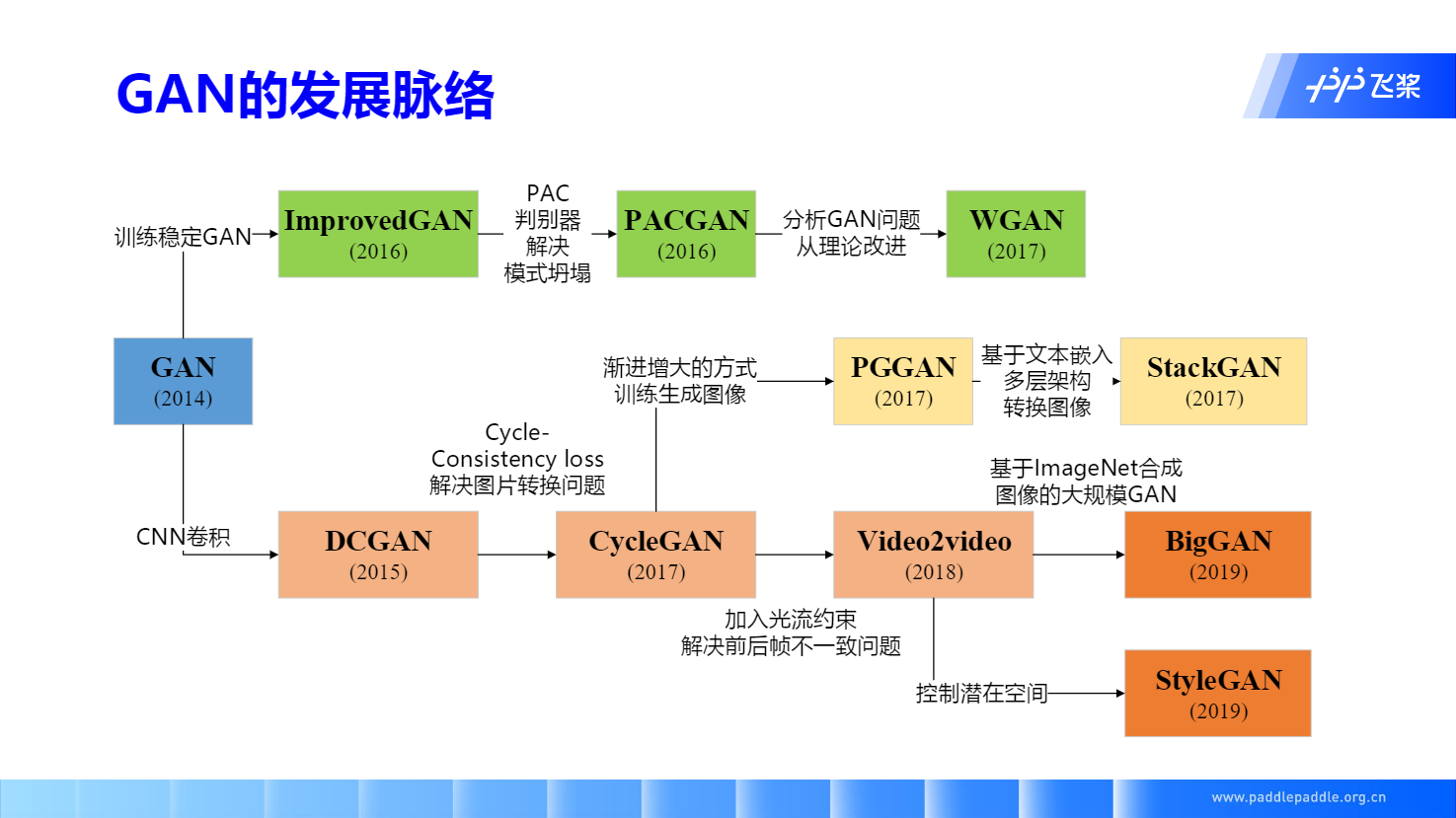
百度顶会复现营 Day 2: GAN概述,原理与改进,应用场景 (20200730)

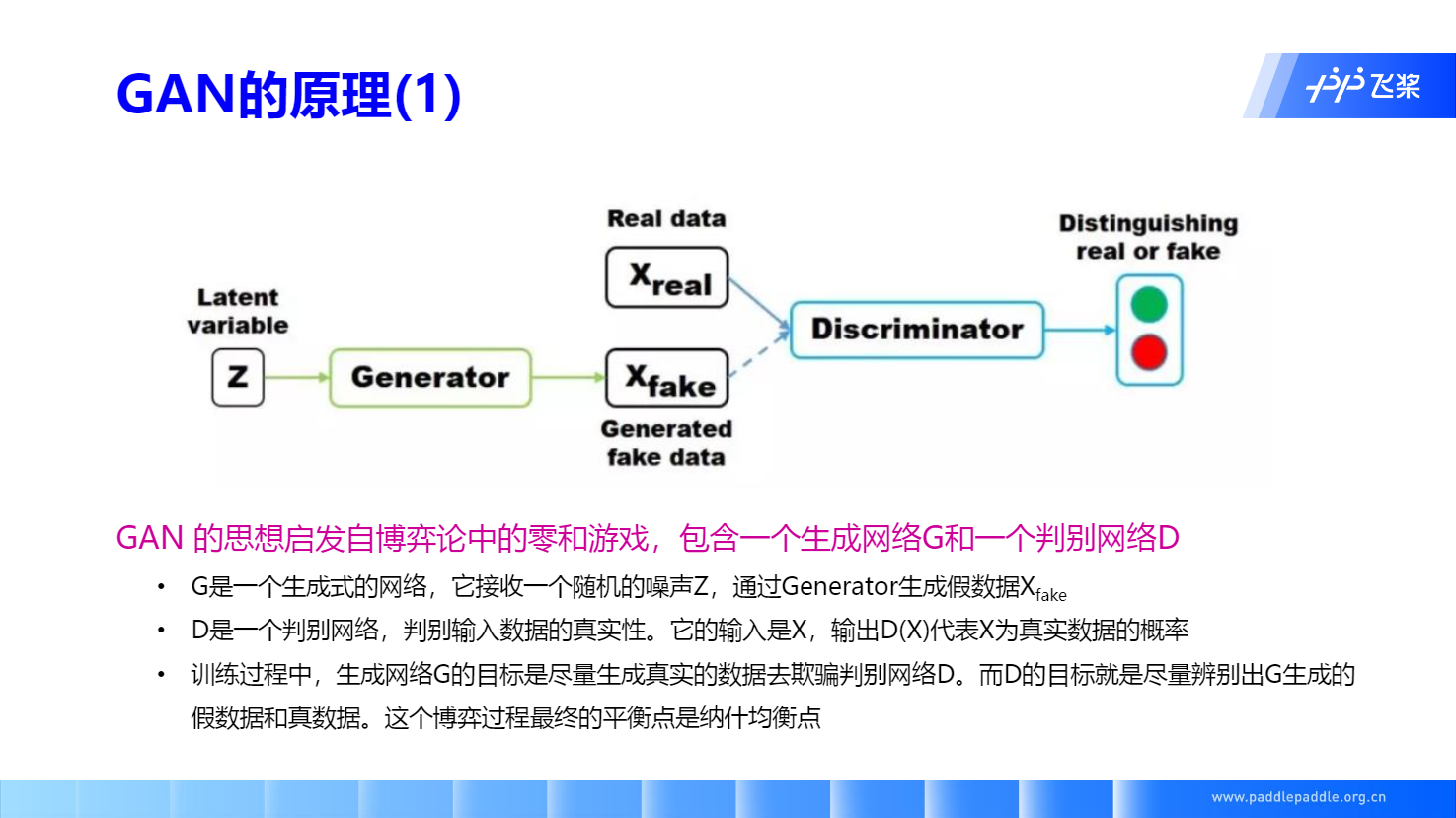
GAN 概述
GAN的核心思想: 通过生成网络 Generator 和判别网络 Discriminator 不断博弈,来达到生成类真数据的目的。

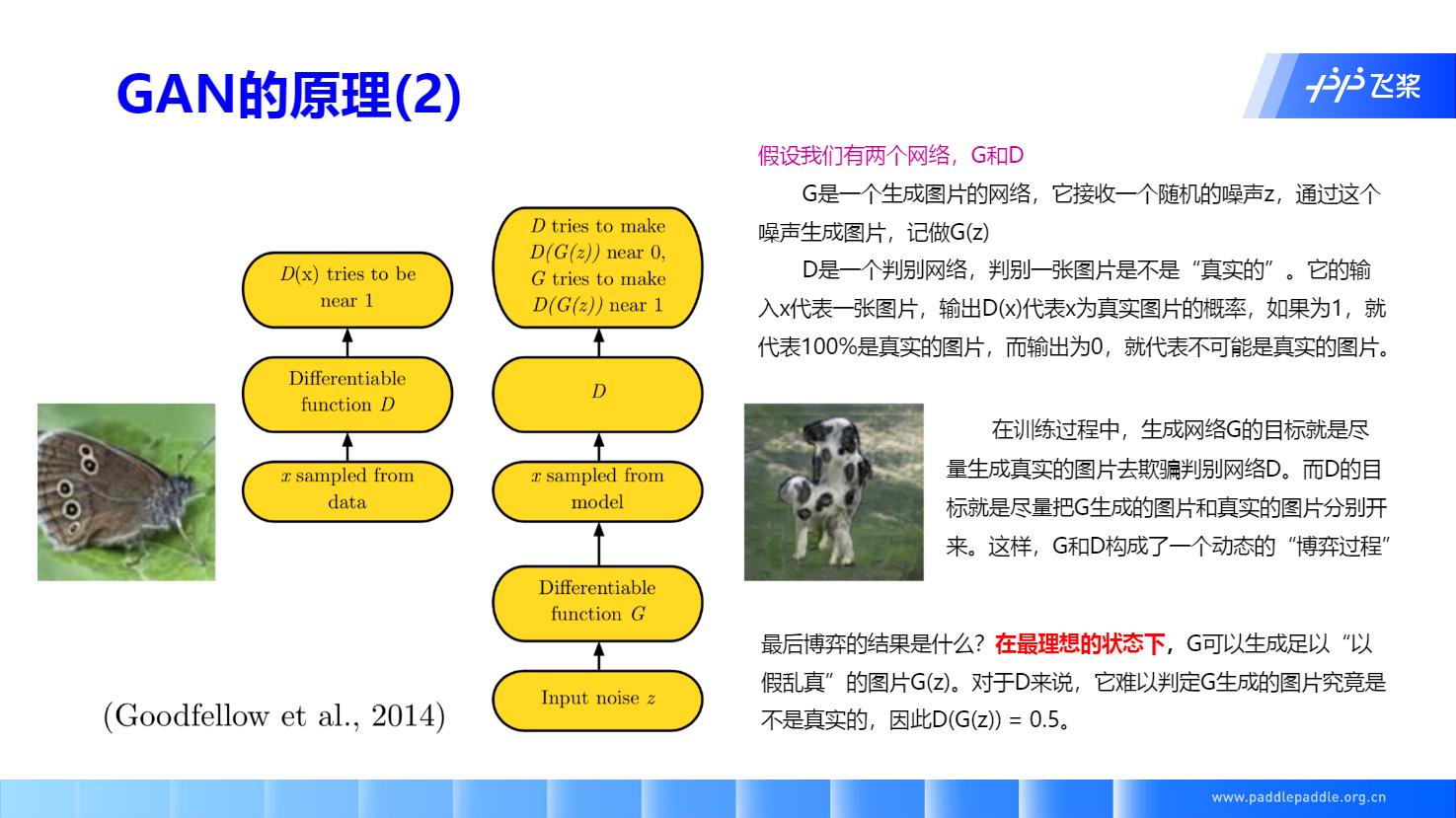

GAN 目标函数的推导
(参考文献: 网友的英文笔记)

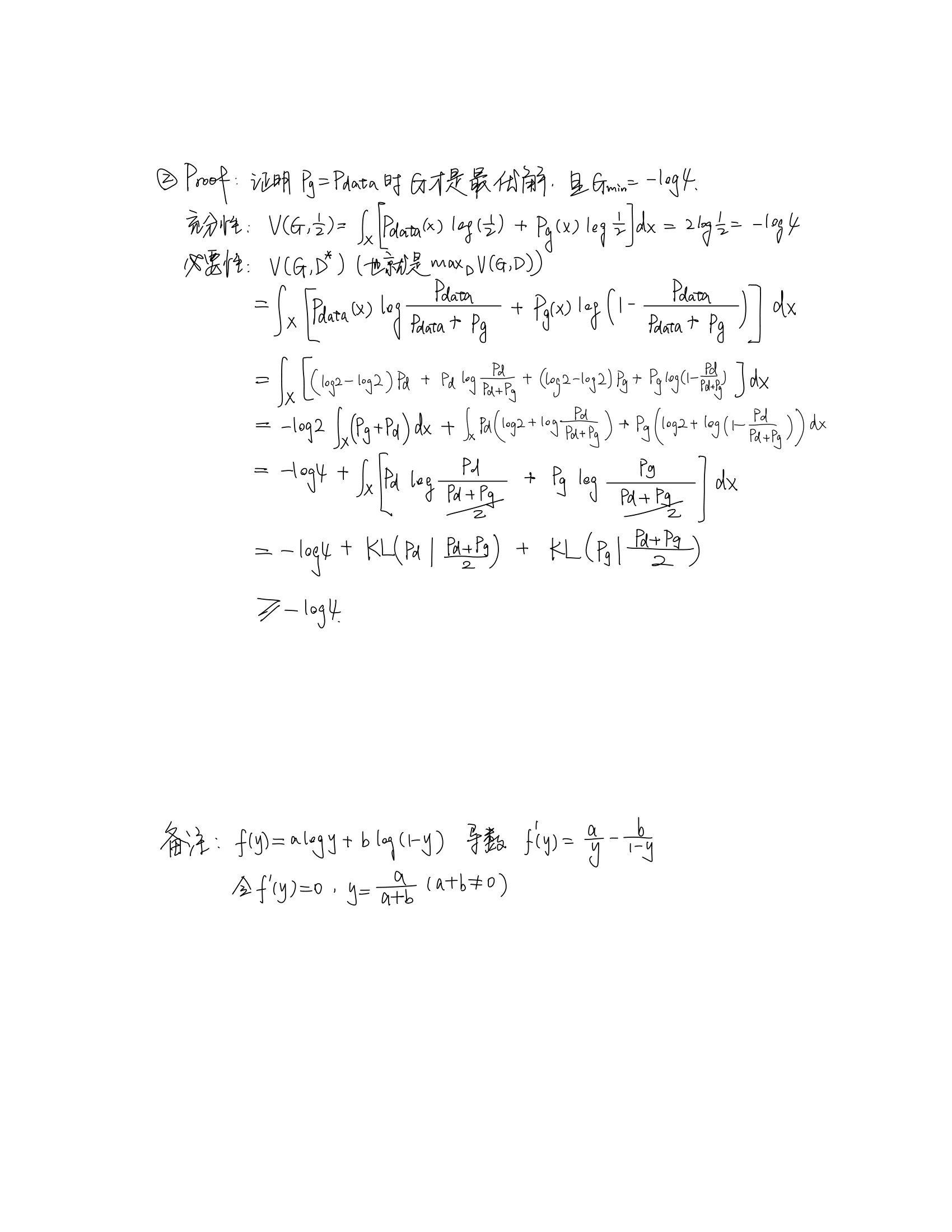
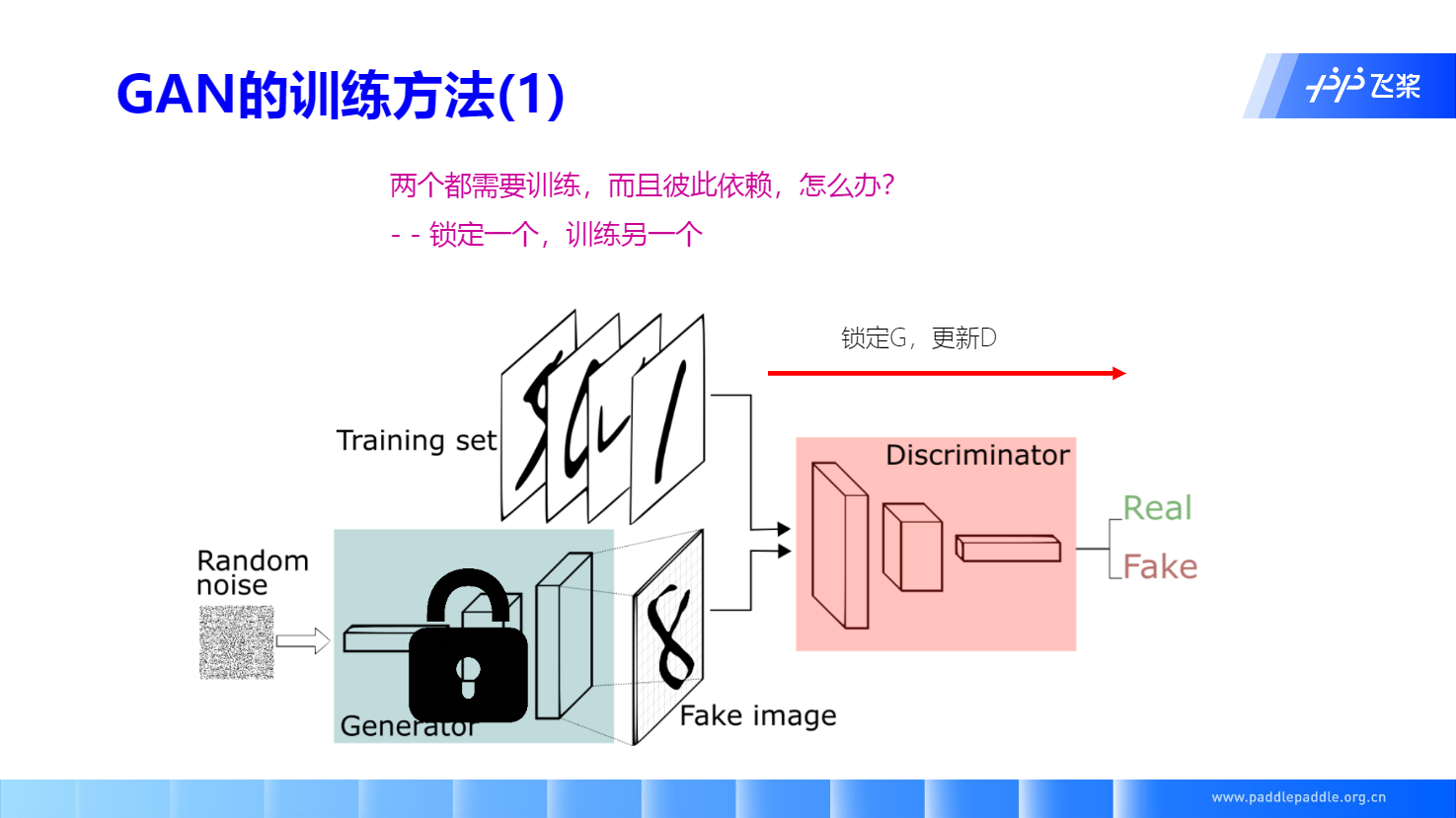
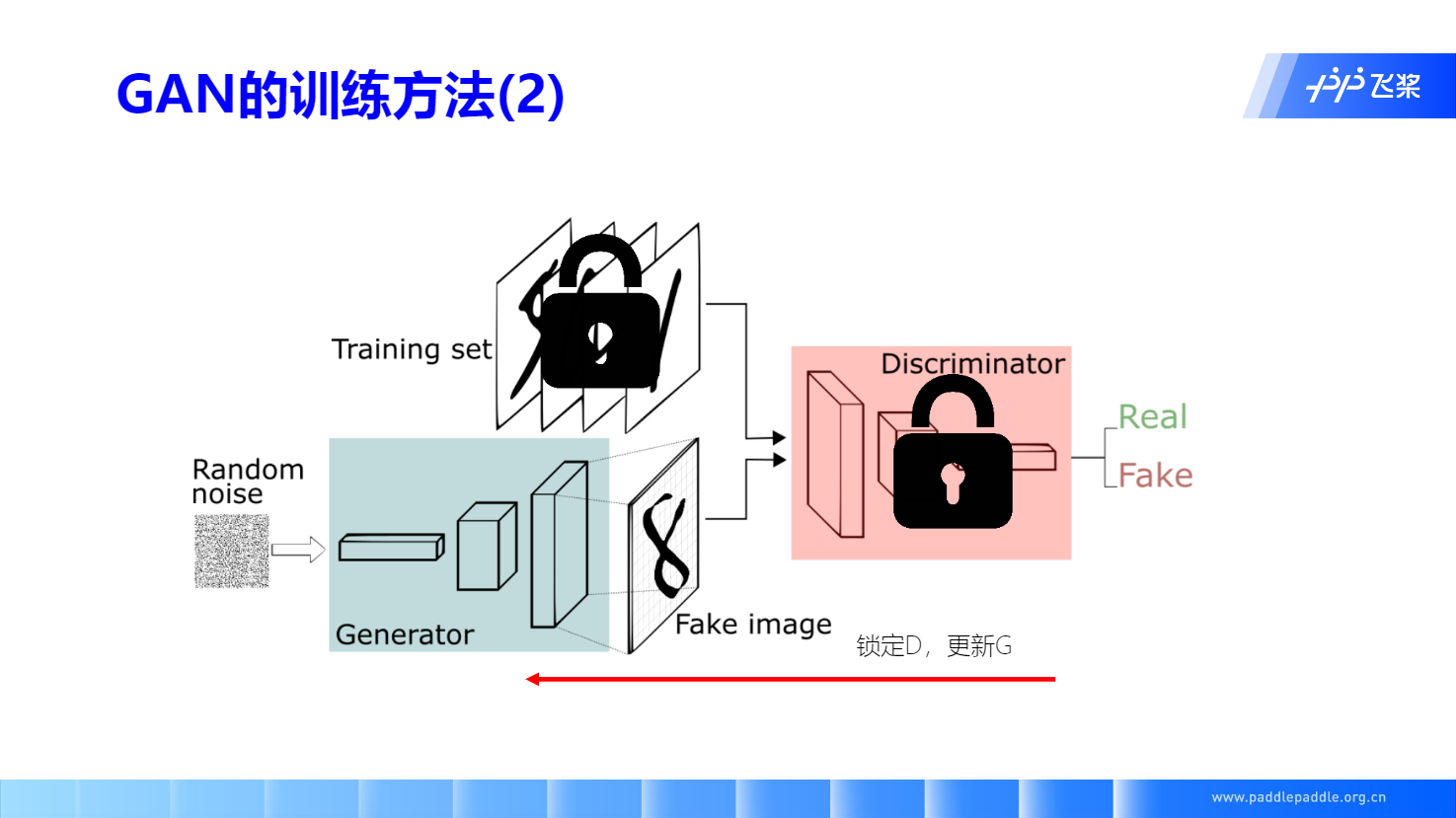
GAN 迭代训练方法: 梯度上升D,梯度下降G

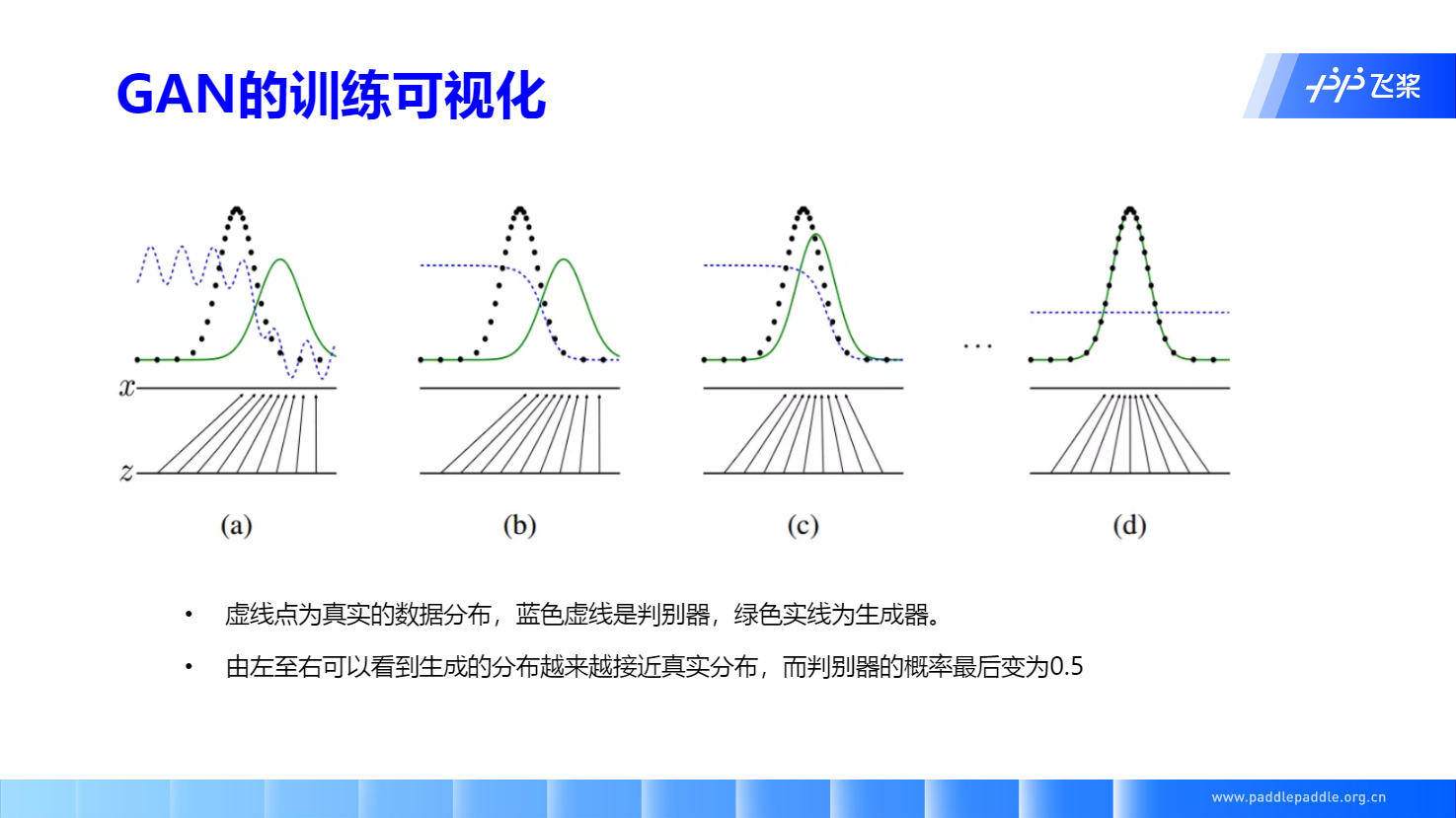
GAN 的优势

VAE 和 GAN 的区别
VAE和GAN都是生成模型,就是说从训练数据来建模真实的数据分布,然后反过来再用学到的这个模型和分布去生成、建模新的数据。
相同点:
- 生成数据的模式都是用了随机噪声(如常用的就是高斯分布)。
- 在建模分布时,都需要度量噪声和训练数据的分布差异
本质的不同点:两个方法的分布度量准则不同(即loss不同)。
VAE采用了一种较为显式的度量方法,假定训练数据由另一个分布生成,直接去度量训练数据和噪声的KL散度。由此之上发展出了ELBO理论、reparametration trick等等。
GAN则巧妙地避开了直接度量分布差异这种方式,而是让神经网络自己通过对抗的方式来学习这个距离。当判别器无法区分这两个分布时,就认为两个分布一致了。 所以本质区别是loss的计算方式不同。
鉴于两种分布度量的准则都不是完美的度量(并且并不存在完美的度量,大家都只能是逼近),所以各有各有问题。比如VAE生成的图像不够真实,GAN的训练中又会碰到例如mode collapse问题等等。
GAN 存在的问题
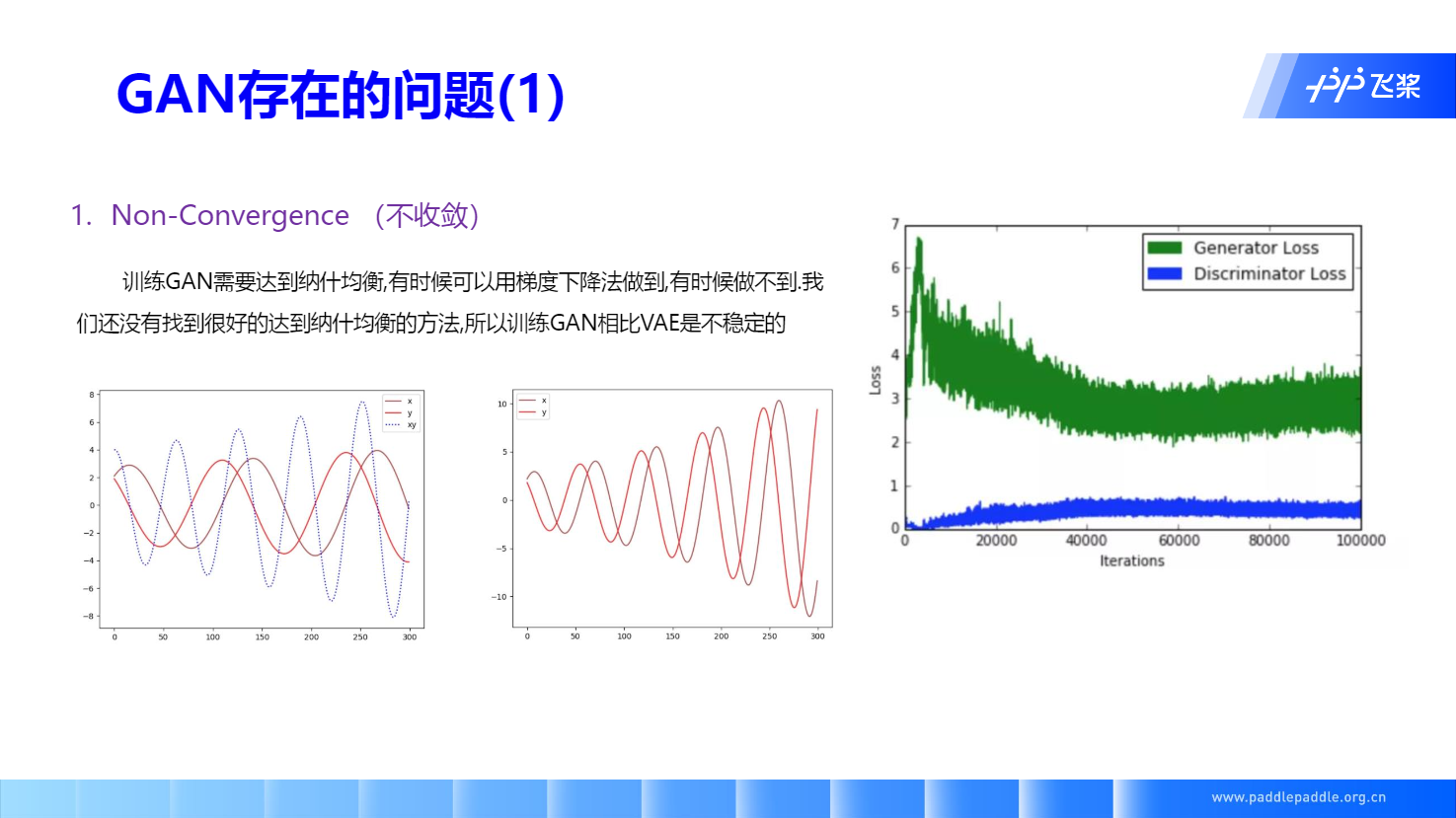
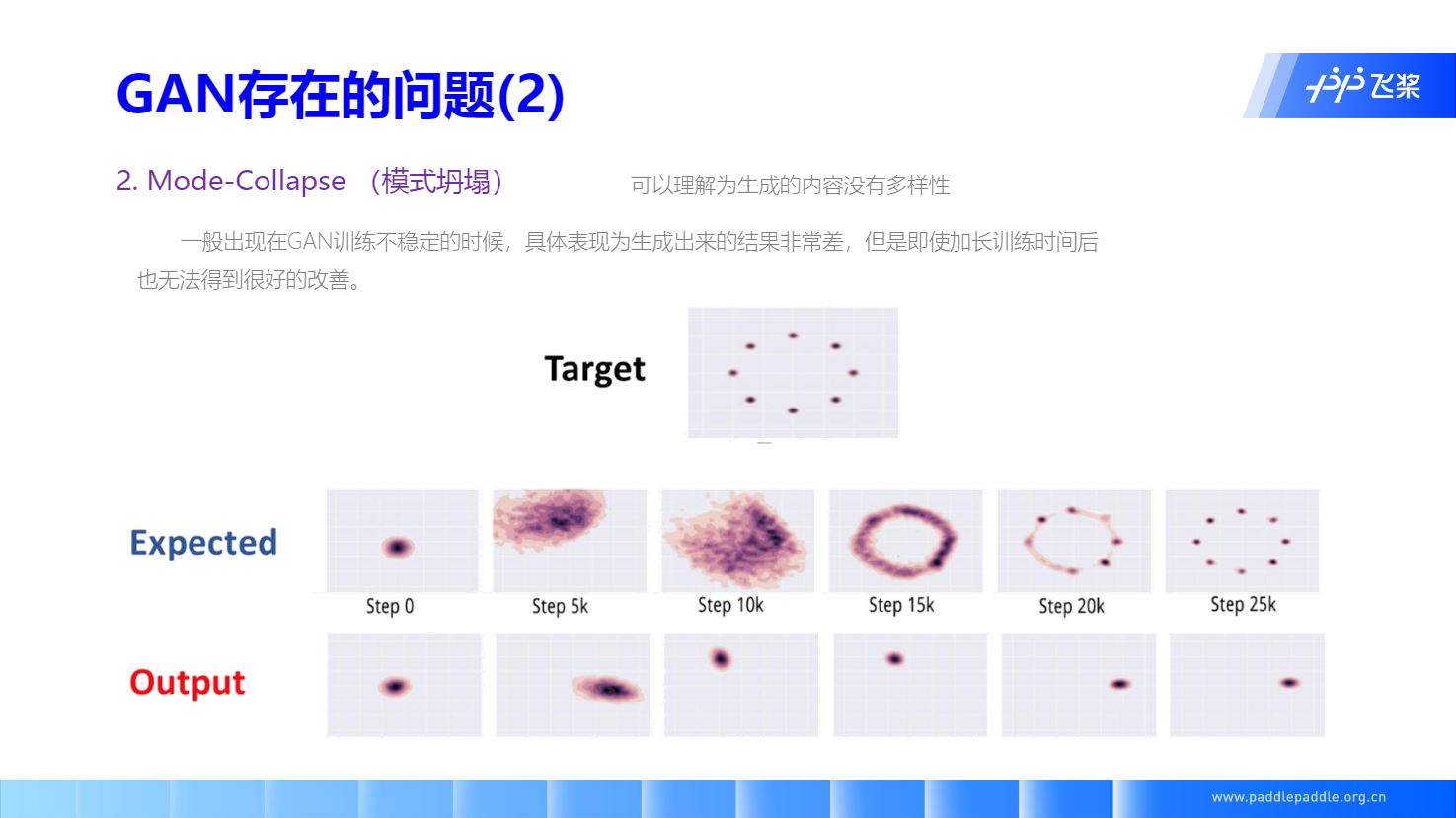

交互训练带来了模式坍塌,使得生成模型丧失了多样性。
GAN 常见的模型结构
DCGAN

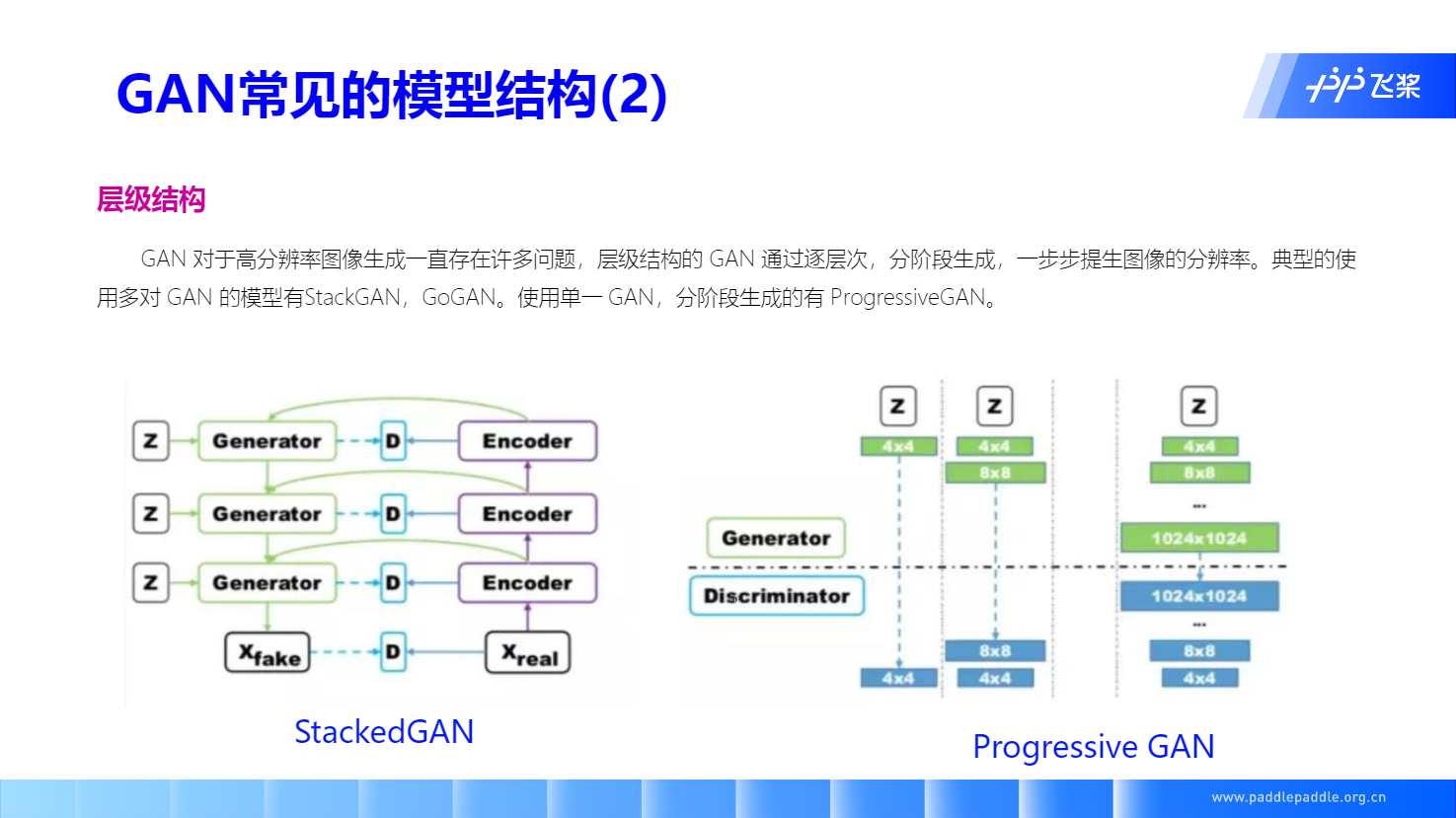
层级结构
自编码结构
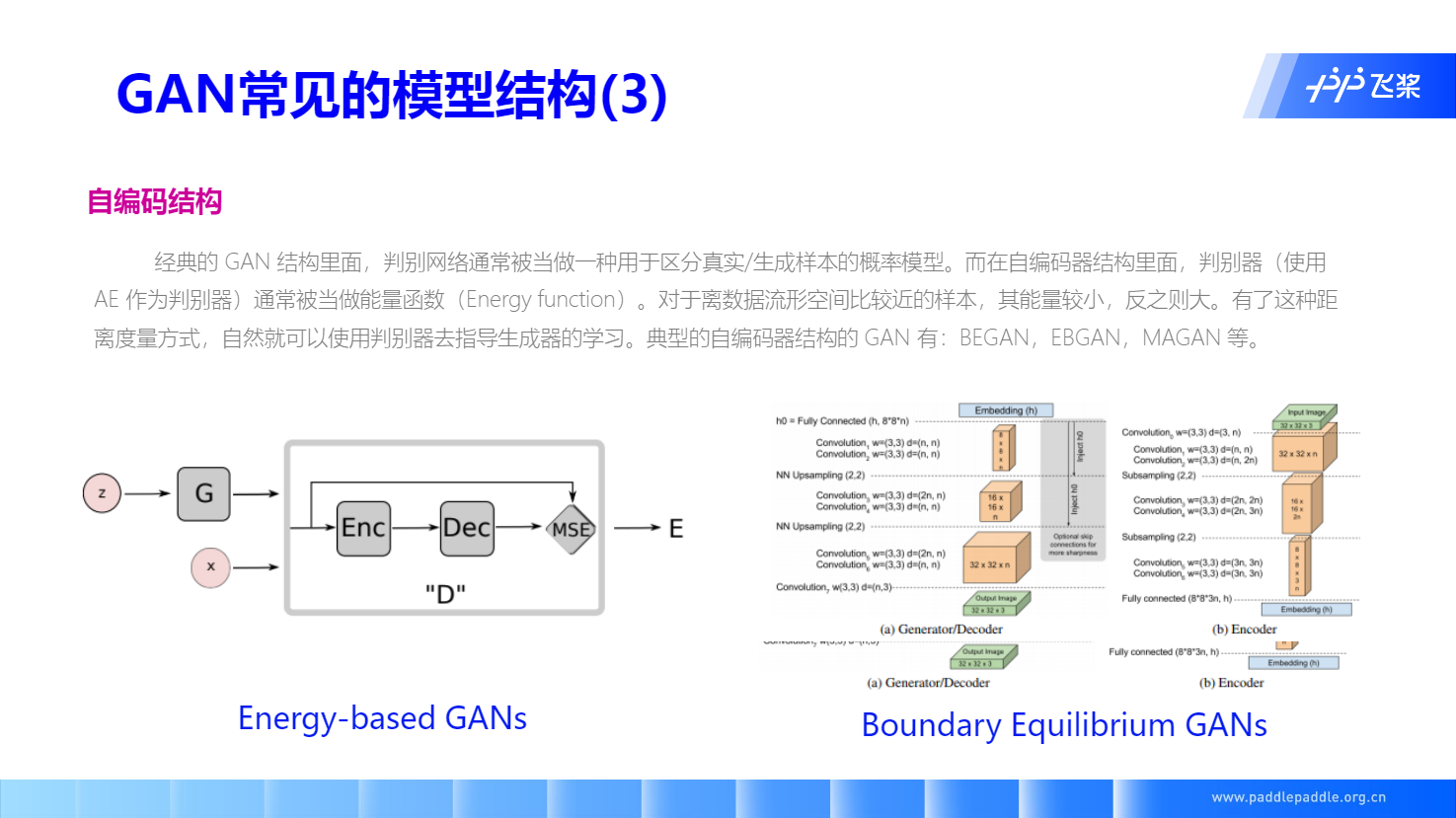
Background: 自编码
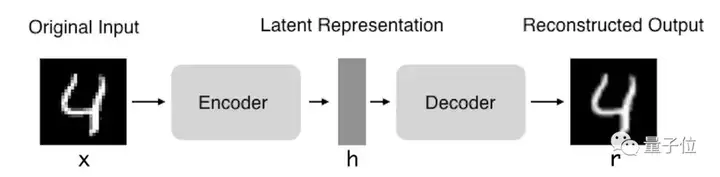
自编码器(Autoencoder,AE),是一种利用反向传播算法使得输出值等于输入值的神经网络,它先将输入压缩成潜在空间表征,然后通过这种表征来重构输出。
自编码器由两部分组成:
- 编码器:这部分能将输入压缩成潜在空间表征,可以用编码函数h=f(x)表示。
- 解码器:这部分能重构来自潜在空间表征的输入,可以用解码函数r=g(h)表示。
因此,整个自编码器可以用函数g(f(x)) = r来描述,其中输出r与原始输入x相近。我们希望通过训练输出值等于输入值的自编码器,让潜在表征h将具有价值属性。
目前,自编码器的应用主要有两个方面,第一是数据去噪,第二是为进行可视化而降维。设置合适的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影。
模式坍塌的解决方案
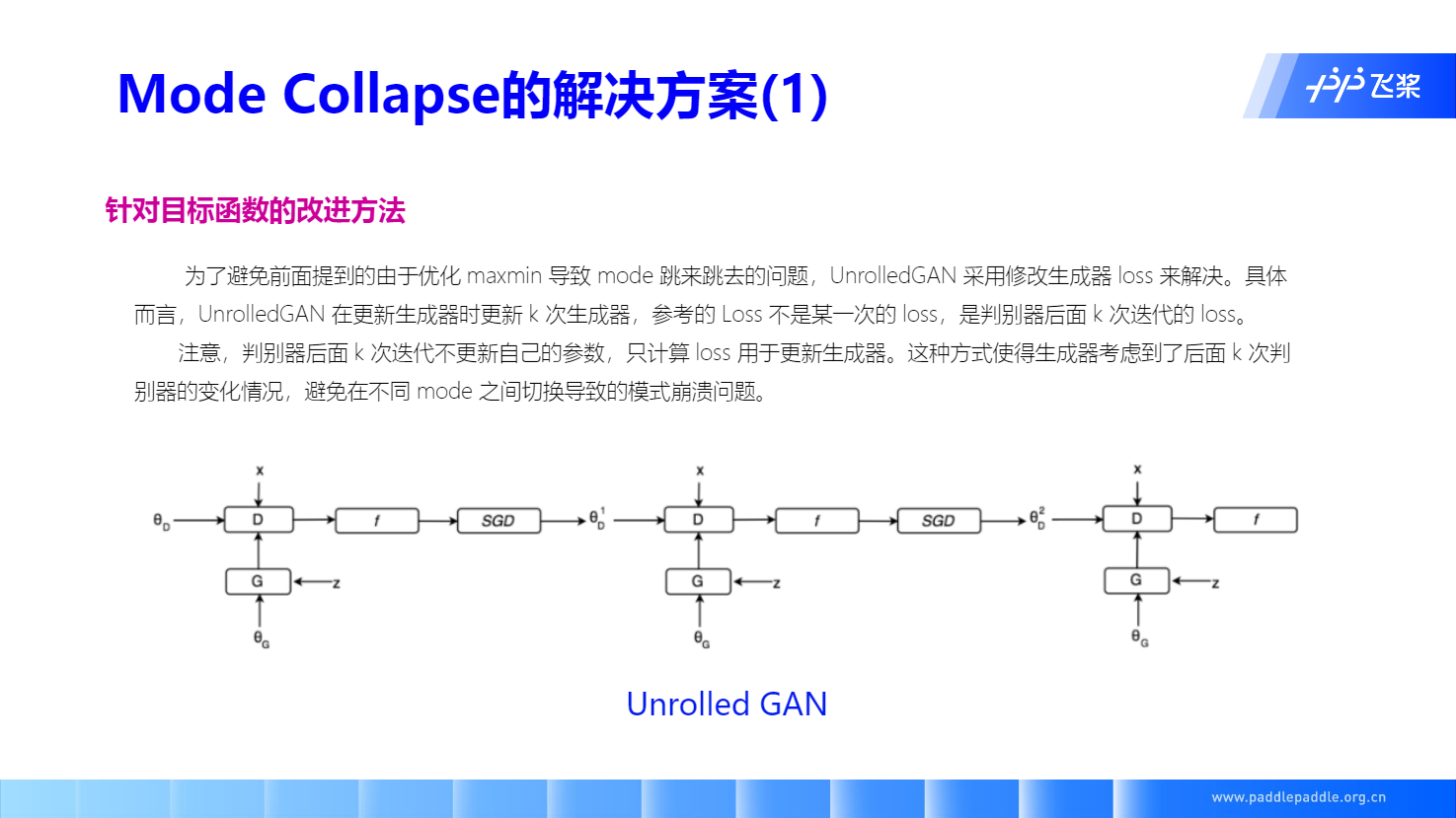
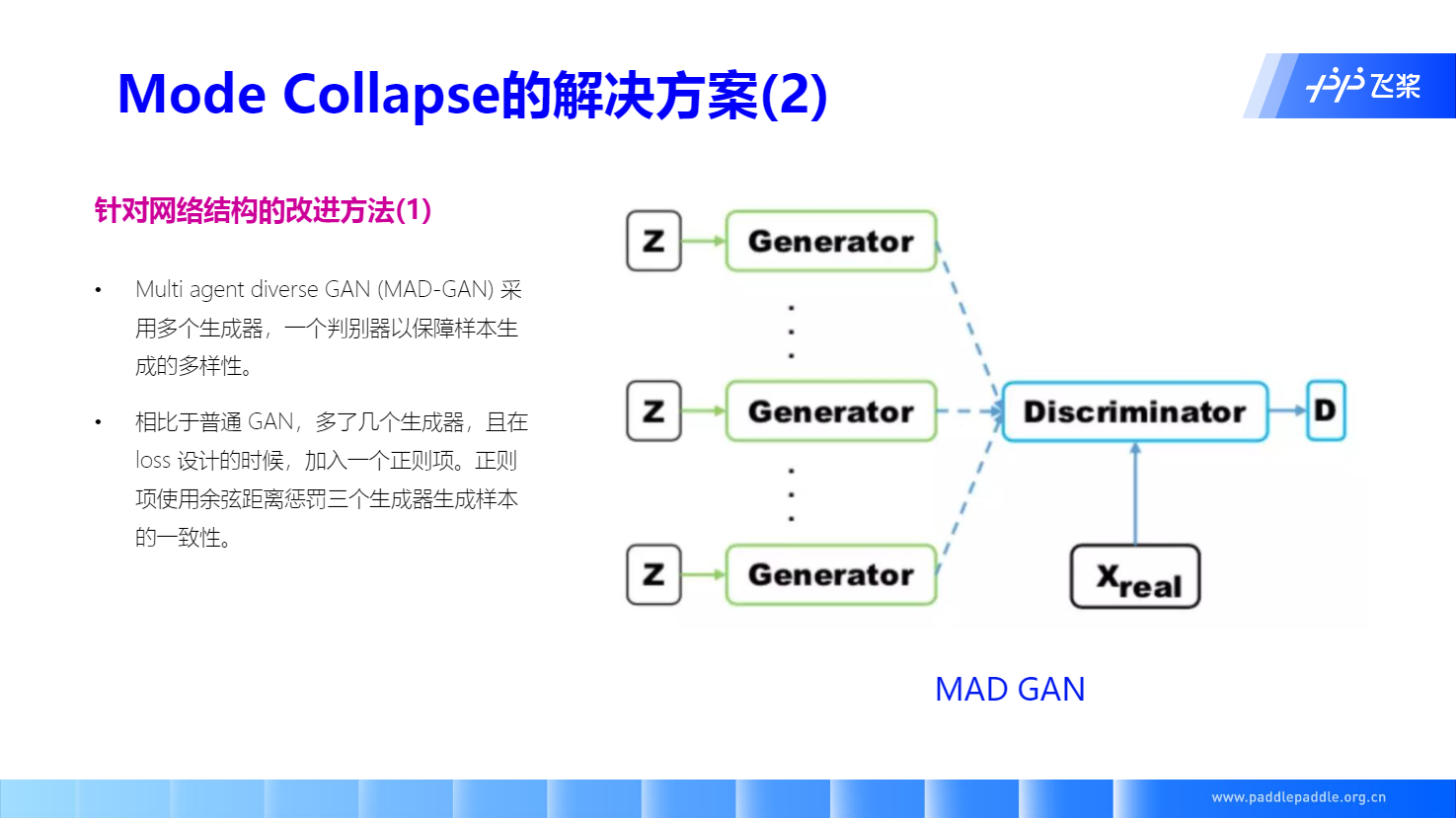
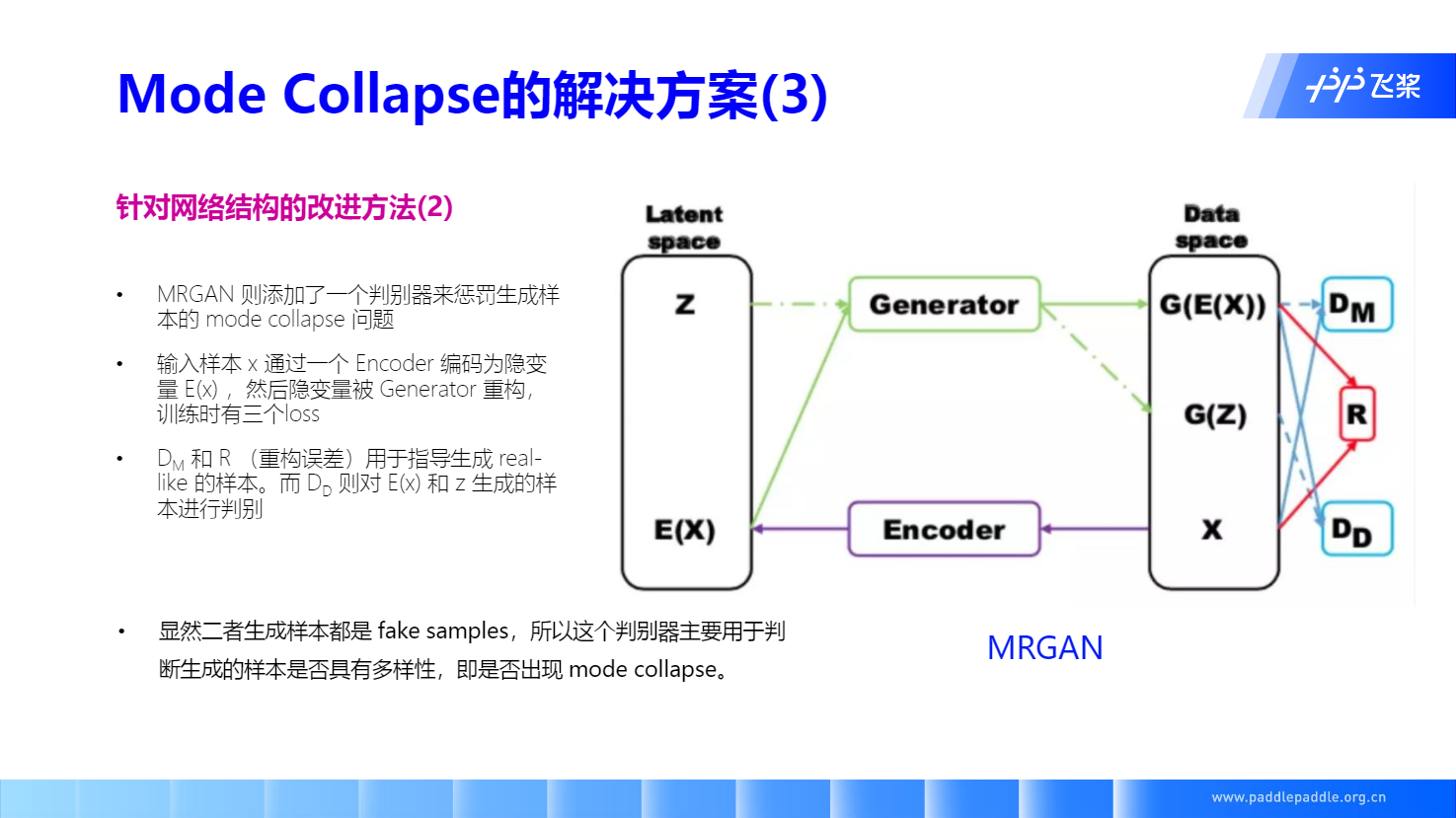
WGAN


解释一下这页不说人话的PPT:参考文献
欸,JS 散度的公式在“GAN 目标函数的推导”这一部分有见到,所以根据原始GAN定义的判别器loss,我们可以得到最优判别器的形式;而在最优判别器的下,我们可以把原始GAN定义的生成器loss等价变换为最小化真实分布
与生成分布
之间的JS散度。我们越训练判别器,它就越接近最优,最小化生成器的loss也就会越近似于最小化 P_r 和 P_g 之间的JS散度。
但是最小化JS散度的时候,由于 P_r 和 P_g 很有可能完全不一致(两个分布完全没有重叠的部分,或者它们重叠的部分可忽略),那么他们的JS散度是一个常数log2,梯度为0。
原始GAN不稳定的原因:判别器训练得太好,生成器梯度消失,生成器loss降不下去;判别器训练得不好,生成器梯度不准,四处乱跑。只有判别器训练得不好不坏才行。



GAN 的应用场景
图像合成 Image Synthesis
图像风格迁移 Image-to-Image
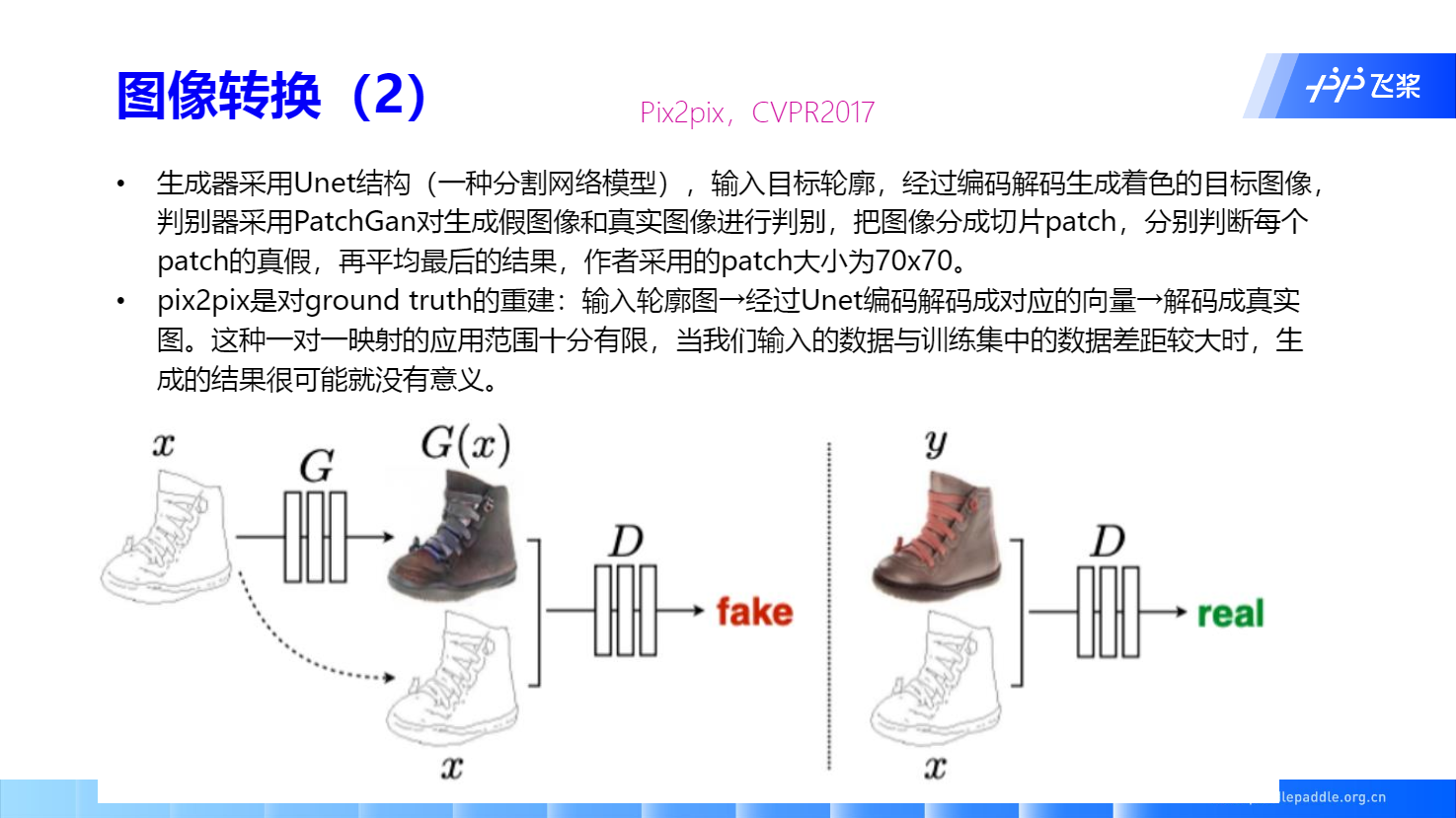
Pix2pix

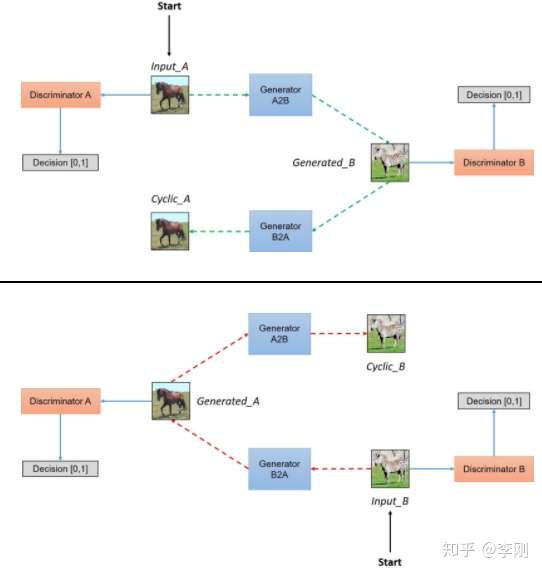
CycleGAN 无配对数据风格迁移

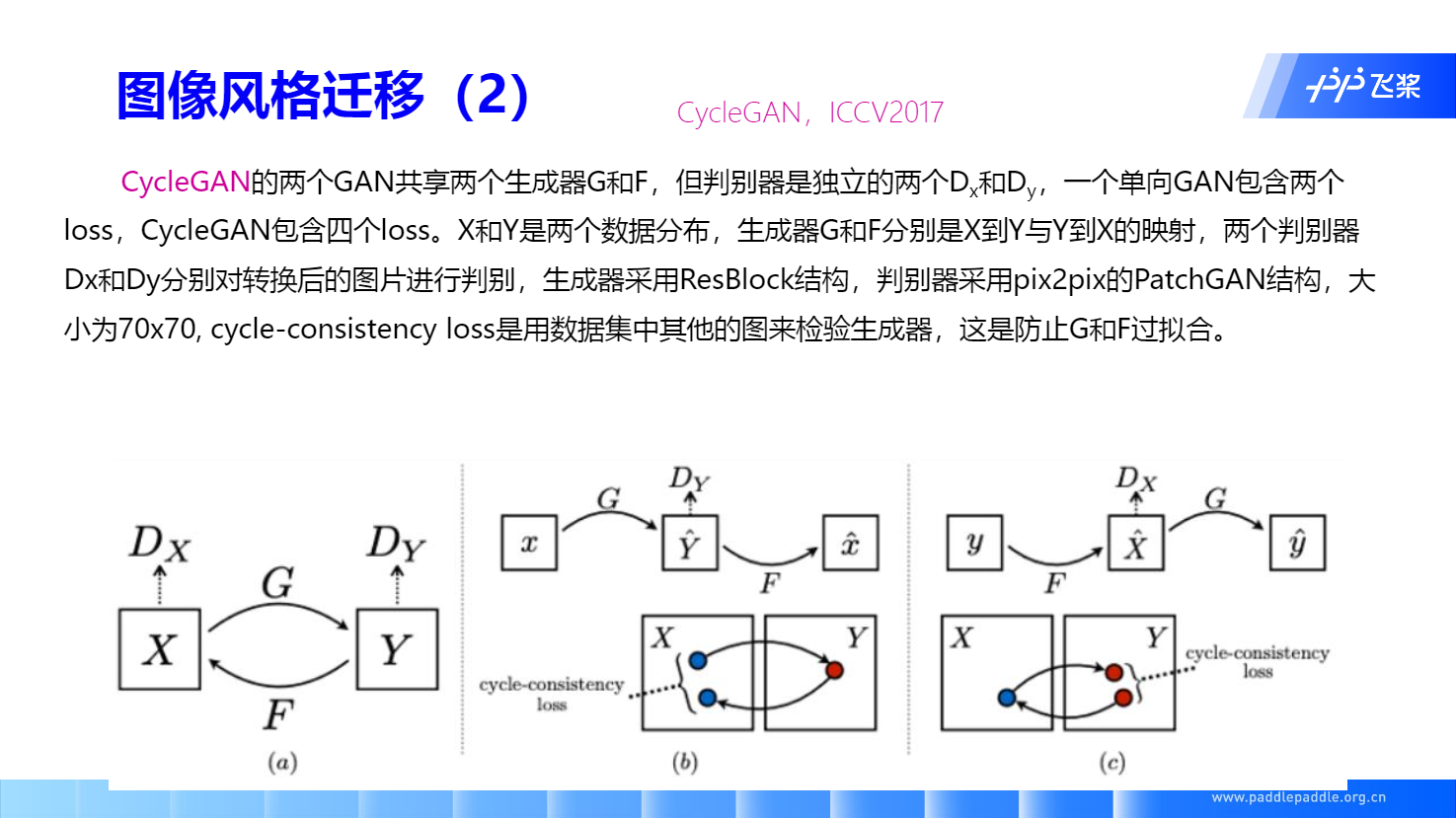
每个discriminator单独判断各自domain的数据是否是真实数据。

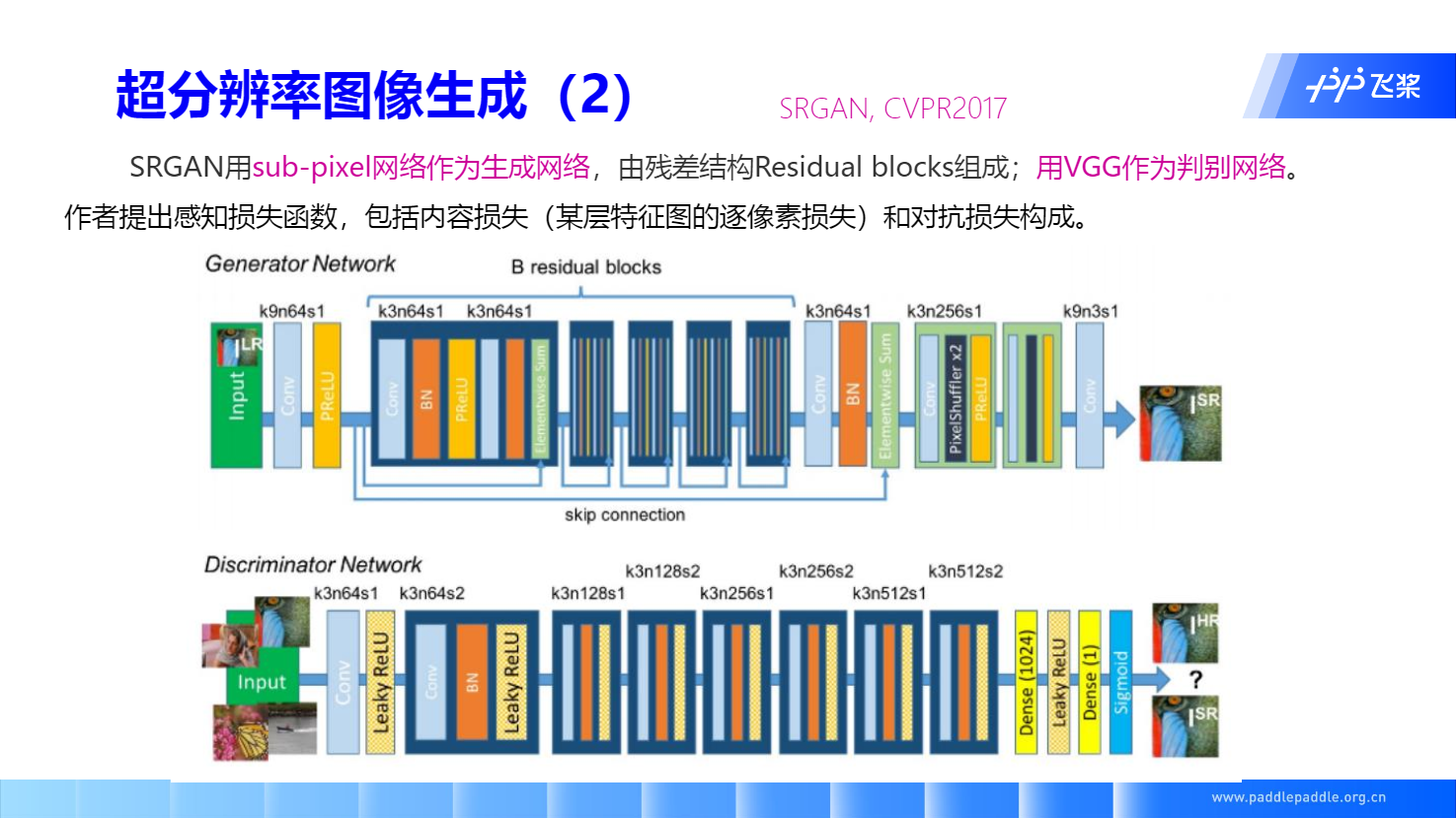
超分辨率图像生成
SRGAN

Background: Sub-pixel Convolution
第一个白色矩阵(低分辨率图片)是输入层。第二个、第三个白色张量是隐藏层,做步长为1的正常卷积。如果对原图放大3倍,那么就要生成3^2=9 (通道数)个相同尺寸的特征图。然后将9个相同尺寸的特征图拼接成一个x3的大图,也就是对应的 sub-pixel convolution 操作;要放大r倍的话,那就生成r方个channel的特征图,这里的 r 也可以称为上采样因子
