本节内容来自: NVIDIA CUDA初级教程视频 P8
主要内容:内置类型和函数,线程同步,线程调度,存储模型,重访,原子函数
函数声明(函数类型)
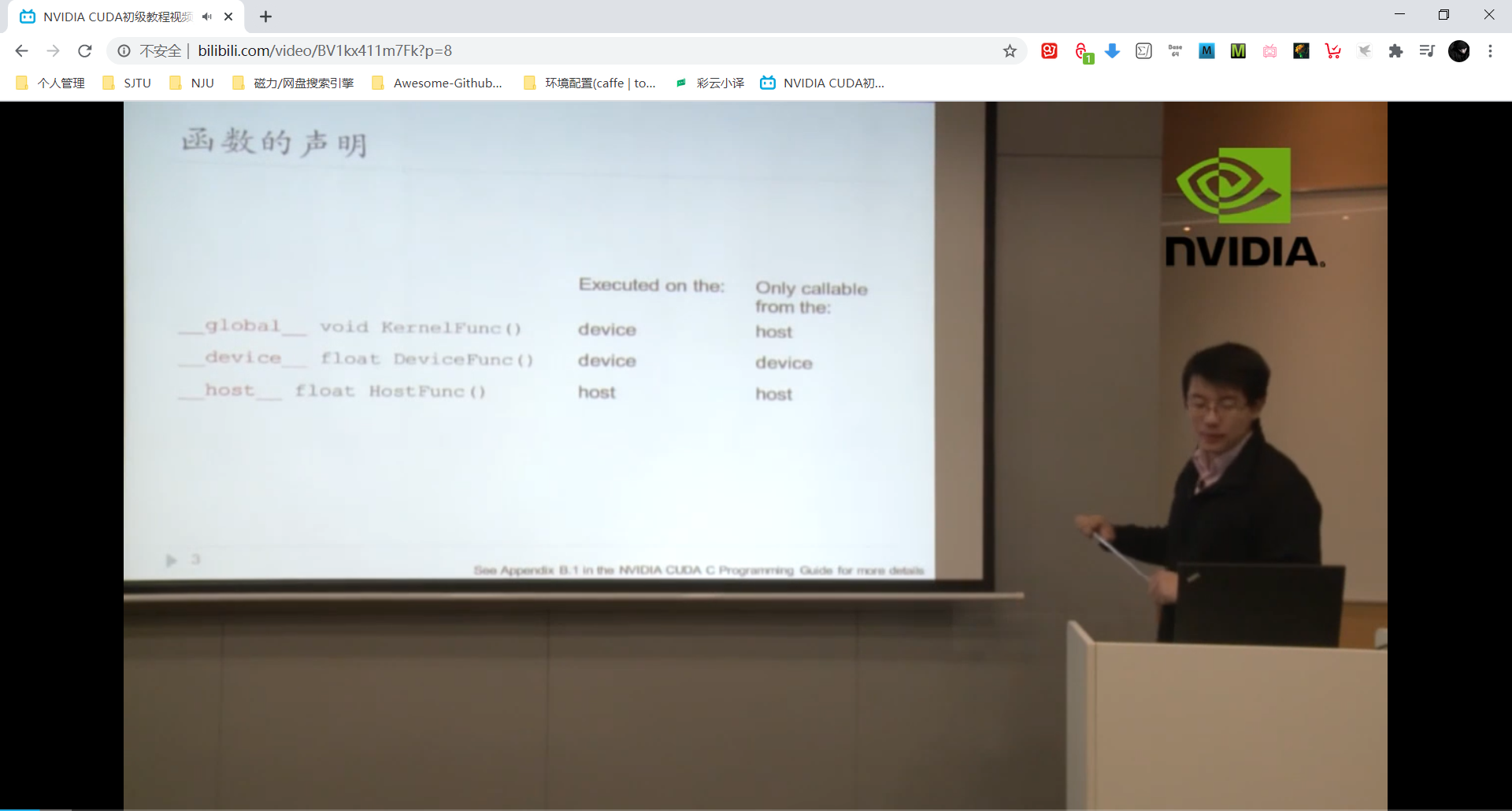
如上图,global 函数只能在主机端调用,但是要在设备端执行。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device) 。函数的声明不一定唯一,这样的话函数在主机端和设备端可同时调用。
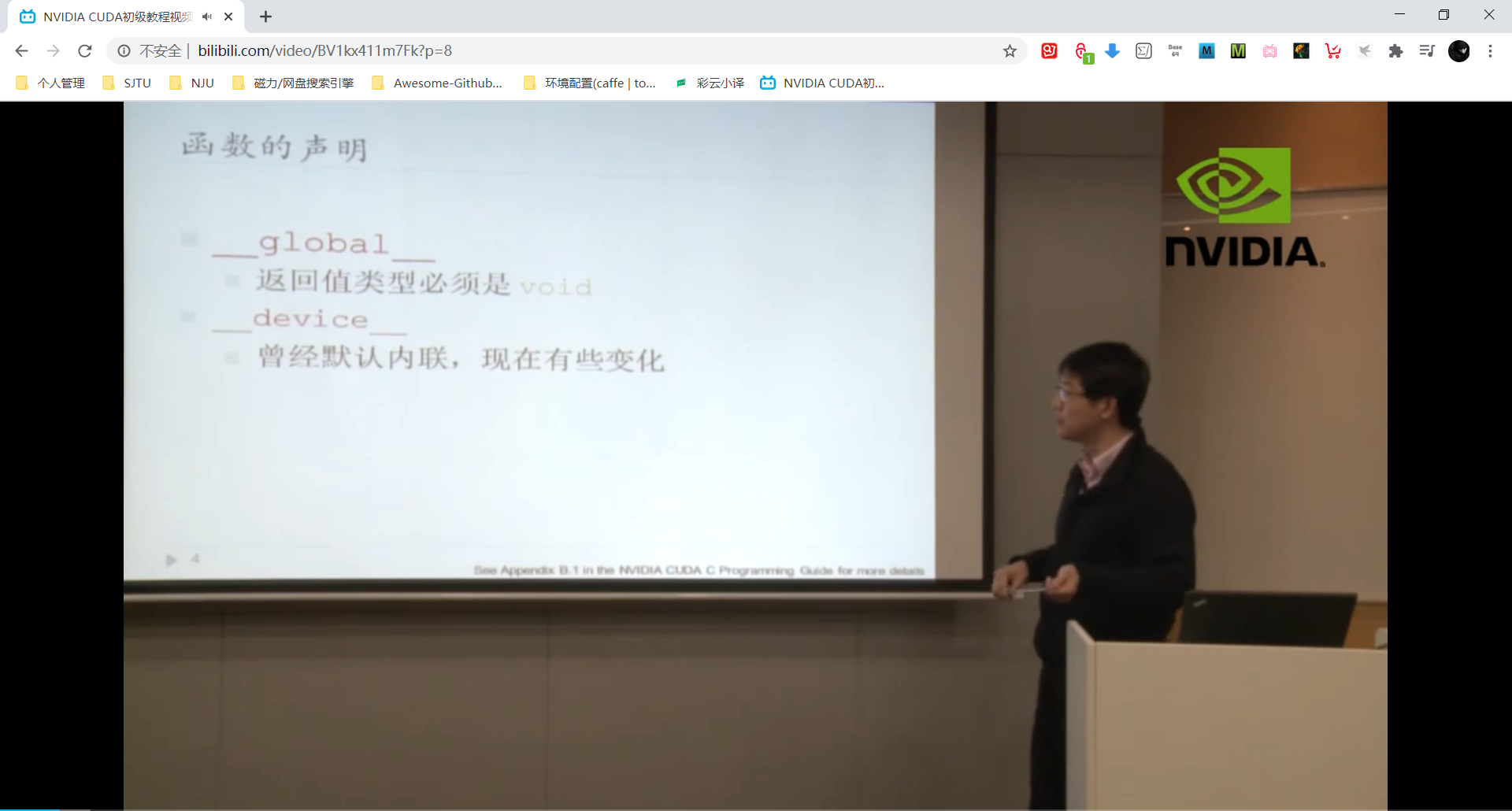
如上图,内联函数是什么我忘记了:???
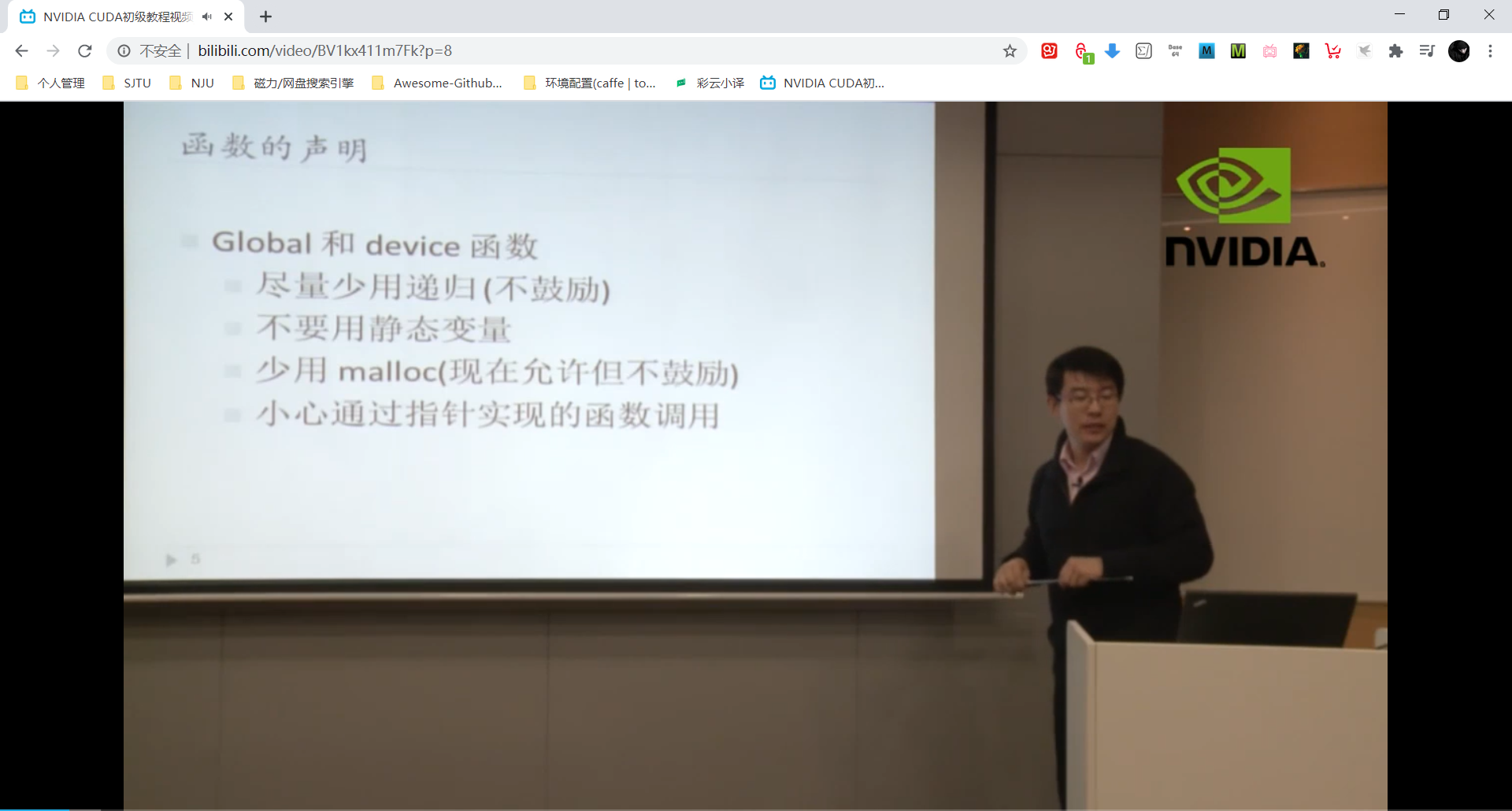
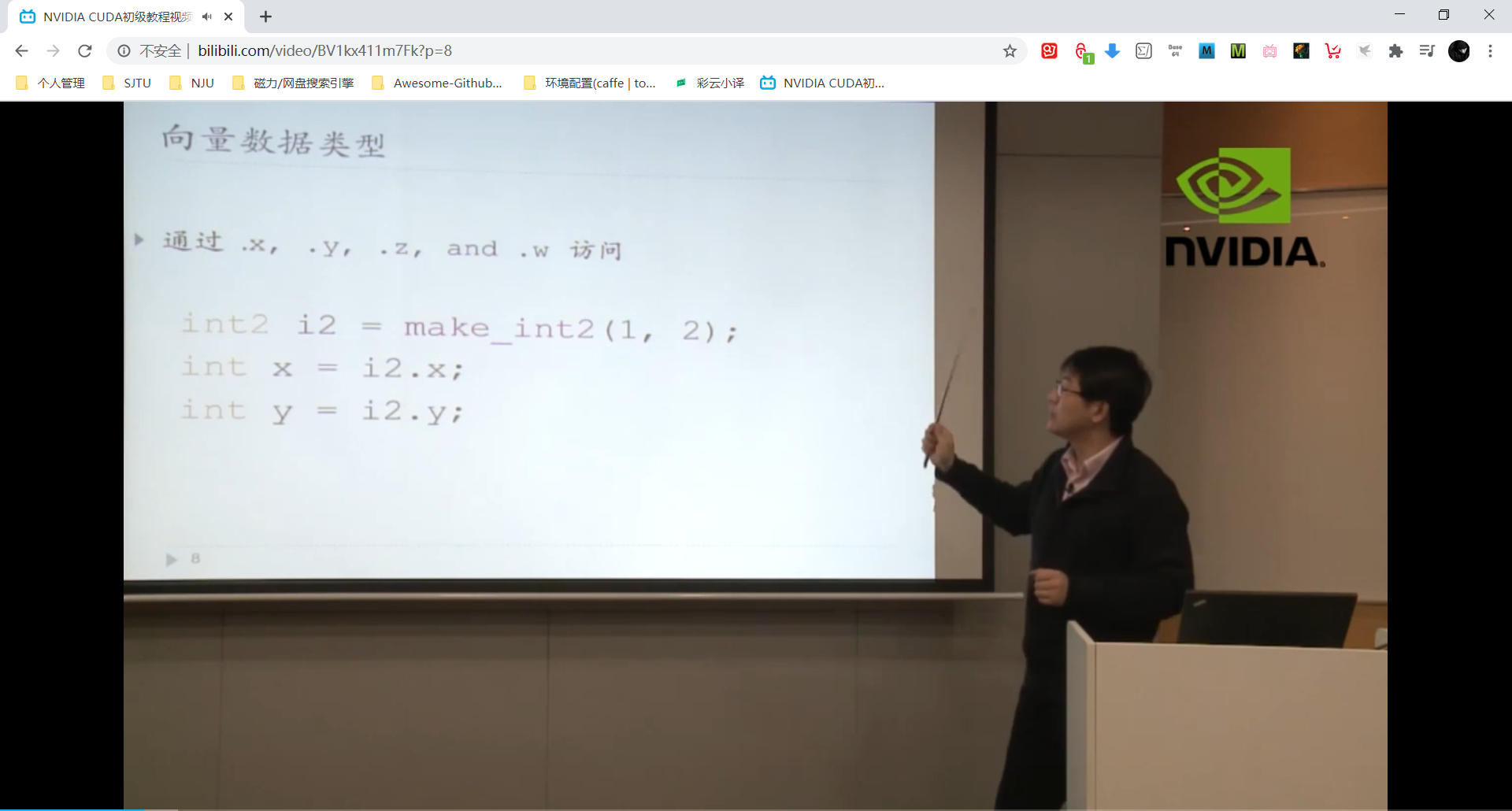
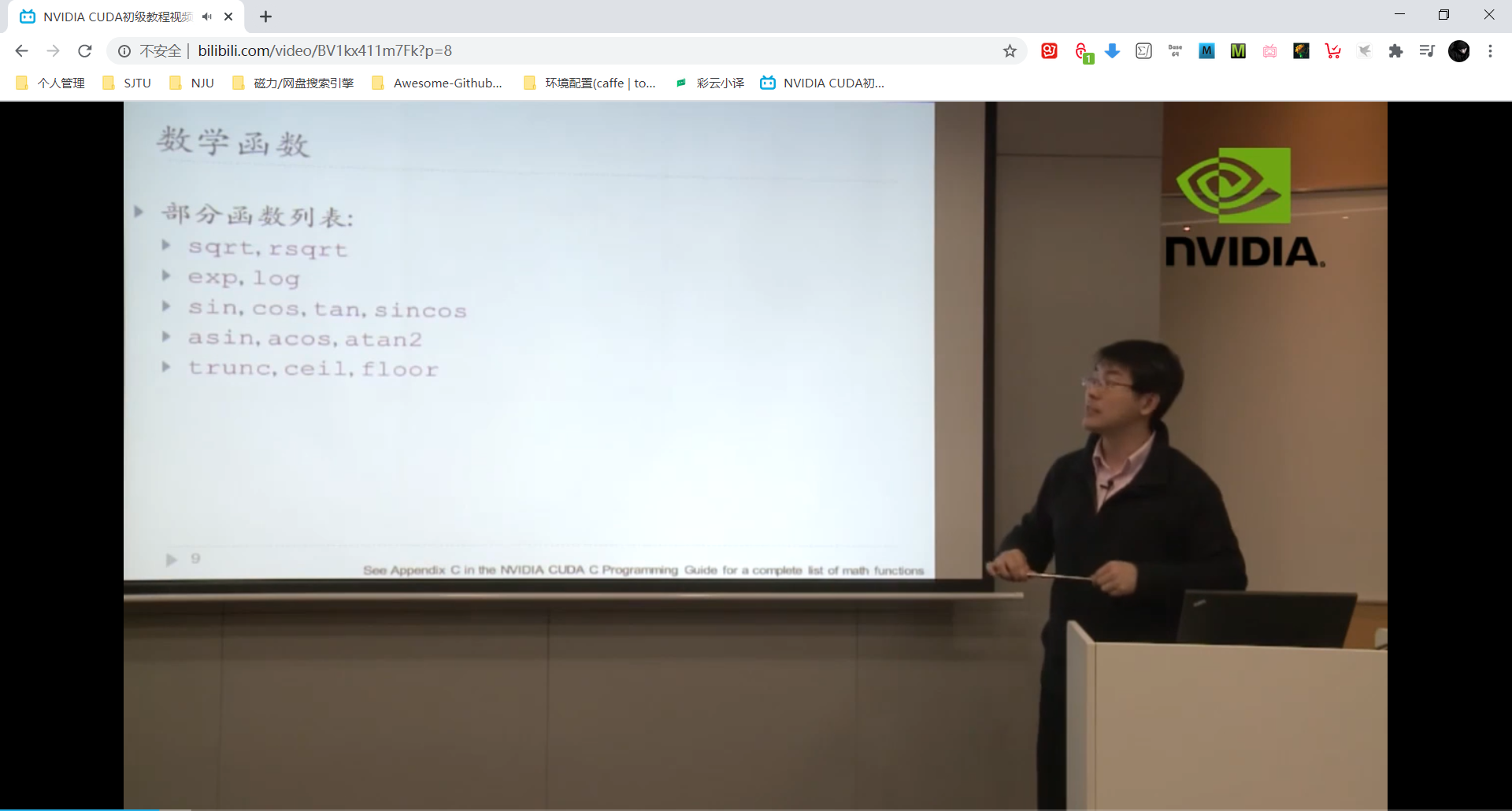
内建函数 Intrinsic Function
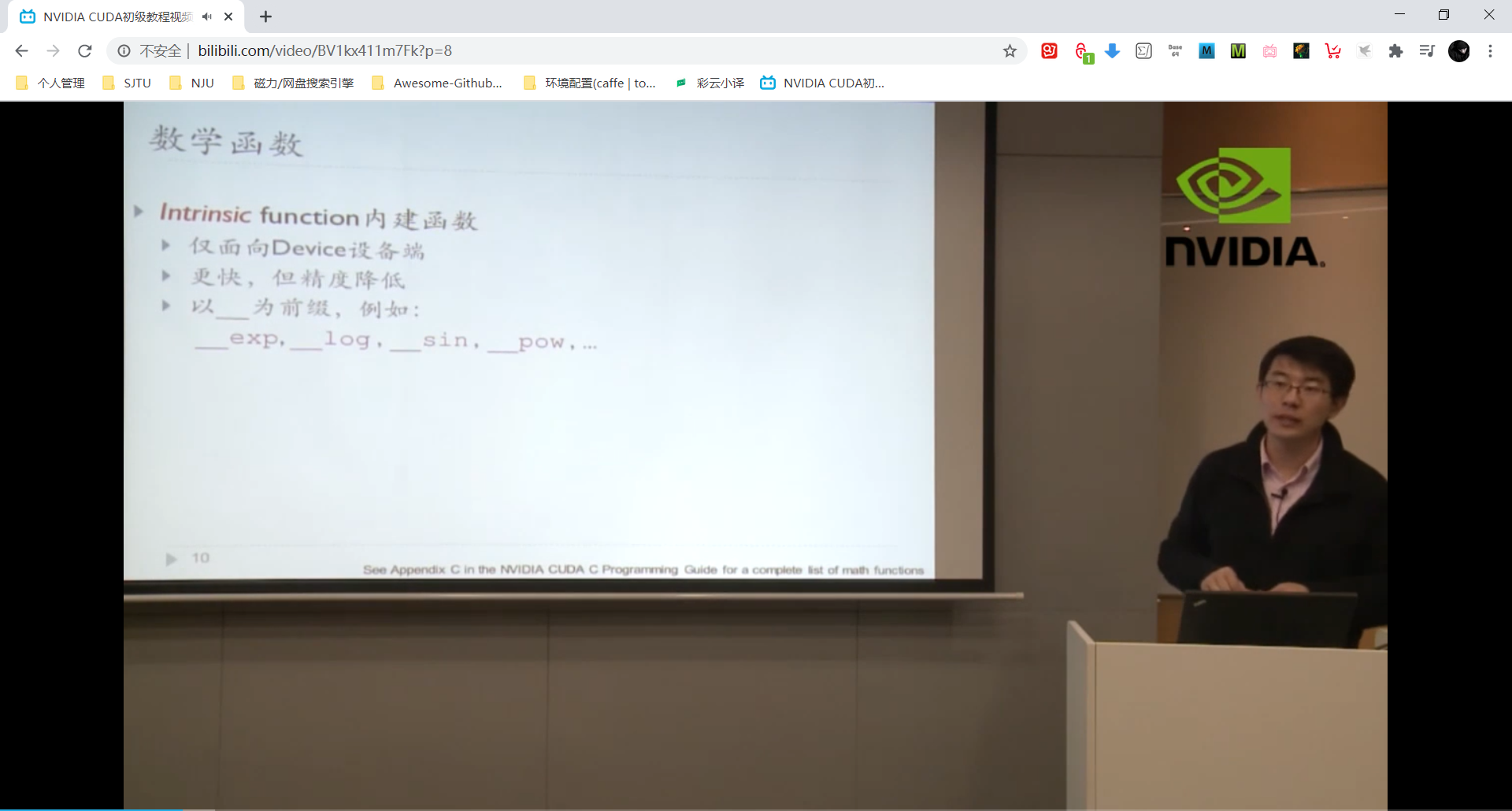
内建函数可用在视频系统中,对精度要求不高但是对速度要求高。
线程同步
主机端一个kernel启动的时候,在设备端会启动一个grid,线程grid里包含若干线程block,线程block里有多个线程。如下图:

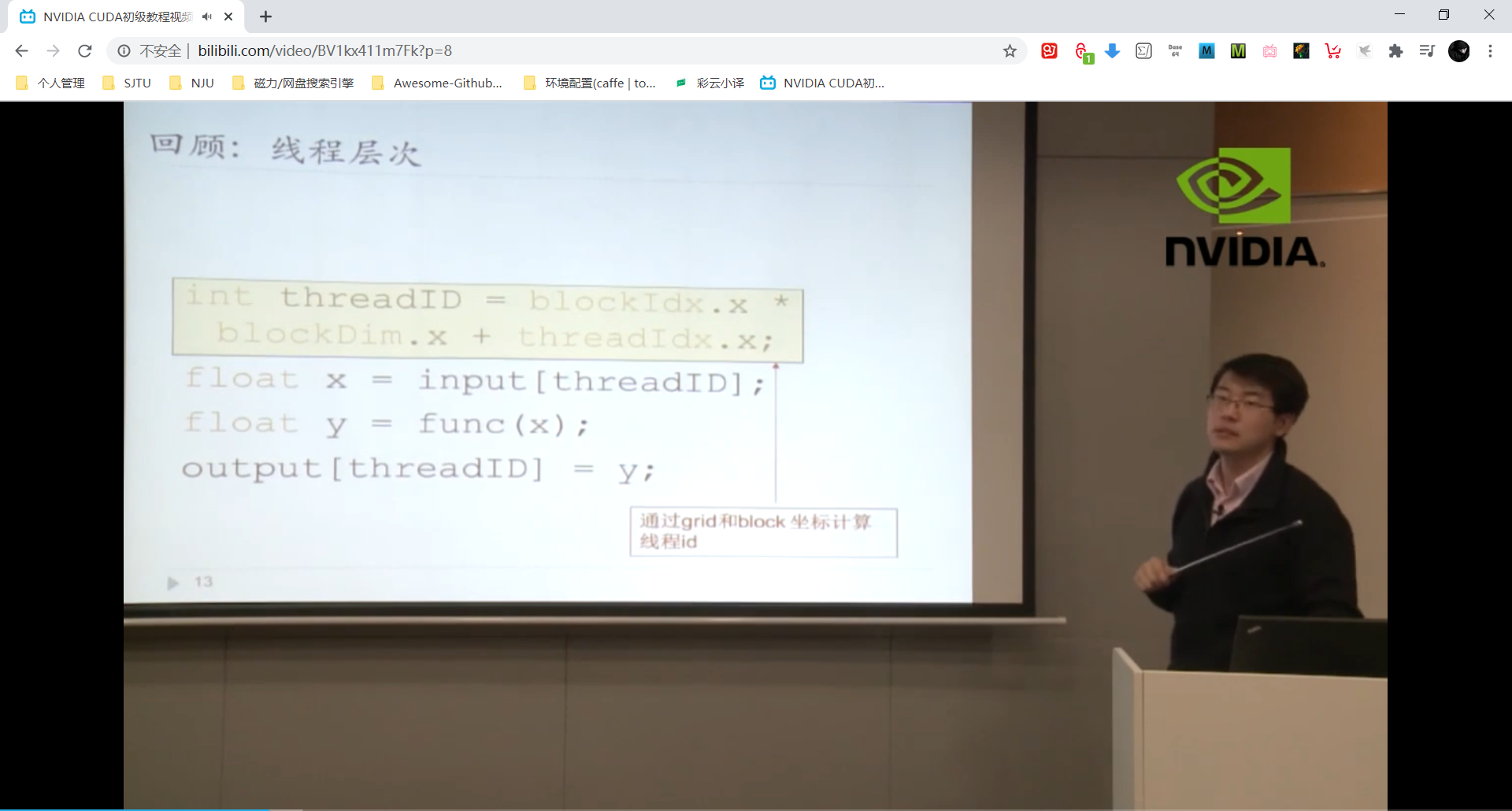
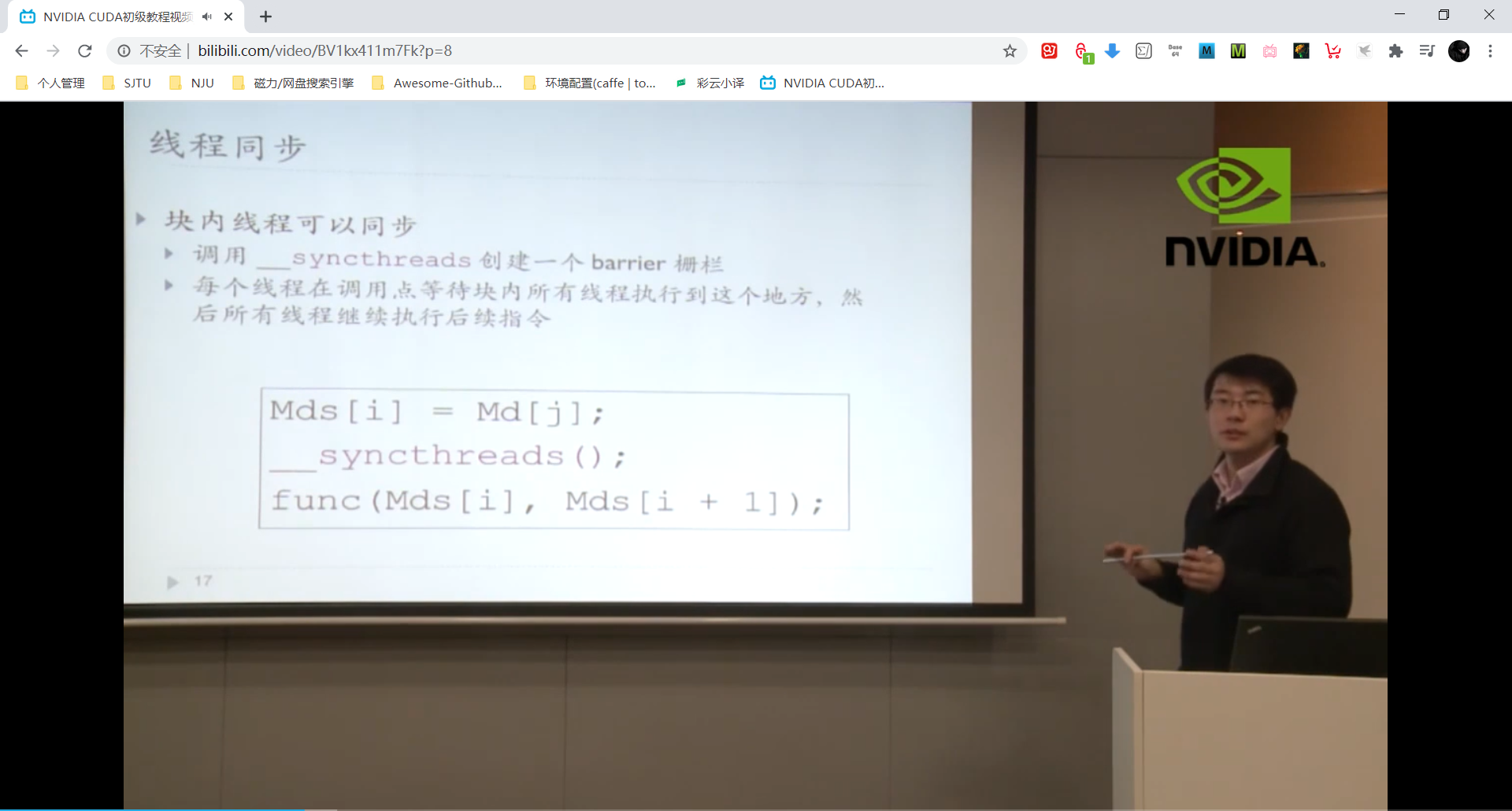
块内的线程才可以同步!!! 但是线程同步会破坏并行性导致线程的暂停,甚至可能导致死锁。
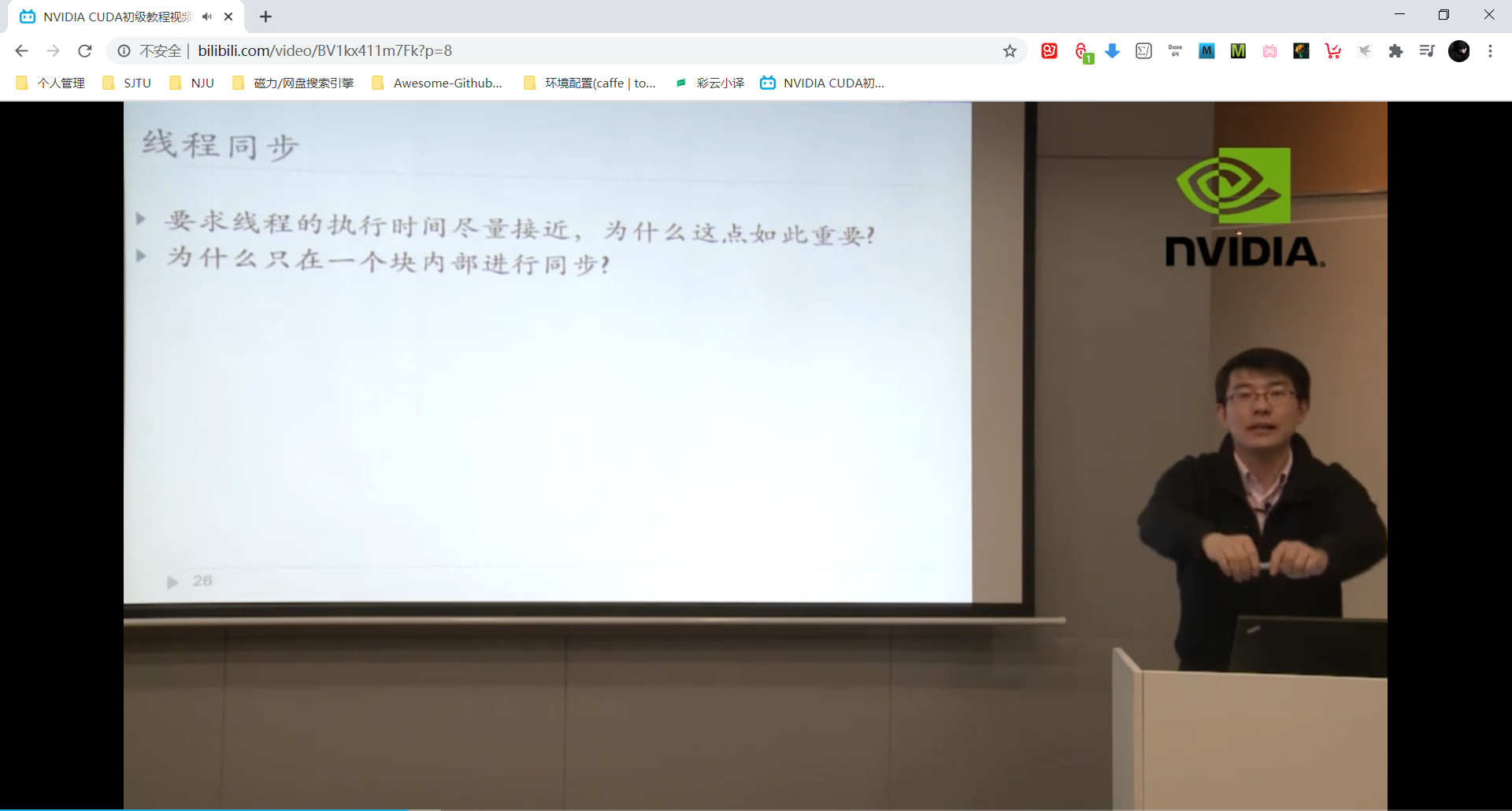
- 问题一:线程的执行时间接近 == 负载均衡。
- 问题二:全局的线程同步理论上可实现但是没有实际应用价值得不偿失。
线程调度
GPU架构中的SM和SP
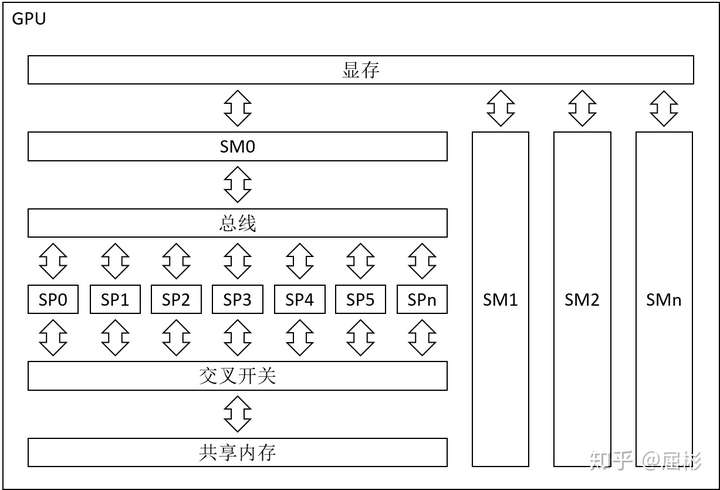
SM (streaming Multi-processor) 是GPU的基本控令执行单元,它拥有独立的指令调度电路。一个SM下所有的SP共享同一组控制指令。因此每个独立的计算任务至少要用一个SM执行,如果计算任务的规模无法让SM及其下所有的SP“吃饱”,就会浪费该SM下部分SP的算力。此外,每个SM还拥有一套独立的共享内存。
SP (streaming processing, 又称ALU) 是GPU的基本算术指令执行单元,它没有指令调度电路,但拥有独立的算术电路,包括1个ALU(Arithmetic logic unit)和1个FPU(Float Point Unit)。每个SP负责处理固定数量的线程,注意这里的“线程”与CPU上的线程不同,它们共享同一组算术指令,处理不同的数据,这种并行方式又叫作SIMD(Single Instruction Multiple Data)。SP内部没有任何除寄存器和缓冲队列外的独立存储系统。

768 * 16 = 12288,在同一时钟周期下12288 个线程可以同时被128个并行指令流执行(线程不同切换,实现延迟掩藏)。
Warp: 线程块内的一组线程, 线程调度的基本单位

答疑: CUDA中grid、block、thread、warp与SM、SP的关系
首先概括一下这几个概念。其中SM(Streaming Multiprocessor)和SP(streaming Processor)是硬件层次的,其中一个SM可以包含多个SP,SP又称CUDA core,一个CUDA core可以执行一个thread。thread是一个线程,多个thread组成一个线程块block,多个block又组成一个线程网格grid。(√)
现在就说一下一个kenerl函数是怎么执行的。一个kernel程式会有一个grid,grid底下又有数个block,每个block是一个thread群组。在同一个block中thread可以通过共享内存(shared memory)来通信,同步。而不同block之间的thread是无法通信的。(√)
CUDA的设备在实际执行过程中,会以block为单位。把一个个block分配给SM进行运算;而block中的thread又会以warp(线程束)为单位,对thread进行分组计算。目前CUDA的warp大小都是32,也就是说32个thread会被组成一个warp来一起执行。同一个warp中的thread执行的指令是相同的,只是处理的数据不同。(√)
warp 分组是连续的:基本上 warp 分组的动作是由 SM 自动进行的,会以连续的方式来做分组。比如说如果有一个block 里有128 个thread 的话,就会被分成四组warp,第 0-31 个thread 会是warp 1、32-63 是warp 2、64-95是warp 3、96-127 是warp 4。而如果block 里面的thread 数量不是32 的倍数,那他会把剩下的thread独立成一个warp;比如说thread 数目是66 的话,就会有三个warp:0-31、32-63、64-65 。由于最后一个warp 里只剩下两个thread,所以其实在计算时,就相当于浪费了30 个thread 的计算能力;这点是在设定block 中thread 数量一定要注意的事!(√)
一个 SM 一次只会执行一个 block 里的一个 warp,但是 SM 不见得会一次就把这个warp 的所有指令都执行完;当遇到正在执行的warp 需要等待的时候(例如存取global memory 就会要等好一段时间),就切换到别的warp来继续做运算,借此避免为了等待而浪费时间。所以理论上效率最好的状况,就是在SM 中有够多的warp 可以切换,让在执行的时候,不会有「所有warp 都要等待」的情形发生;因为当所有的warp 都要等待时,就会变成SM 无事可做的状况了。(√)
实际上,warp 也是CUDA 中,每一个SM 执行的最小单位;如果 GPU 有 16 组 SM 的话,也就代表他真正在执行的thread 数目会是32*16 个。不过由于 CUDA 是要透过 warp 的切换来隐藏 thread 的延迟、等待,来达到大量平行化的目的,所以会用所谓的 active thread 这个名词来代表一个 SM 里同时可以处理的 thread 数目。
而在block 的方面,一个 SM 可以同时处理多个 thread block,当其中有 block 的所有 thread 都处理完后,他就会再去找其他还没处理的block 来处理。假设有 16 个SM、64 个block、每个 SM 可以同时处理三个block 的话,那一开始执行时,device 就会同时处理48 个block;而剩下的16 个block 则会等SM 有处理完block 后,再进到SM 中处理,直到所有block 都处理结束
需要我注意的是,“ 一个线程块的thread只能在一个SM上调度 ” 和 “一个 SM 可以同时处理多个 thread block” 是不冲突的,多个线程块的线程在同一个SM上调度从而实现延迟掩藏。如下图:

下图翻译:
- warp的调度是零开销的,因为所有warp的上下文是实际存在于SM的物理空间的,当它需要调度时直接寻址就可以了。相当于吃饭,饭碗和筷子都是放在桌子上的,warp来了就能直接用。
- 任何时刻,SM 都只能执行一个 warp 的线程。也就是说吃饭的时候,这张桌子(SM)只有某一个小组的人在吃饭。

问题:如果warp内部线程沿不同分支执行,会有什么后果?
答:由于wrap要求内部线程自然同步,所以不得不浪费一些算力,这种现象称为 divergent wrap。
简单的计算题

Solution: 分批次处理(32个人吃饭但是饭桌(SM)只有8个碗(SP),4个周期调度完成)。但是现代架构中SP数远大于warp数了,不需要考虑分批次的问题了。

假定一次独立的M/A需要4个周期

内存模型
Register

每个线程的速度会增加,但是SM可承载的线程数受到了限制(办公桌面积增大,但是办公室能容纳的人数减少了)
Local Memory

Shared Memory

Global Memory

Constant Memory



文档信息
- 本文作者:Mengqi Cao
- 本文链接:https://rogercmq.github.io//2020/08/04/CUDA-Day-6-CUDA%E7%BC%96%E7%A8%8B%E4%BA%8C/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)