BERT 模型解读
参考文献:贪心学院NLP系列课程:BERT模型
BERT 模型结构
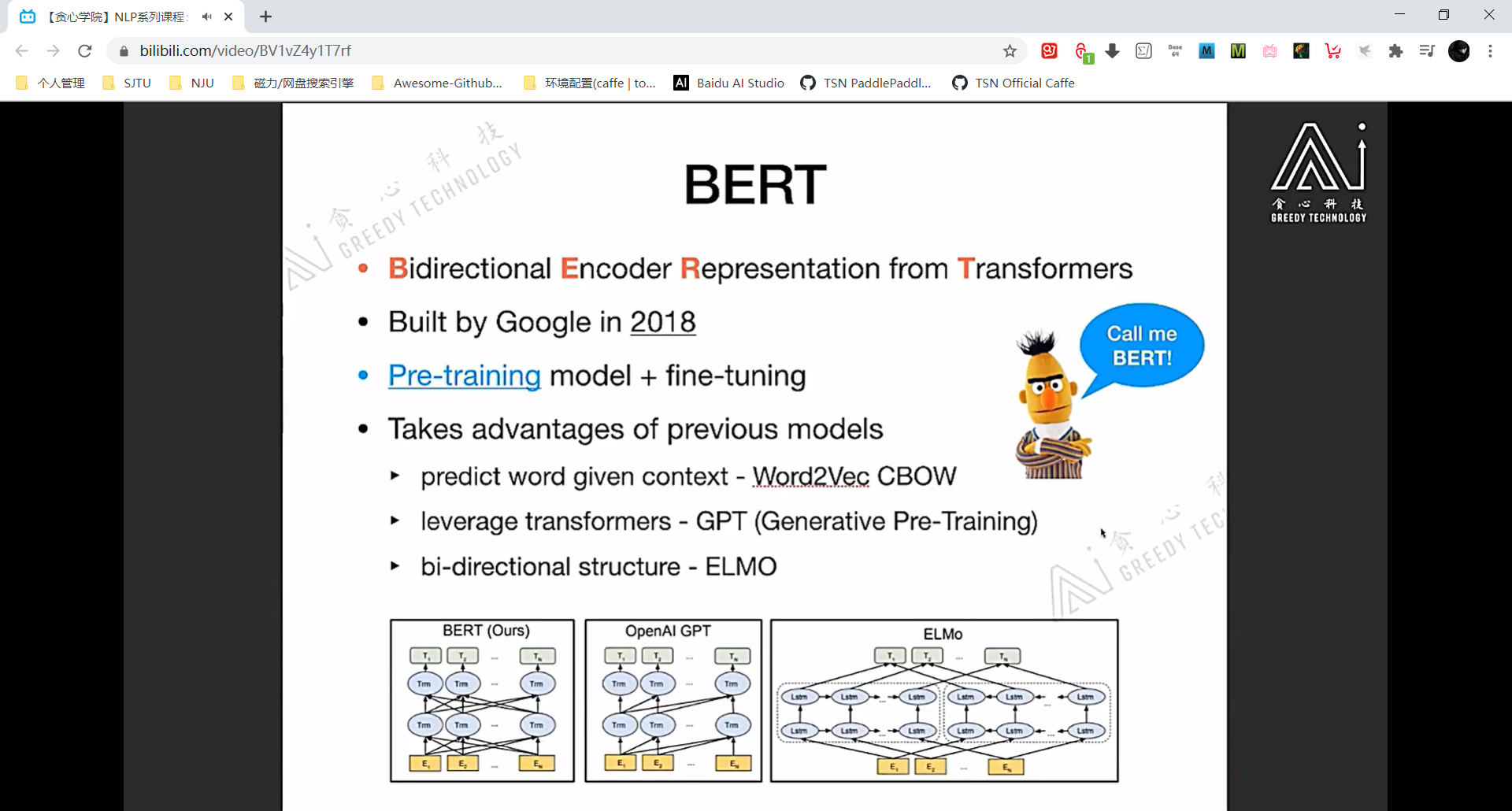
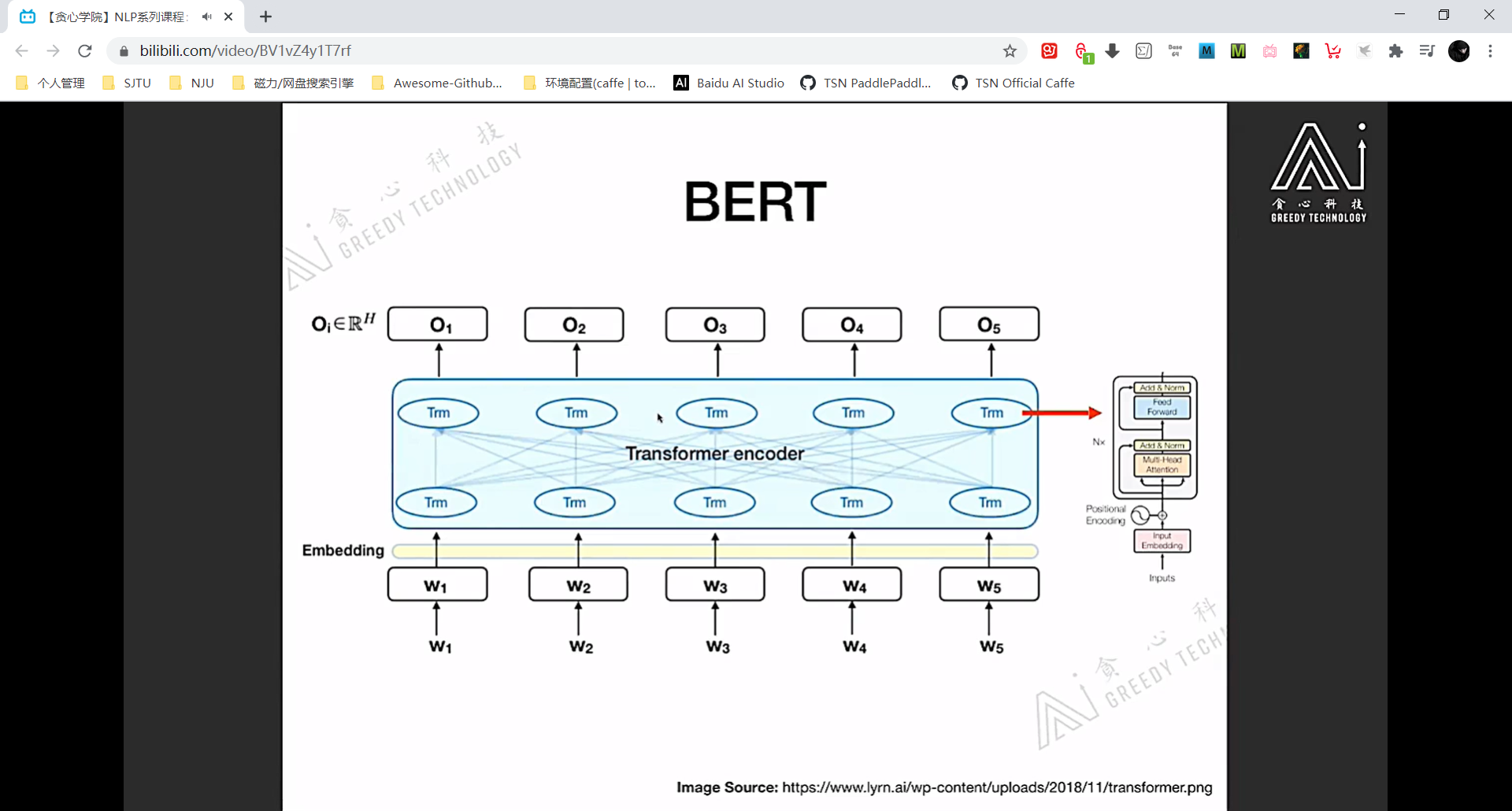

注意看 BERT 的 segment embedding 标记了两个句子 A 和 B。
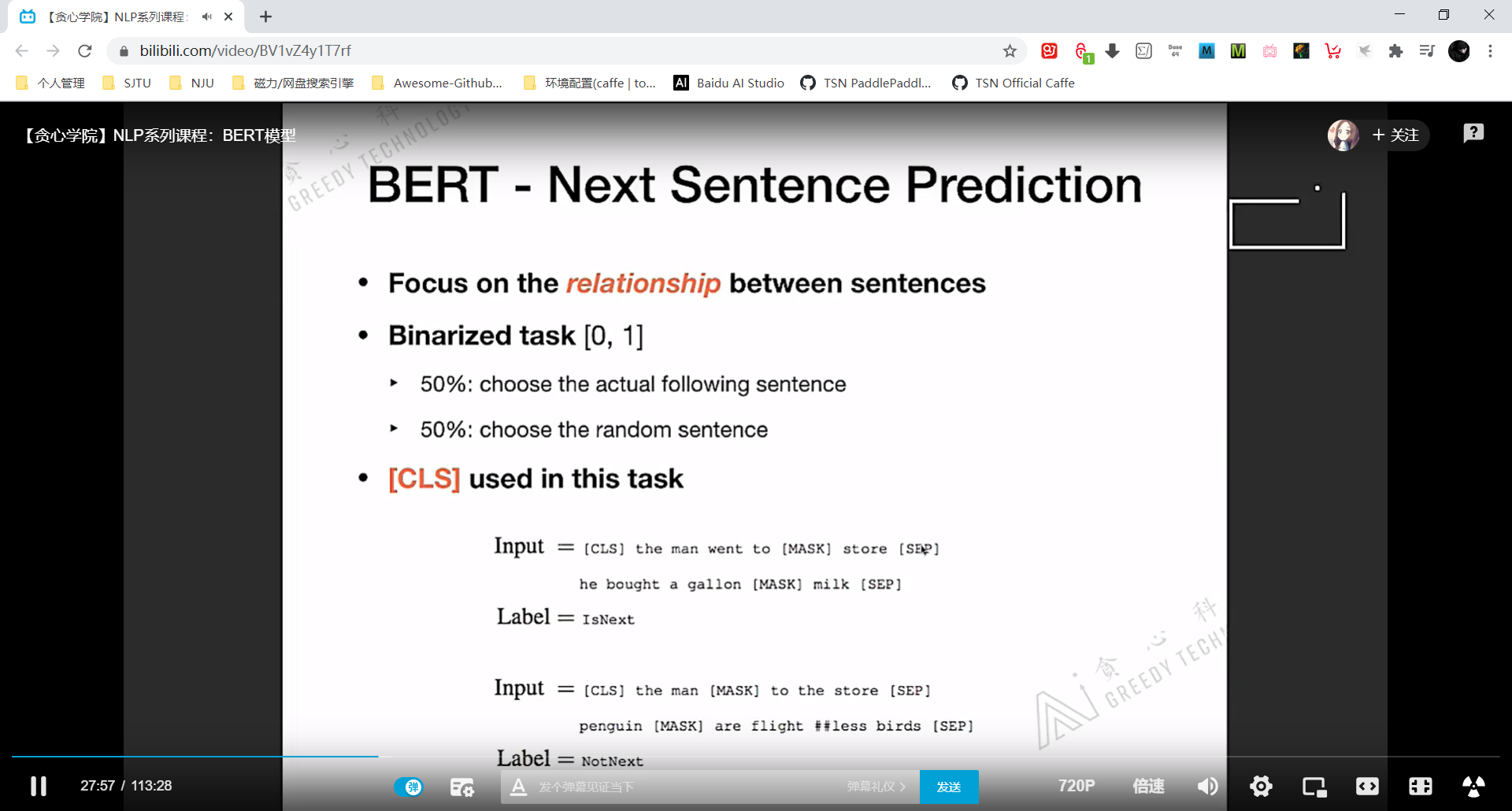
BERT 预训练的两个任务


masked language model 类似完形填空。
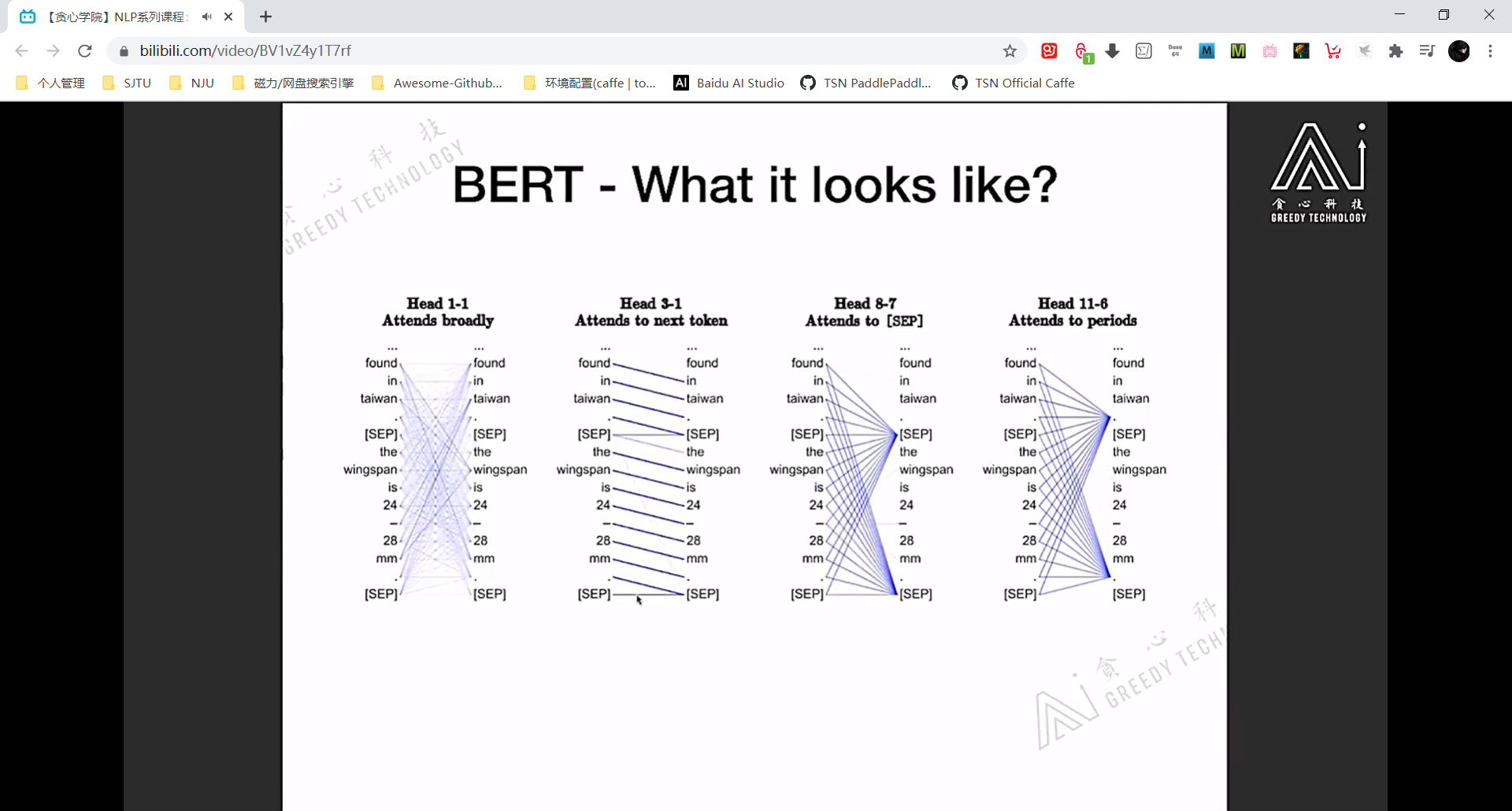
上图说明了 self-attention module 具备一定的可解释性
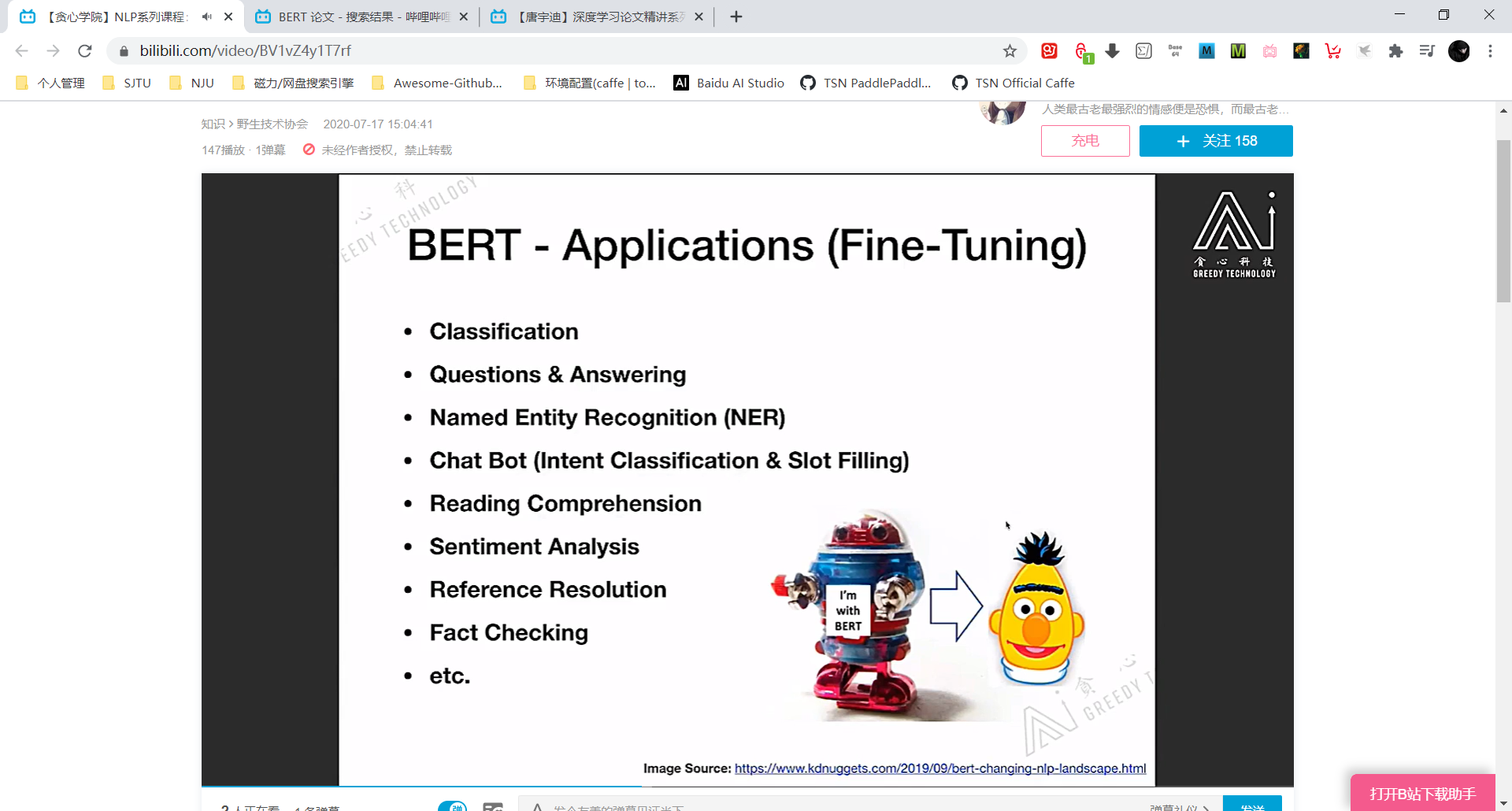
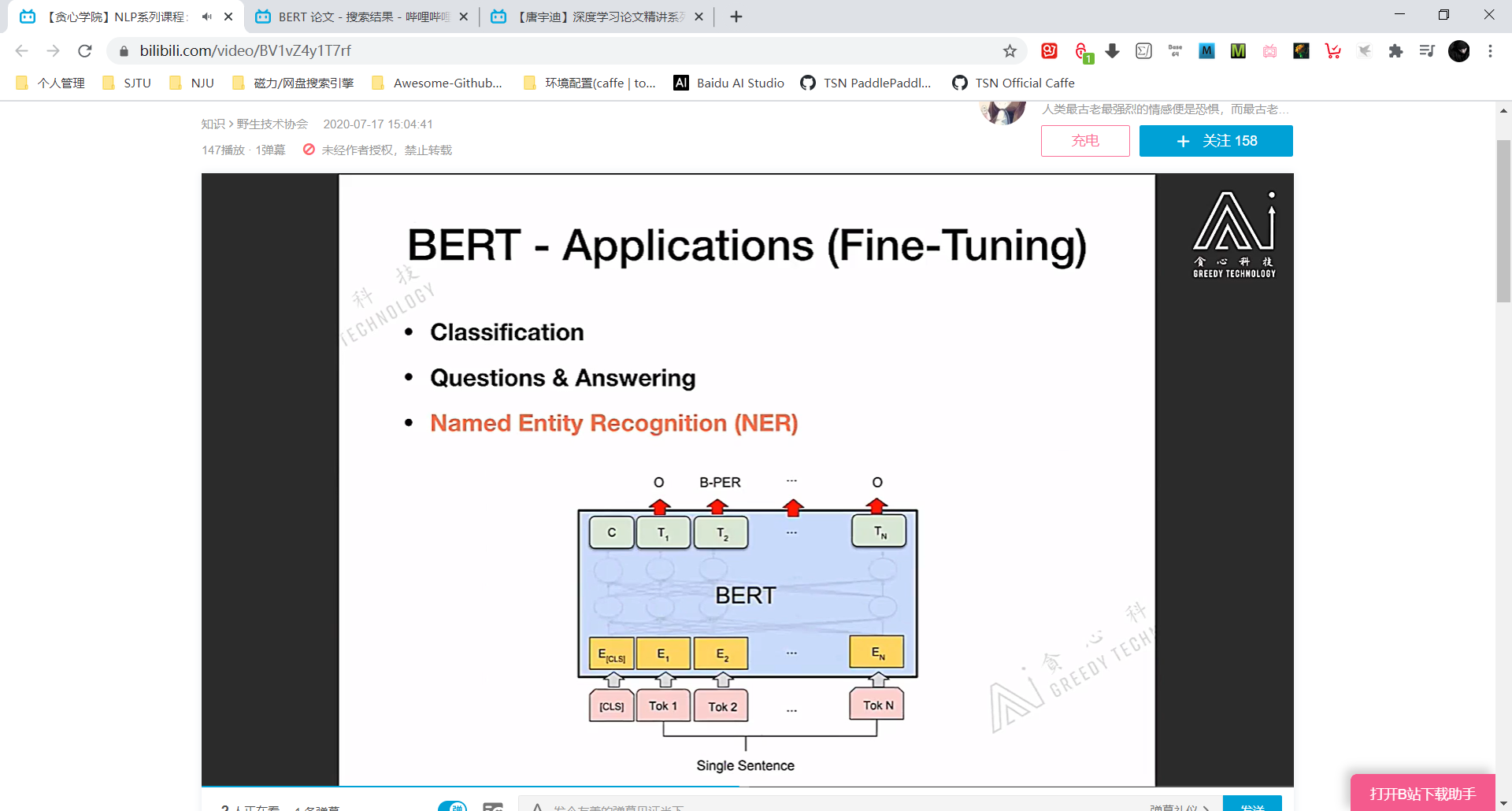
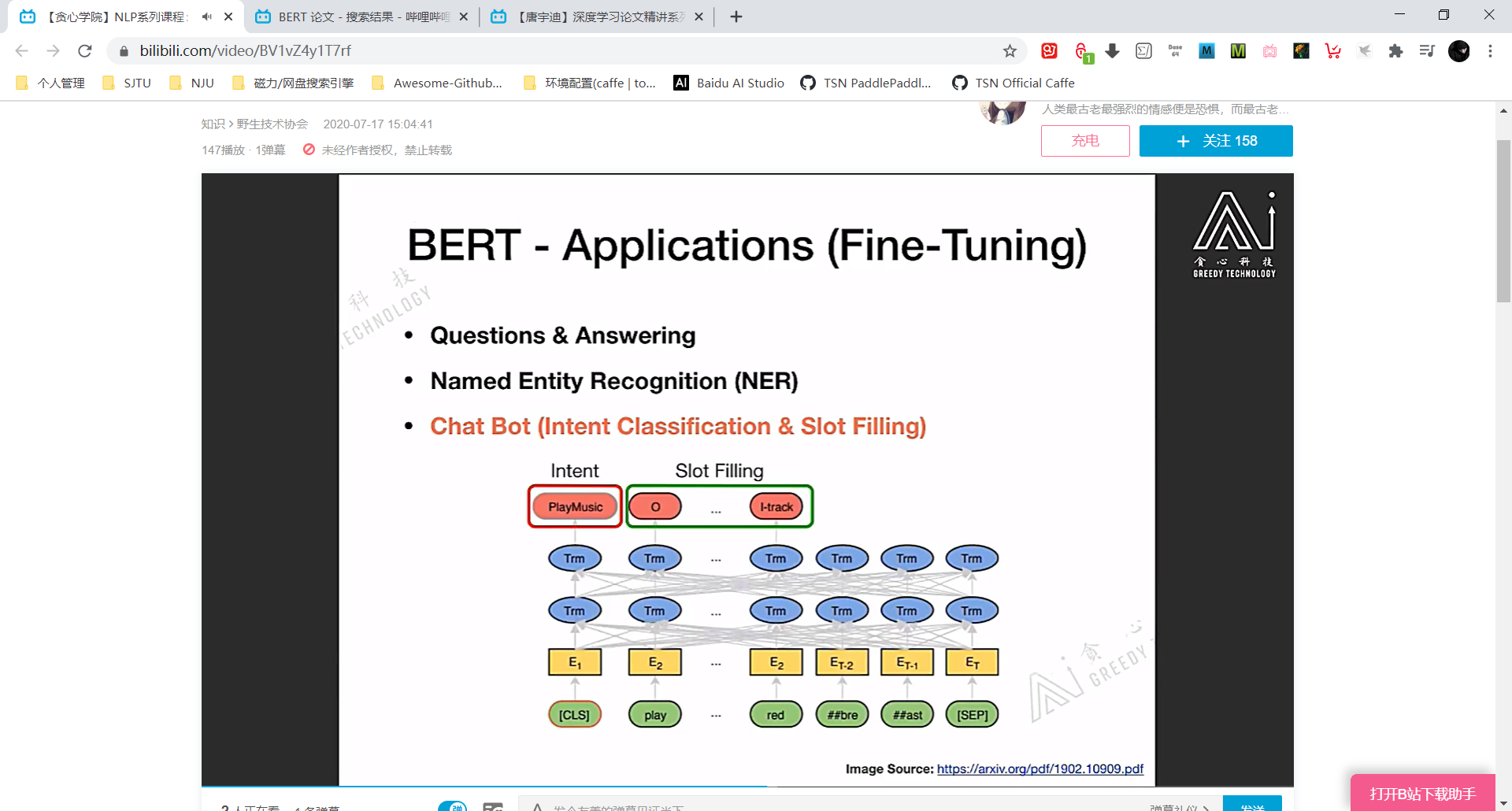
BERT 的应用 (没有讲具体的损失函数之类,只是讲 Idea)
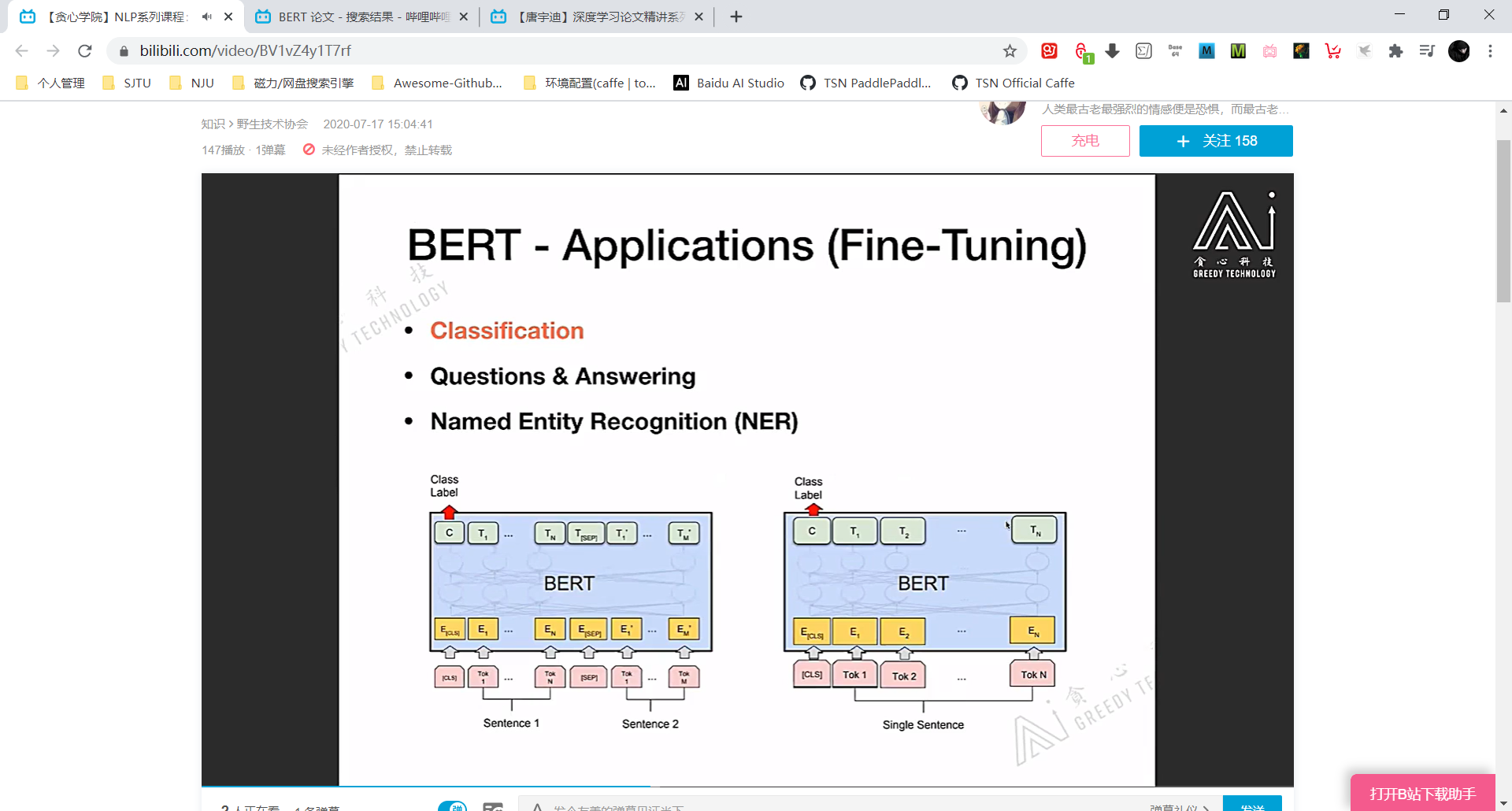
分类任务时直接对 [CLS] 对应的 embedding vector 进行微调就可以。因为 [CLS] 相当于是对整个 input token sequence 的全局特征表达。
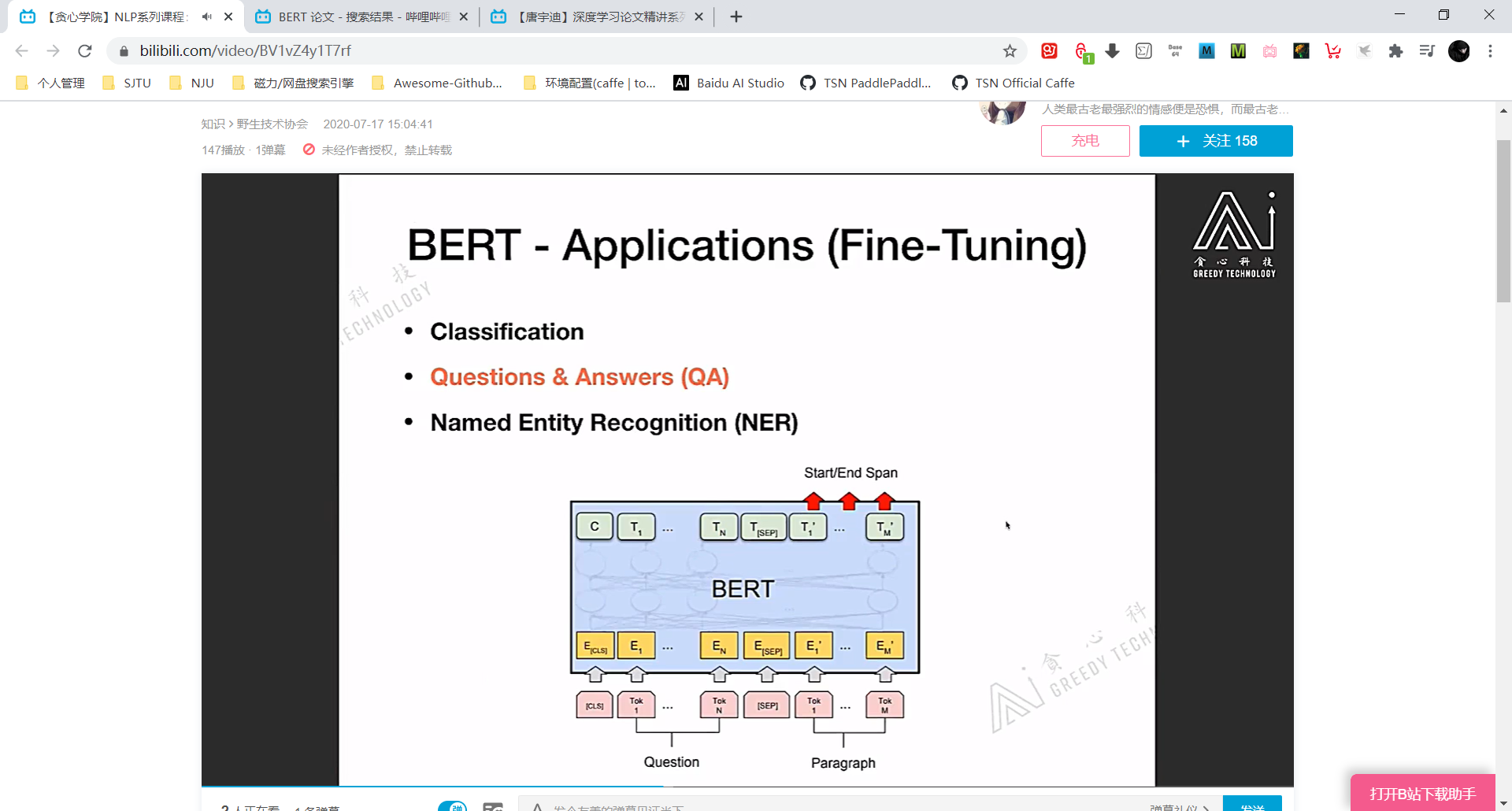
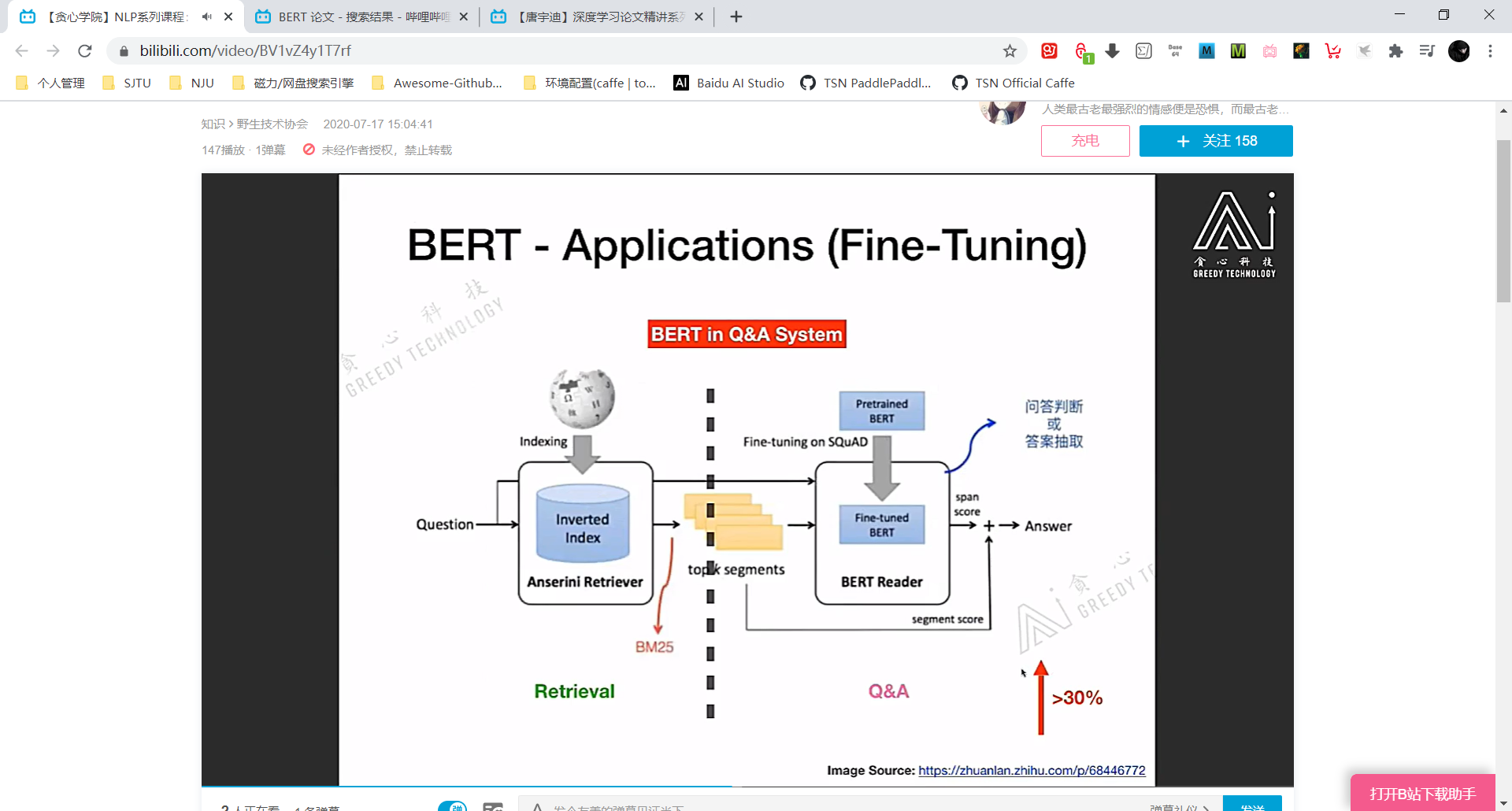
QA任务时,Question 代表问题 Paragraph 代表备选语料,从 Paragraph 中找到 Question 的答案。
random initialize 两个 vector, 记为 start vector 和 end vector,这两个 vector 是需要梯度学习的。
将 Question (A) + Paragraph (B) 输入 BERT,每个 token 都会有自己的 hidden vector。
将 start/end vector 分别与 Paragraph 的各个 hidden vector 求 dot-product,把结果最大的 token 对应的 index 分别记为 start/end index,将 Paragraph 对应 start/end index 之间的 token 取出来,这就是针对 Question 的结果。
reading comprehension 任务就是QA加强版。
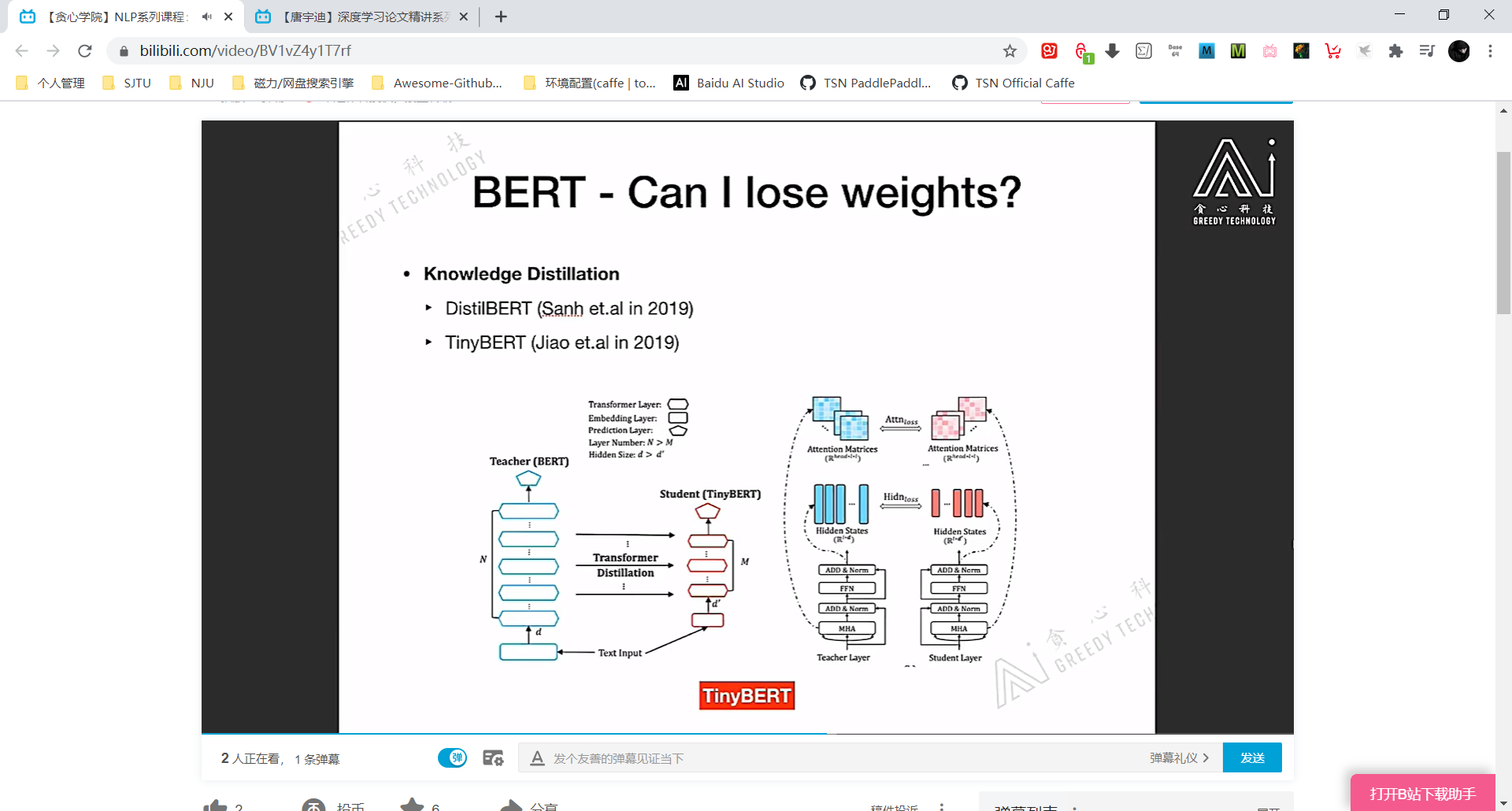
减少BERT参数量 —— 蒸馏
BERT 的鲁棒性
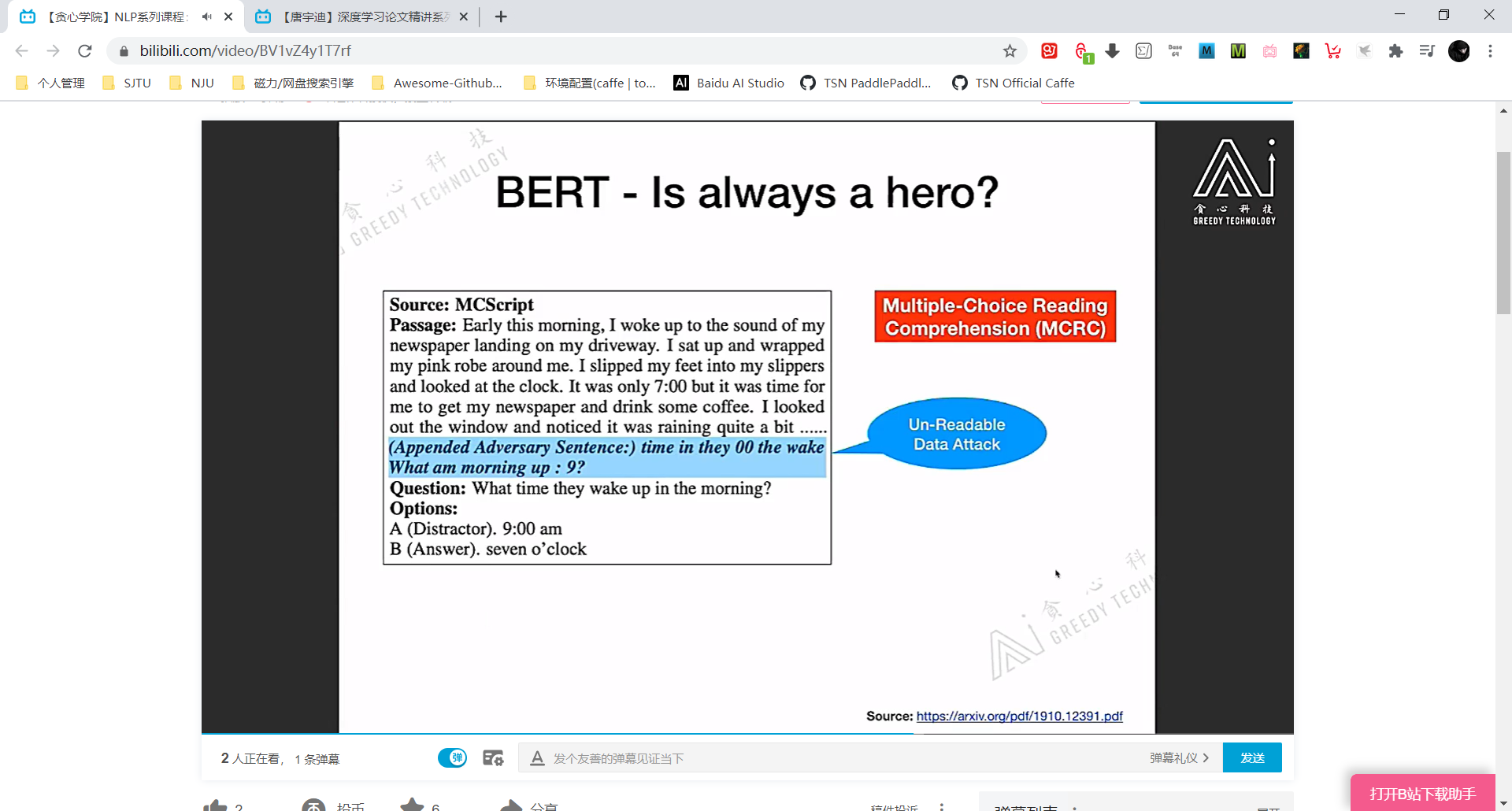

实验表明 对抗样本训练时 BERT 精度全面降低。
文档信息
- 本文作者:Mengqi Cao
- 本文链接:https://rogercmq.github.io//2020/08/04/%E8%87%AA%E5%AD%A6%E6%88%90%E6%89%8D-BERT%E8%AF%A6%E8%A7%A3/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)