本讲座介绍了 CUHK MMLab 在 CVPR2020 发表的两篇工作,分别为《FineGym: A Hierarchical Video Dataset for Fine-grained Action Understanding》,《Intra- and Inter-Action Understanding via Temporal Action Parsing》。
Background

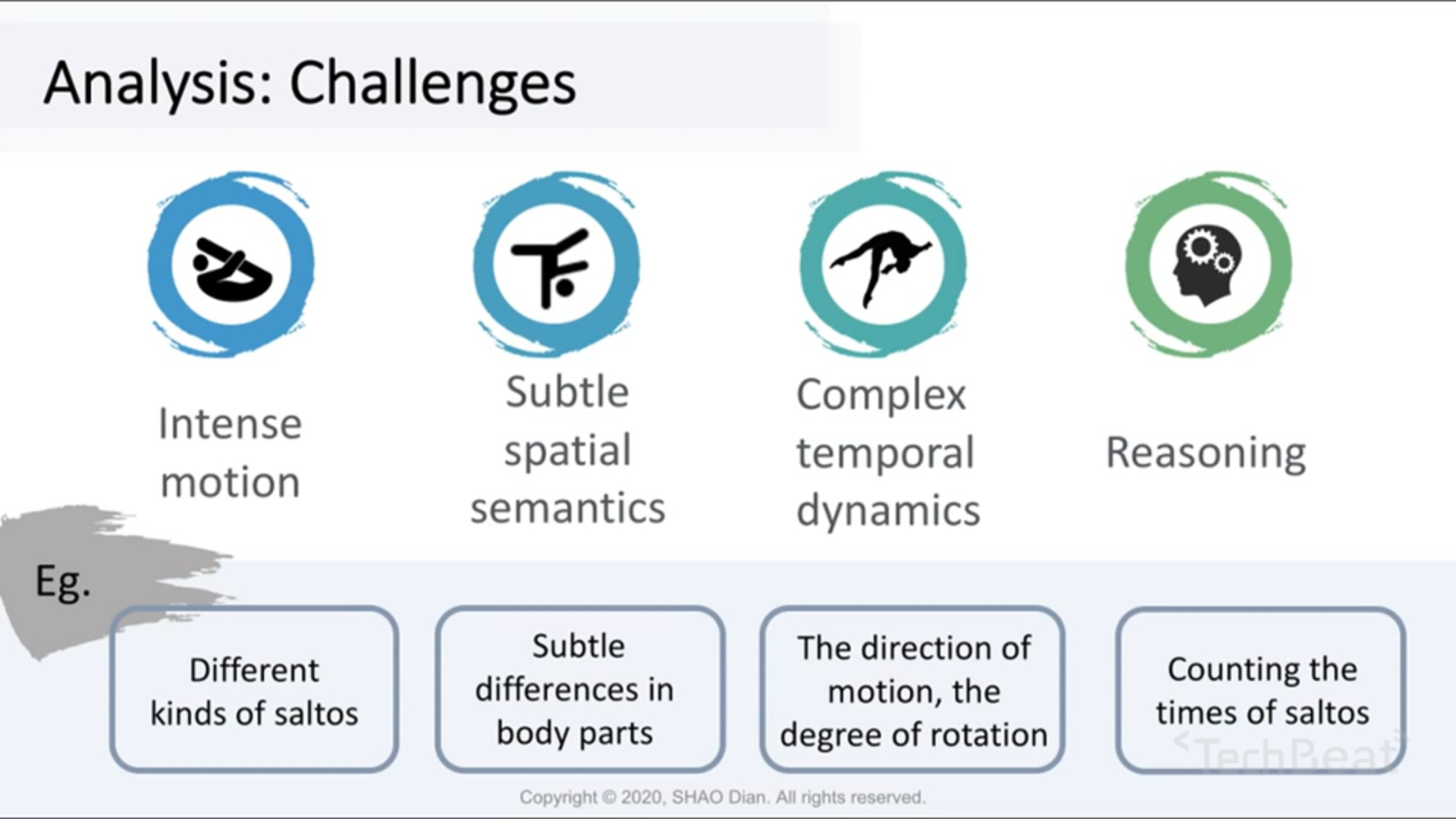
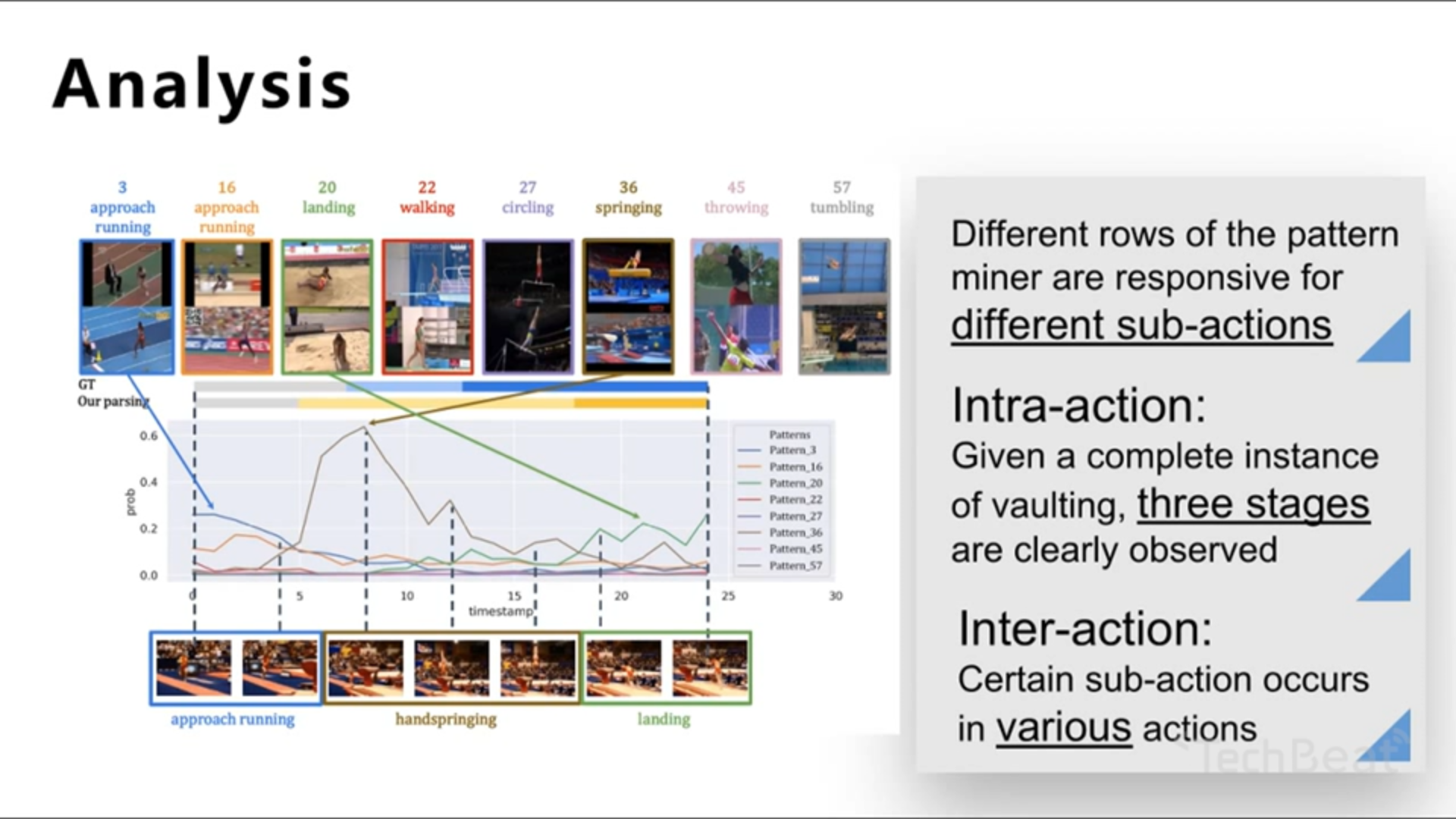
动作内部包含了很多子动作,人对子动作的边界是非常敏感的。于是细粒度的行为识别就包括了两个内容:
- intra-action 识别子动作,一个action由多个子动作构成;
- inter-action 判断子动作之间的关系,不同的action可能存在相同的子动作

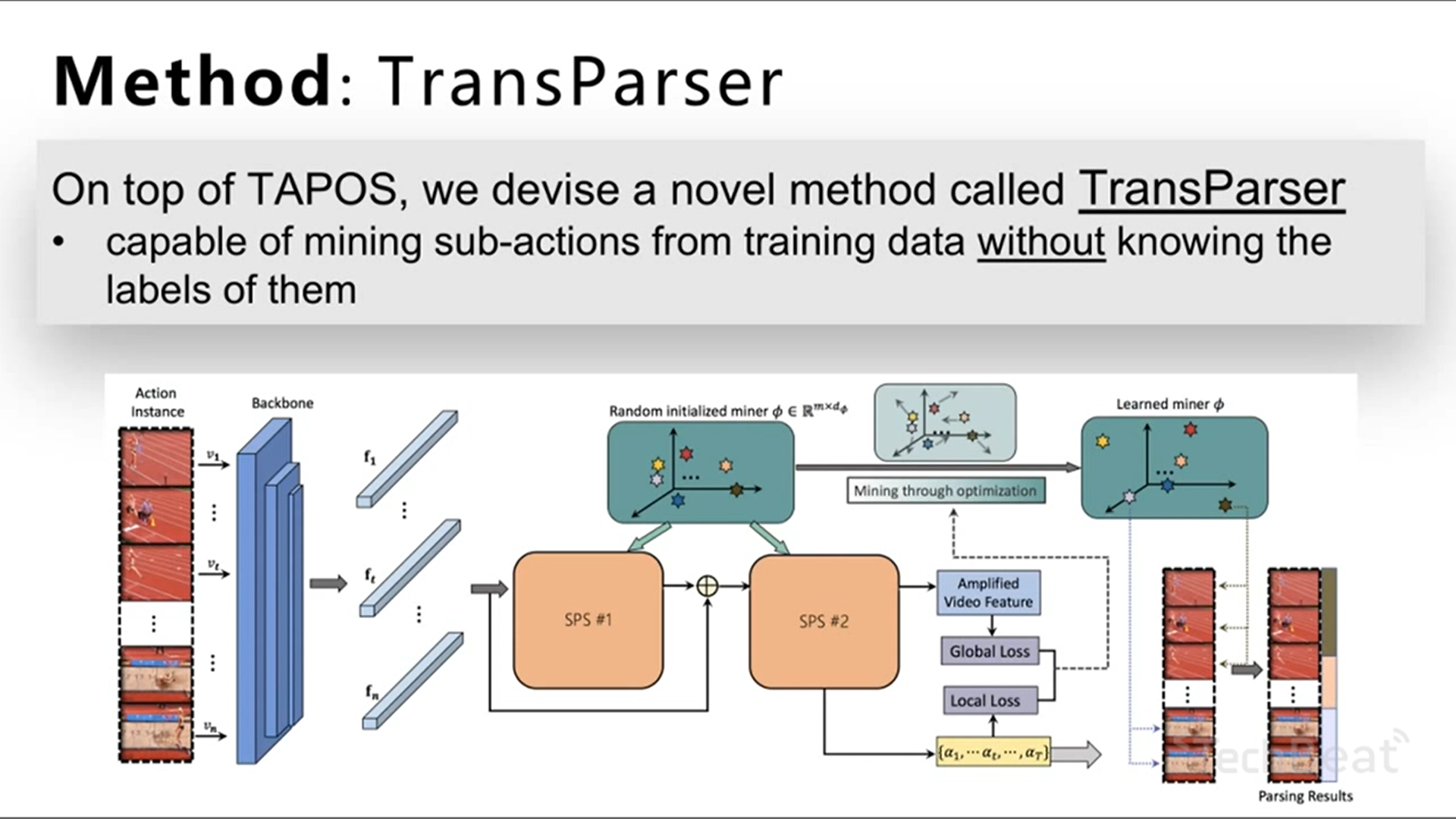
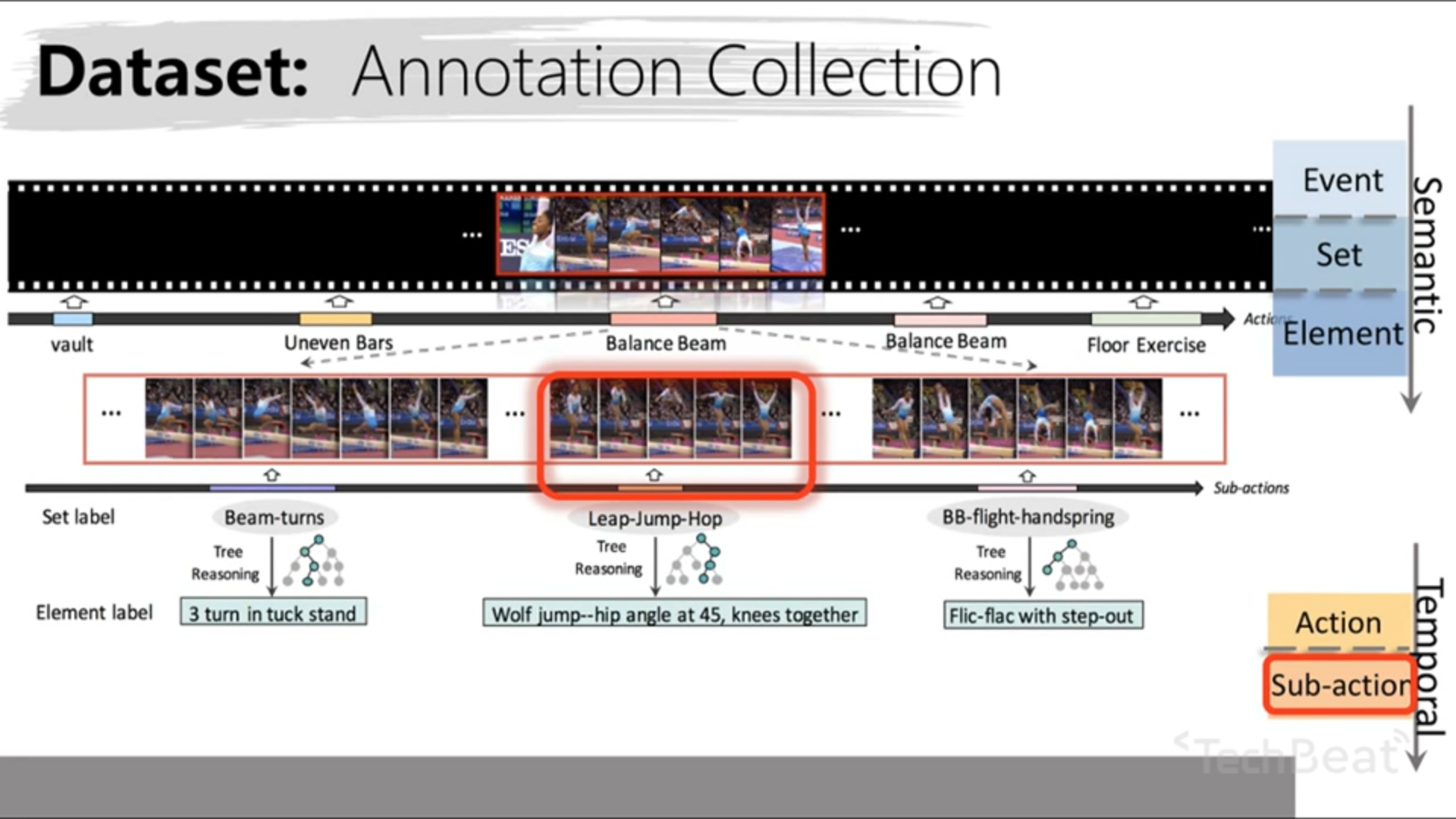
提出了一个细粒度的视频行为识别新数据集 TAPOS ,对每一个 sub-action 都打了标签,如下图所示(帧250-帧295之间表示一个 sub-action)

针对此数据集,作者提出了一个新任务:temporal action parsing(TAP),并提出了基于transformer的TAP模型。

Temporal Action Parsing: TransParser Model
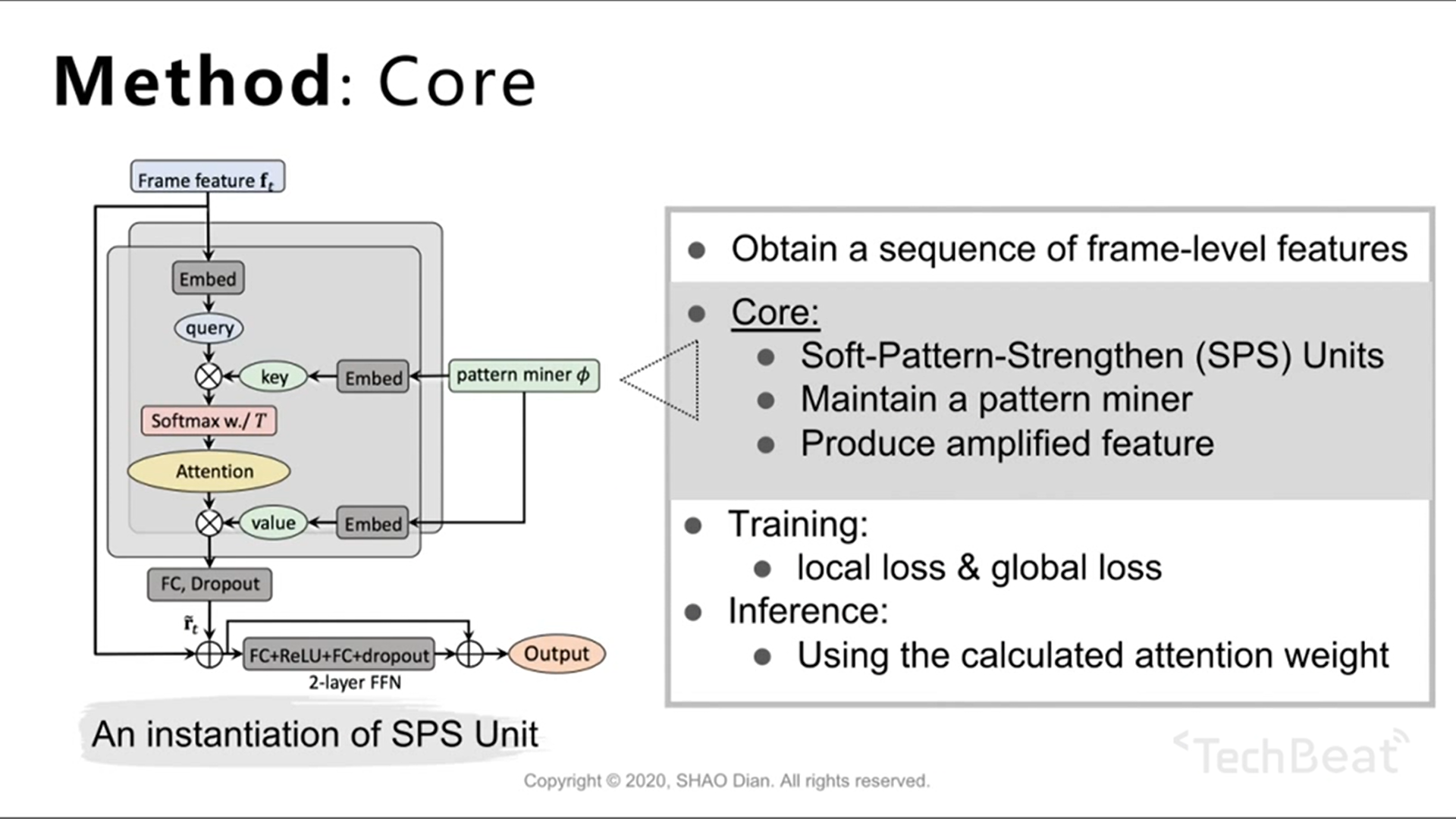
基于 Transformer 结构的 Soft-Pattern-Strengthen Unit
global loss: 动作的标签分类交叉熵
local loss: 使得同一子动作的内部相邻帧尽可能相似,不同子动作的相邻帧尽可能不相同
作者说有些pull-push的思想,什么意思?
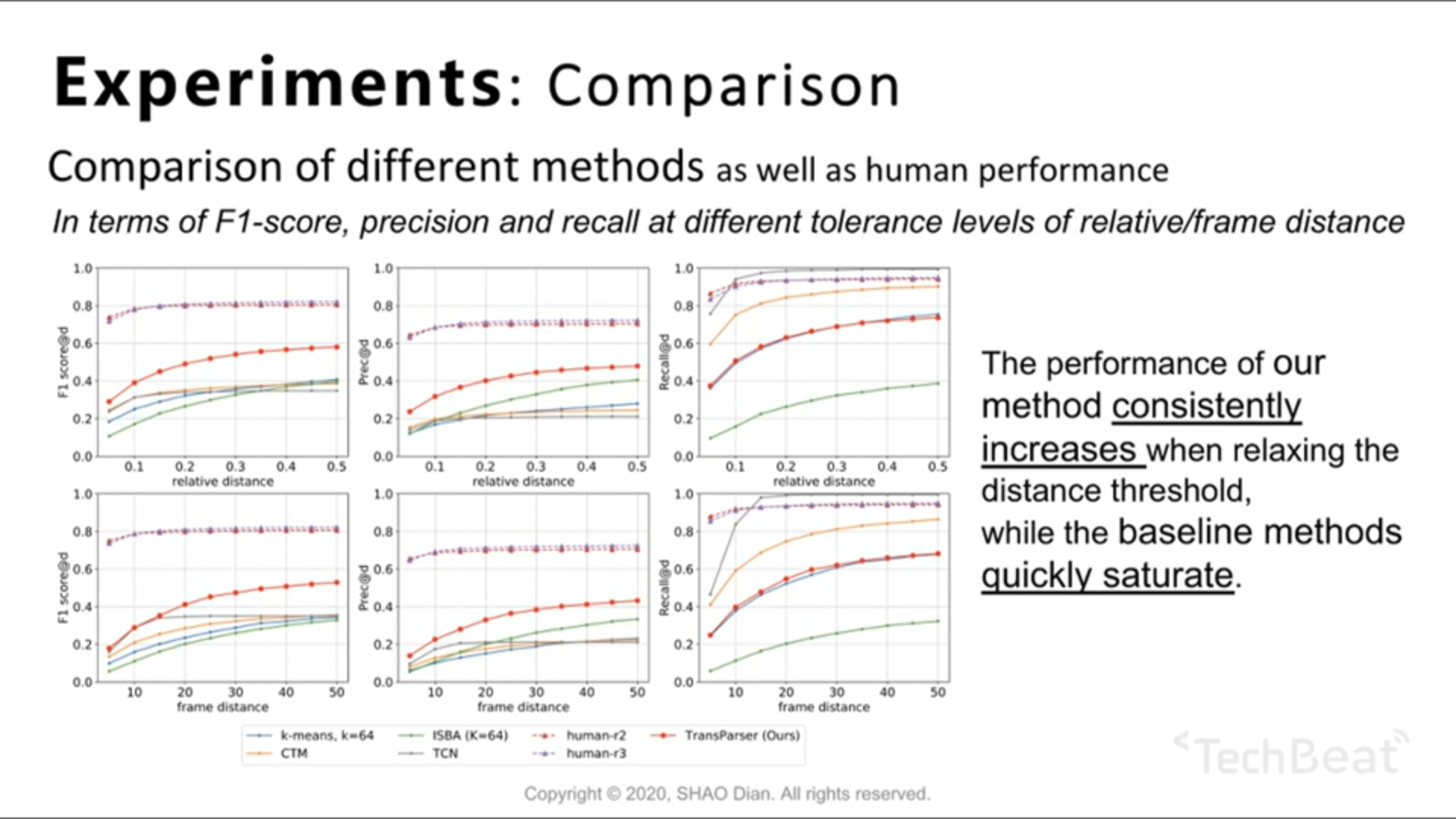
Experiments
Baseline: ISBA, TCN (按作者原话,此工作为工作内容相似的 Related Works)

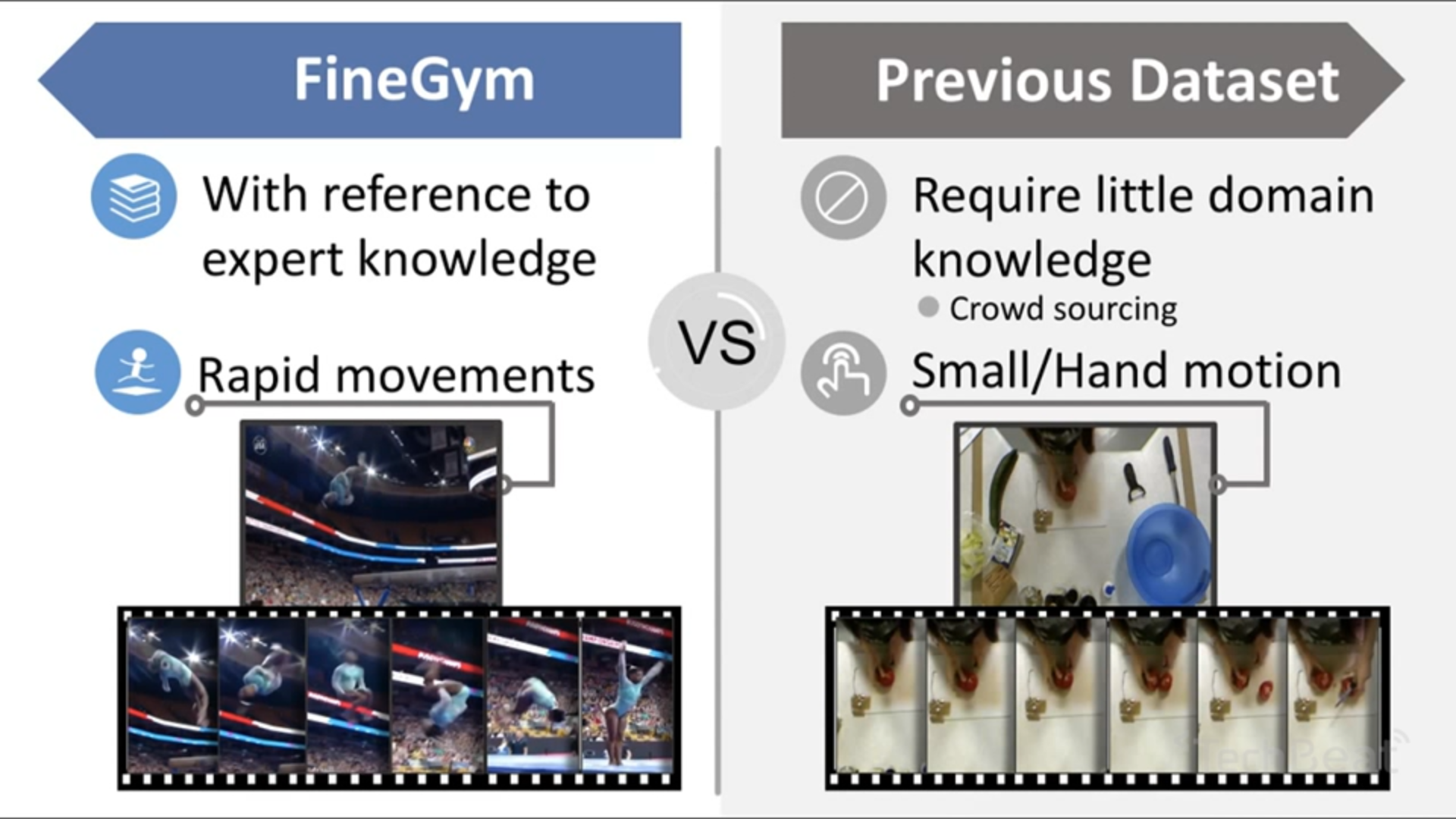
FineGym Dataset 体操

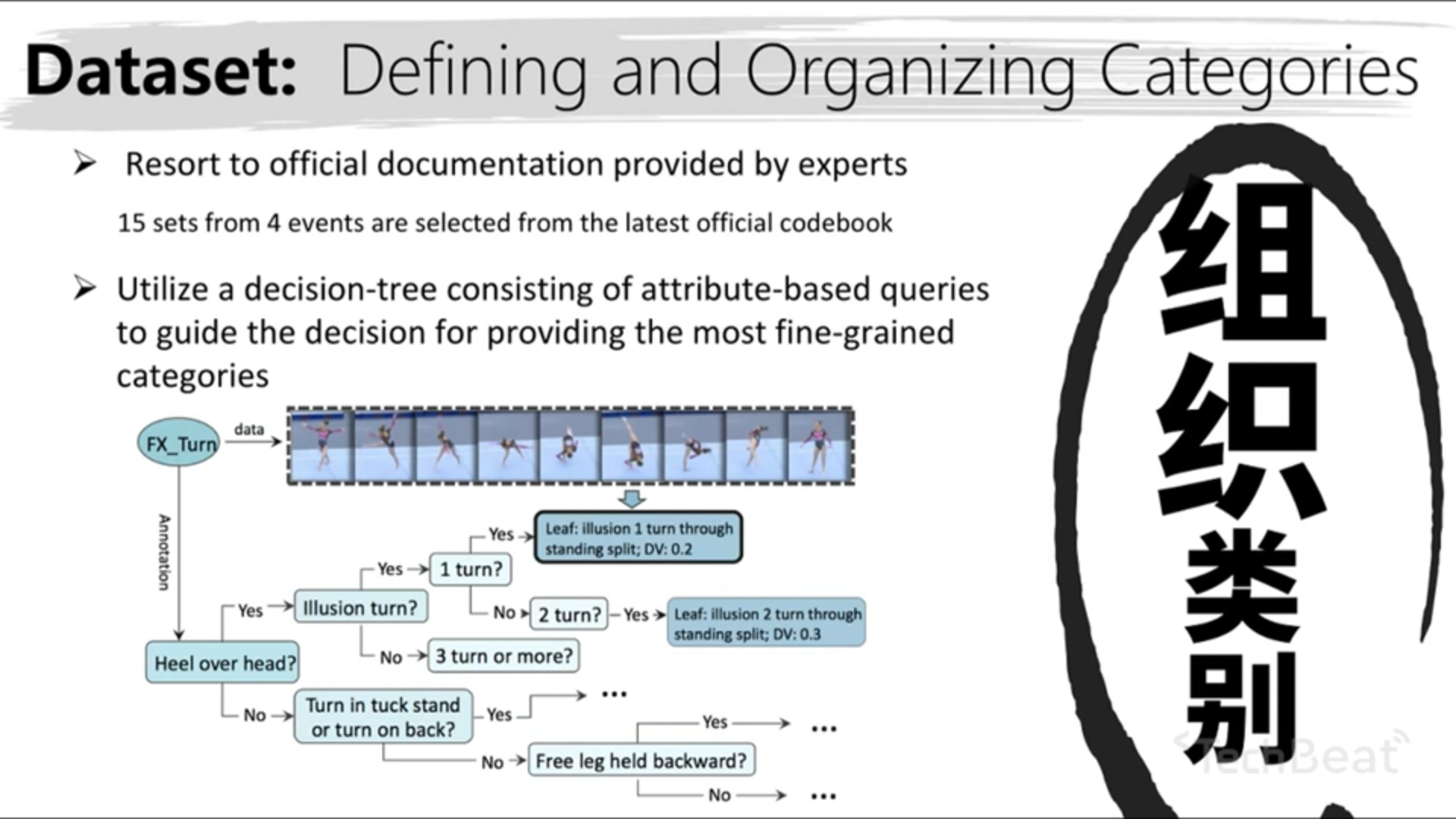
体操数据集的 ground truth 标注比较差。原因包括:部分 action instance 时间长(相较于跳远跳高几十秒,体操中比如平衡木可能需要两分钟,所以细粒度标注容错率低);体操 action 的姿势复杂且多样(diverse);体操 sub-action 需要一定专业知识。




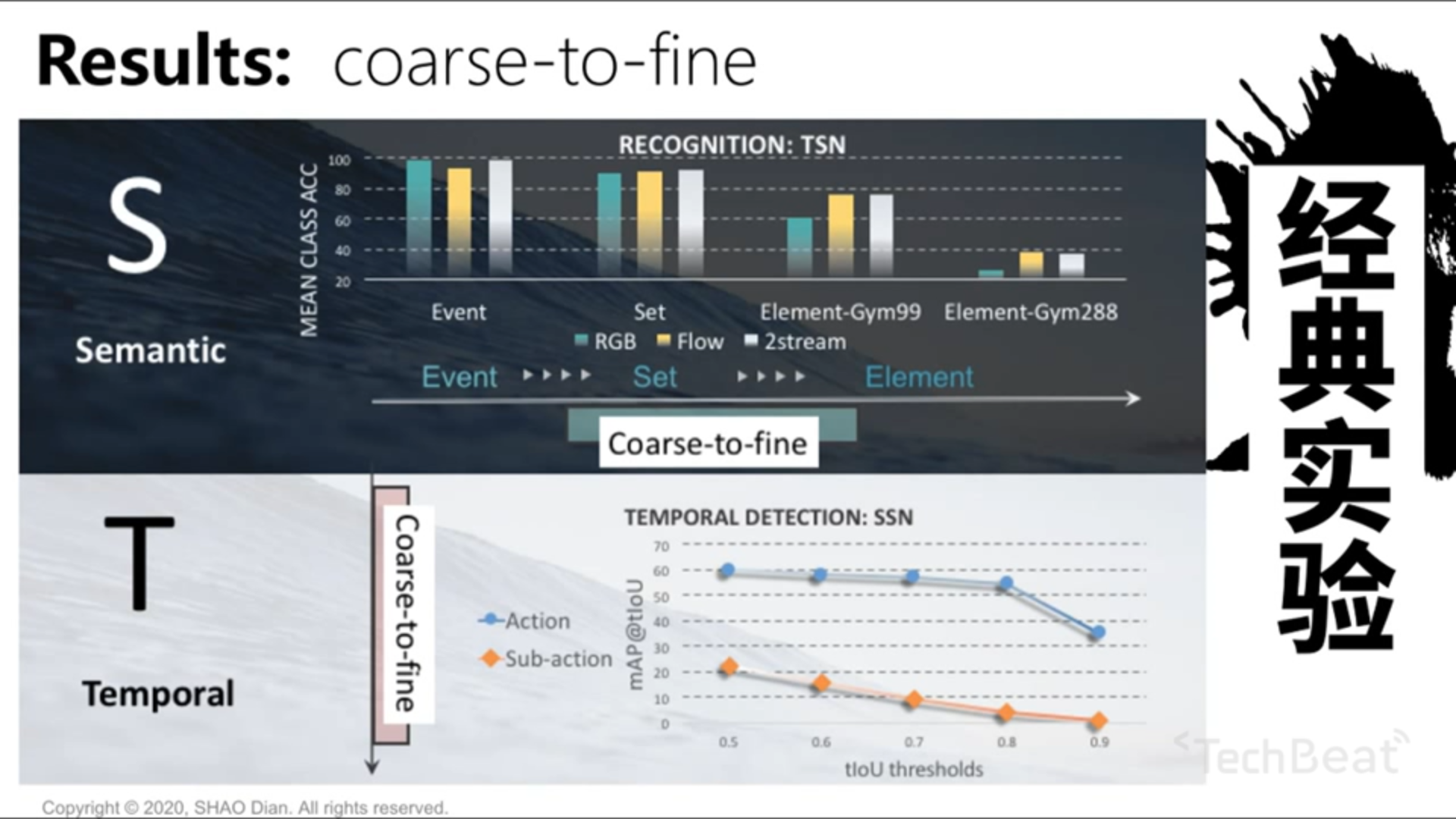
Experiements
用到了 Limin Wang 的 TSN 方法。S实验的发现:是当 action 的粒度越来越细时,RGB 的 contribution 越来越低,双流网络精度差不多。说明在 action 相对速度变大时提取 motion 信息更重要。T实验发现在一个 action 里寻找 sub-action 是非常难的。
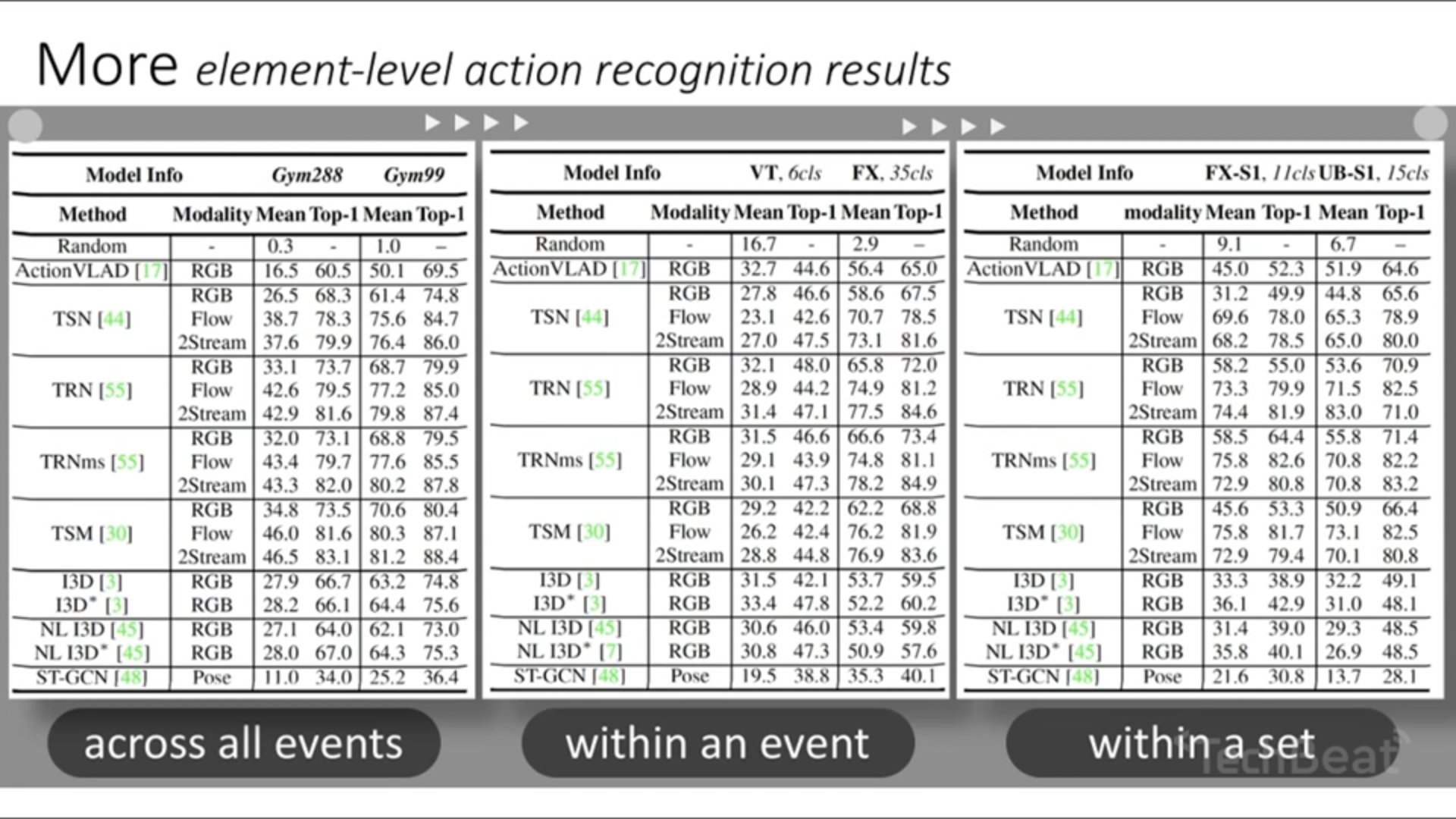
Analysis

Sparse Sampling: 在细粒度行为识别中每一帧都可能很重要,那么如何 balance 稀疏采样帧和模型精度的关系,是一个 open 的问题。
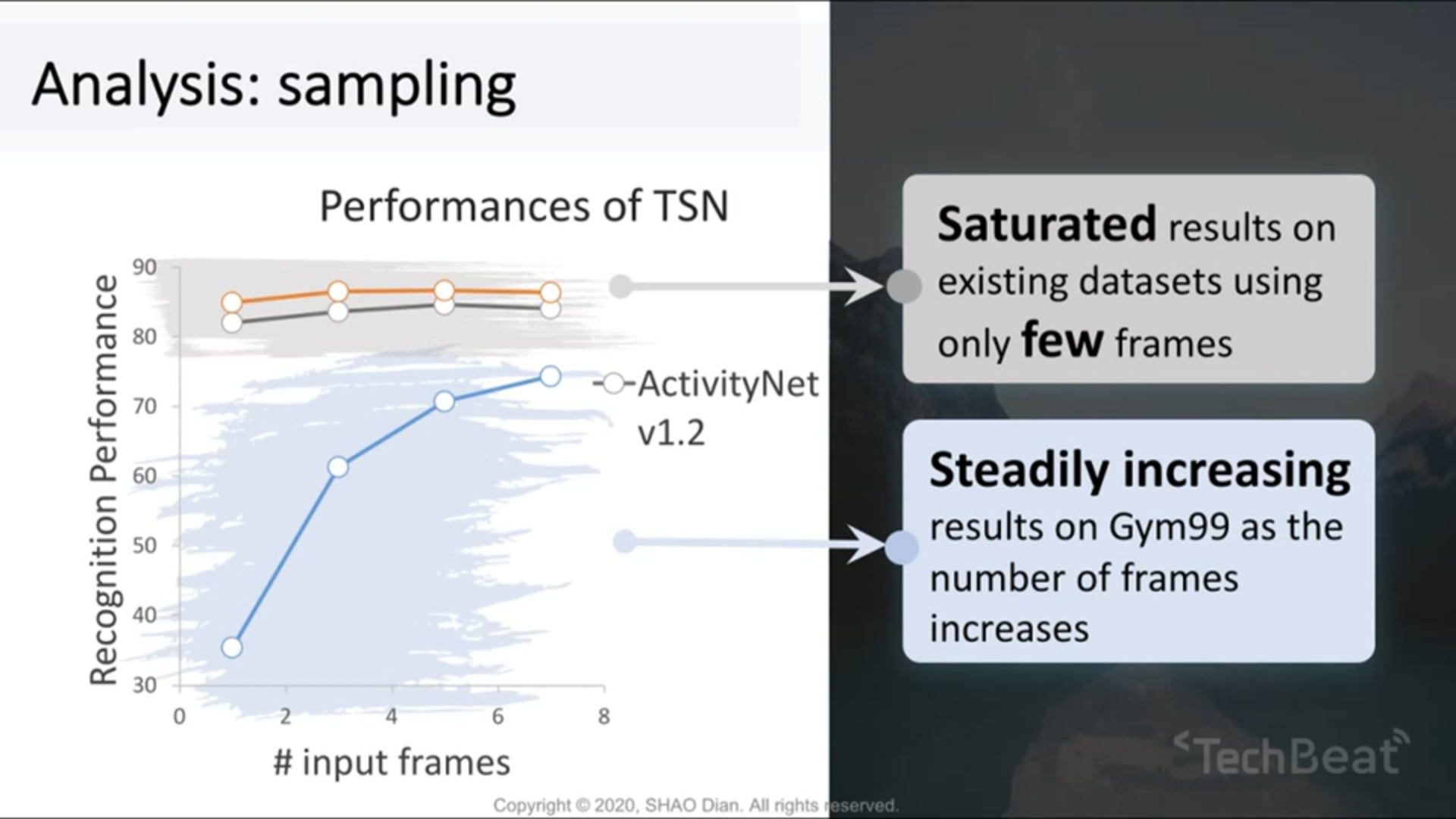
Temporal Modeling
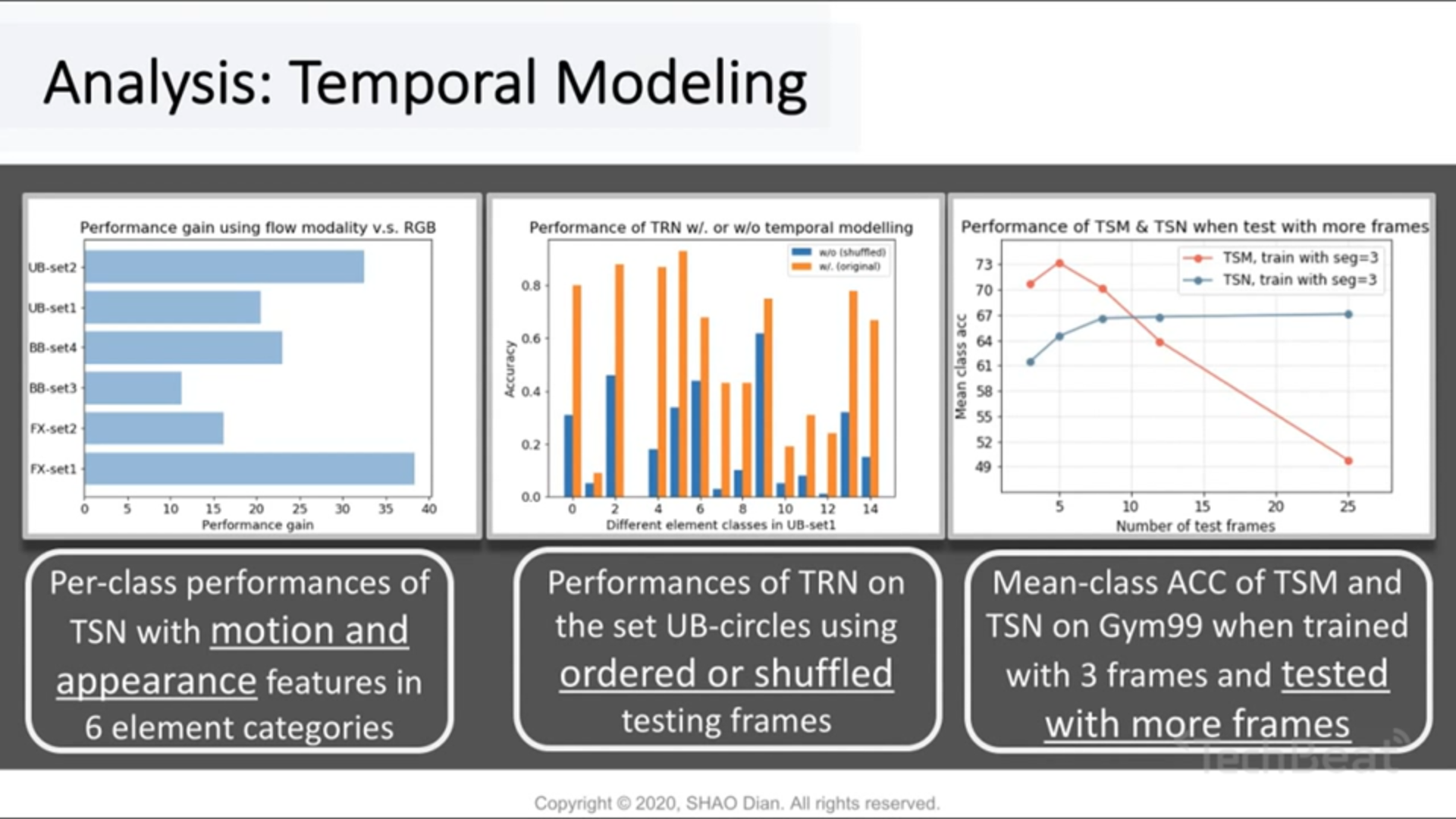
在该数据集上复现 TSN 方法,并统计使用 flow feature (a.k.a motion information) 与 RGB 相比的 per-class accuracy gain,发现都有所增加,说明 flow feature 很重要。
在该数据集上复现 Bolei Zhou 的 TRN,在测试时将测试及数据的帧序打乱,发现精度(紫色)爆炸减少,于是认为对时序很重要
横轴是什么意思?
在该数据集上复现 TSM,在测试时用不同 seg 的输入进行测试,发现 TSM 精度随帧数增加反而降低,于是认为帧数太多的话可能 overlap 了一些 sub-action,于是导致精度下降
但为什么 TSN 精度趋近稳定?没有解释理由
预训练
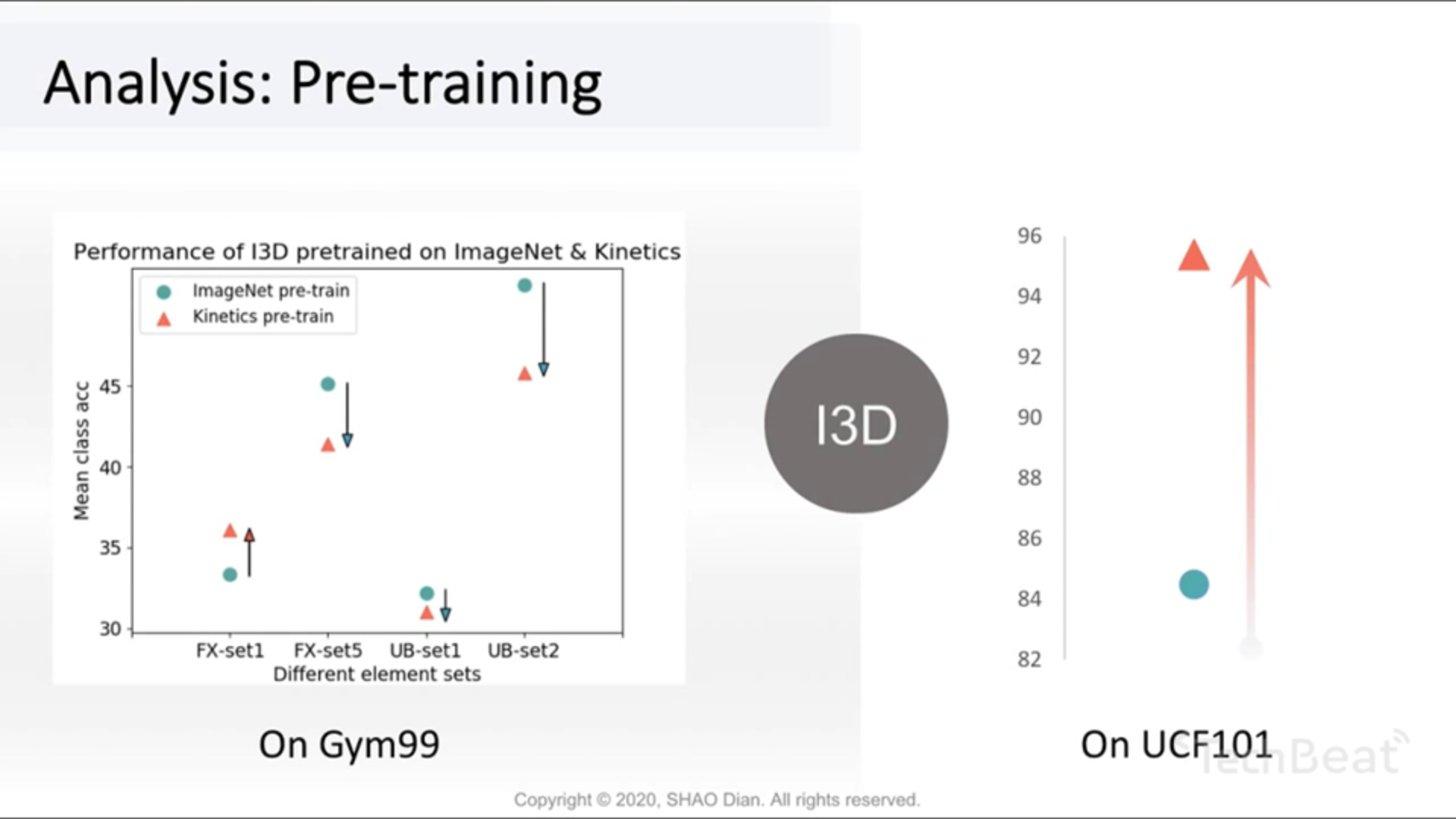
Kinetics 预训练依然没有对模型产生正面影响,accuracy 反而 drop 了。可能的猜测:Kinetics 太 coarse-grained 了,尚且不能迁移到 fine-grained 任务中。
Future Work