant Models》,pytorch lib url: HERE。
关于 gradient descent, SGD, mini-batch GD:
- 梯度下降:梯度下降就是我上面的推导,在梯度下降中,对于
的更新,需要计算所有的样本然后求平均.其计算得到的是一个标准梯度。因而理论上来说一次更新的幅度是比较大的。
- 随机梯度下降:可以看到多了随机两个字,随机也就是说我每次用样本中的一个例子来近似我所有的样本,用这一个例子来计算梯度并用这个梯度来更新
- 批量随机梯度下降:他用了一些小样本来近似全部的,其本质就是竟然1个样本的近似不一定准,那就用更大的30个或50个样本来近似。将样本分成m个mini-batch,每个mini-batch包含n个样本;在每个mini-batch里计算每个样本的梯度,然后在这个mini-batch里求和取平均作为最终的梯度来更新参数;然后再用下一个mini-batch来计算梯度,如此循环下去直到m个mini-batch操作完就称为一个epoch结束。