Conditional Channel Gated Networks for Task-Aware Continual Learning (CVPR 2020)
Abstract
我们为每个卷积层添加了一个 task-specific gating 模块,为给定的每个输入特征图(per-sample)选择合适的滤波器。由此我们达到了两个目的:门控机制保护了重要的滤波器,确保不会有精度损失;其次,通过设计对 channel-wise gate 稀疏的目标函数,保证有足够的剩余参数去学习接下来的任务。
已有的方案在测试阶段,要求提前获取测试数据标签,这样才能在训练好的 subnetwork 上直接进行推理,但是这种方案是不实用的。于是我们又训练了一个 task classifier/predictor 来预测测试数据样本的标签,此分类器与任务需要的 class classifier 是同时训练的。
在 Split SVHN and Imagenet-50 数据集上分别有 23.98% 和17.42% 的涨点。
1. Introduction
首先将 CL 问题分为两类:
task-incremental: 一个任务一个任务地做(类似本人的本科毕业设计)
class-incremental: 一个类一个类地多(A model can instantiate a new task whenever novel classes emerge from the training stream.)
本工作提出的方案对以上两种 setting 都适用且可以达到 SOTA。
2. Related work
作者称,识别重要参数以防止在后续任务训练过程中被大幅度更新 (preventing significant updates) 的方案为 “Consolidation”。
对于task-incremental:
- 一类方法是对参数进行 task-specific 重要性评估。The relevance/importance estimation for each parameter can be carried out through the Fisher Information Matrix [15], the path integral of loss gradients [41], gradient magnitude [1] and a posteriori uncertainty estimation in a Bayesian Neural Network [26].
- 另外一类方法是是训练一个二值掩码。Such masks can be estimated either by random assignment [23], pruning [22] or gradient descent [21, 34]. 但是此类方案需要提前获取测试数据标签,这是不实用的。
对于class-incremental:
- In this work, we also rely on either episodic or generative memories to deal with the class-incremental learning setting. However, we carry out replay only to prevent forgetting of the task predictor, thus avoiding to update task-specific classification heads. 也就是说保留下来的原始训练数据只是用来训练 task classifier/predictor。
作者提到了一个方向叫做 Conditional Computation,讨论的是为给定输入自适应网络架构的问题(deep neural networks that adapt their architecture to the given input),这也是本篇工作的最大动机。此动机在旷视一篇语义分割的 CVPR2020 《learning dynamic routing for semantic segmentation》论文中也有提及。在剪枝领域似乎也有类似的文章,比如《SkipNet: Learning Dynamic Routing in Convolutional Networks》。In our work, we rely on the latter strategy, learning a set of task-specific gating modules selecting which kernels to apply on the given input. To our knowledge, this is the first application of data-dependent channel-gating in continual learning.
3. Model
3.1. Problem setting and objective
作者的 two-fold 训练方案:
好处有以下三点,虽然没有一点有理论依据:
我的疑问:把一个优化问题拆分为两个子问题就一定可以降低算法复杂度吗?
- given the task label, there is no drop in class prediction accuracy;
- classes from different tasks never compete with each other, neither during training nor during test;
- the challenging single-head prediction step is shifted from class to task level; as tasks and classes form a two-level hierarchy, the prediction of the former is arguably easier (as it acts at a coarser semantic level).
3.2. Multi-head learning of class labels
本文提出的 Gate Module 在全连接层和残差模块都可以用, 但是 Gate Module 依然还是一个多层感知器结构
each gating module comprises a Multi-Layer Perceptron (MLP) with a single hidden layer featuring 16 units, followed by a batch normalization layer and a ReLU activation. A final linear map provides log-probabilities for each output channel of the convolution.
Gate Module 的反向传播采用的是 Gumbel Softmax sampling [13, 20]
and get a biased estimate of the gradient utilizing the straight-through estimator [4]. Specifically, we employ the hard threshold in the forward pass (zero-centered) and the sigmoid function in the backward pass (with temperature τ = 2/3).
在这停顿,什么是 Gumbel Softmax Sampling
然后在损失函数中添加了L1稀疏正则项(正体L代表模型层数):
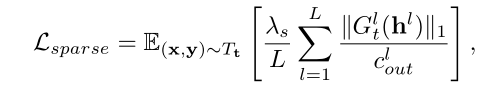
这个 “Gumbel Softmax Sampling + L1 Norm” 的方法不需要给定模型压缩率。在我的毕业设计方法中,需要对不同模型压缩率下的精度进行评估,从而选出 FLOPs 和 精度的 trade-off 模型,而在本文的方法中似乎不需要这样。
Such a data-driven model selection contrasts with other continual learning strategies that employ fixed ratios for model growing [32] or weight pruning [22].
[22] Packnet: Adding multiple tasks to a single network by iterative pruning. In IEEE International Conference on Computer Vision and Pattern Recognition, 2018.
[32] Progressive neural networks. arXiv preprint arXiv:1606.04671, 2016.
任务 t 训练结束后,根据验证集 T 数据计算相关系数 \gamma,k 代表 channel index,l 代表 layer index,t 代表 task index。根据公式6,应该是统计了整个验证集上的 channel-wise gate 均值作为相关系数,根据给定的 \gamma threshold 将重要的参数筛选出来,重要的参数在后续的训练过程中不会被更新。狠的是作者将相关系数的阈值设置为0。
本人认为这一段没什么创新点。
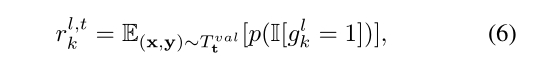
3.3. Single-head learning of task labels
task classifier 的输入是最后一个卷积层所有 candidate feature map 的 concatenation。公式7的 \mu 代表 Global Average Pooling(over the spatial dimensions)。task classifier 的网络结构是一个带有 64 个隐藏节点的 MLP。损失函数是交叉熵。
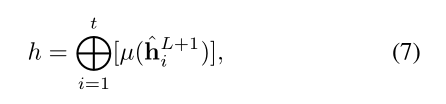
task classifier 的训练需要部分以前任务的数据样本,作者称此类方法为 replay-based approach。于是讨论了两大类 replay 方案:真实样本随机采样,人工样本GAN出来
Episodic memory. A small subset of examples from prior tasks is used to rehearse the task classifier. During the training of task t, the buffer holds C random examples from past tasks 1,…,t − 1 (where C denotes a fixed capacity). Examples from the buffer and the current batch (from task t) are re-sampled so that the distribution of task labels in the rehearsal batch is uniform. At the end of task t, the data in the buffer is subsampled so that each past task holds m = C/t examples. Finally, m random examples from task t are selected for storage.
Generative memory. A generative model is employed for sampling fake data from prior tasks. Specifically, we utilize Wasserstein GANs with Gradient Penalty (WGAN-GP [10]). To overcome forgetting in the sampling procedure, we use multiple generators, each of which models the distribution of examples of a specific task.
有趣的是正常的 class classifier 不需要 replay,原文没有介绍 implementation 时是怎么让两个分类器同时训练的。我猜的是在当前任务训练结束后对当前数据进行采样,采样出来的数据和之前保留的数据一起 replay,但是这样违背了作者 argue 的 joint training 模式。
4. Experiments
4.1. Datasets and backbone architectures
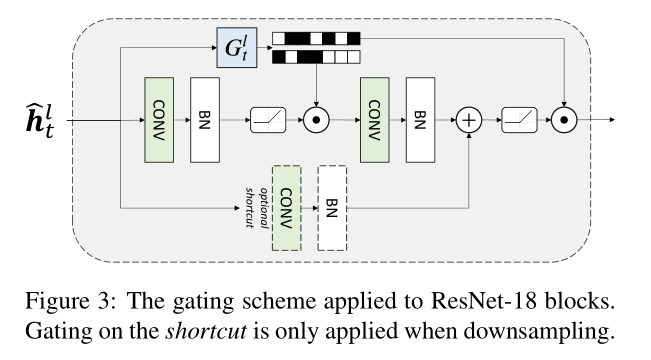
添加的位置很奇妙,并没有所有 CONV 都添加 gate module,而且是放在了激活函数后面。
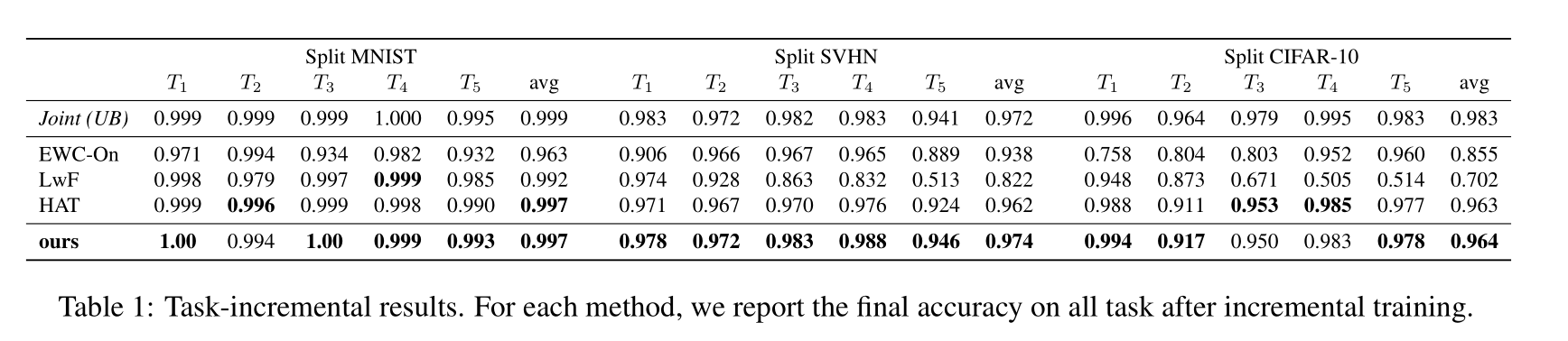
4.2. Task-incremental setting
在该场景下,测试阶段已知 task index,所以不需要训练 task classifier。
提到了四篇 baseline method:
Joint: the backbone model trained jointly on all tasks while having access to the entire dataset. We considered its performance as the upper bound.
Ewc-On [33]: the online version of Elastic Weight Consolidation
LwF [18]: an approach in which the task loss is regularized by a distillation objective, employing the initial state of the model on the current task as a teacher.
HAT [34]: a mask-based model conditioning the active units in the network on the task label. Despite being the most similar approach to our method, it can only be applied in task-incremental settings.
[34] Overcoming catastrophic forgetting with hard attention to the task. International Conference on Machine Learning, 2018.
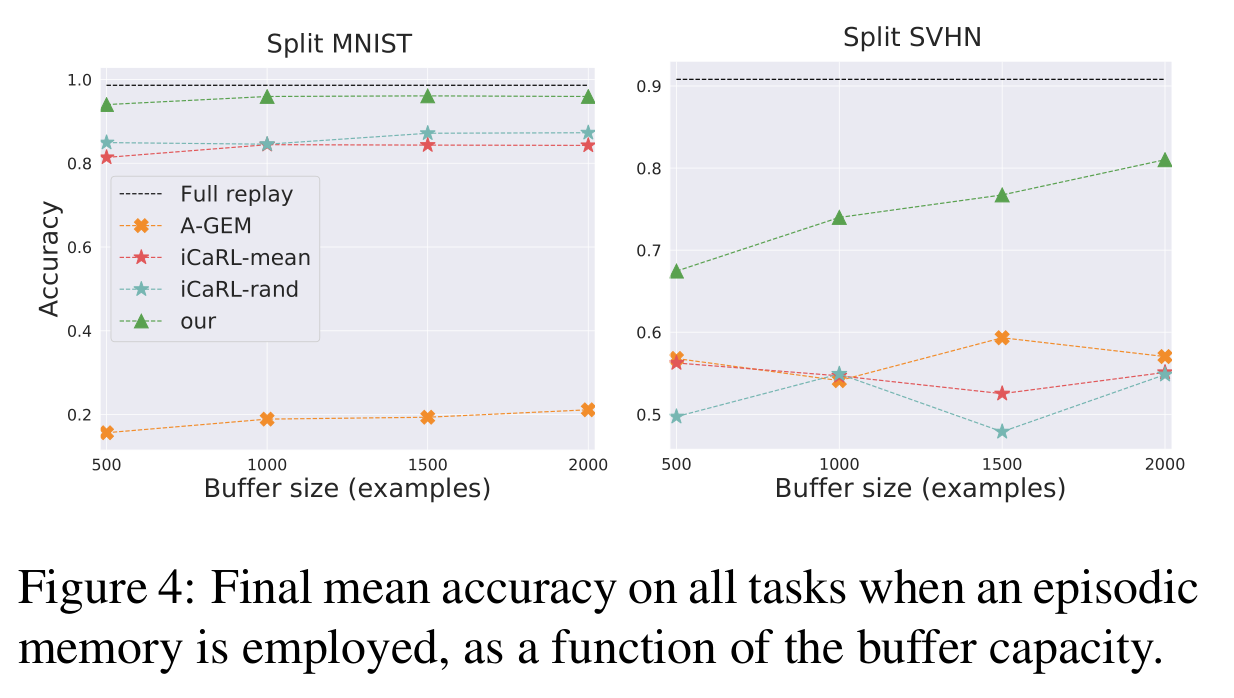
4.3. Class-incremental with episodic memory
三篇 baseline method:
- Full replay: upper bound performance given by replay to the network of an unlimited number of examples.
- iCaRL [29]: an approach based on a nearest-neighbor classifier exploiting examples in the buffer. We report the performances both with the original buffer-filling strategy (iCaRL-mean) and with the randomized algorithm used for our model (iCaRL-rand);
- A-GEM [5]: a buffer-based method correcting parameter updates on the current task so that they don’t contradict the gradient computed on the stored examples.
4.4. Class-incremental with generative memory
baseline method: DGM
DGM [28] is the state-of-the-art approach, which proposes a class-conditional GAN architecture paired with a hard attention mechanism similar to the one of HAT [34].
4.5. Model analysis
Episodic vs. generative memory 在相同 Memory consumption (单位是MB) 的条件下,使用真实数据得到的精度会更高。
On the cost of inference 虽然 gate module 引入了额外的参数,但是在某些简单任务(SPLIT-CIFAR10)的推理阶段依然会为模型带来 MAC 数的降低。
我的问题:为什么 class-incremental 场景下 MACs 会单调递增?只是因为 task classifier 的参数量增加了吗?