Gate-Shift Networks for Video Action Recognition (CVPR2020), 本篇笔记在 Related Works 部分做了疯狂总结.
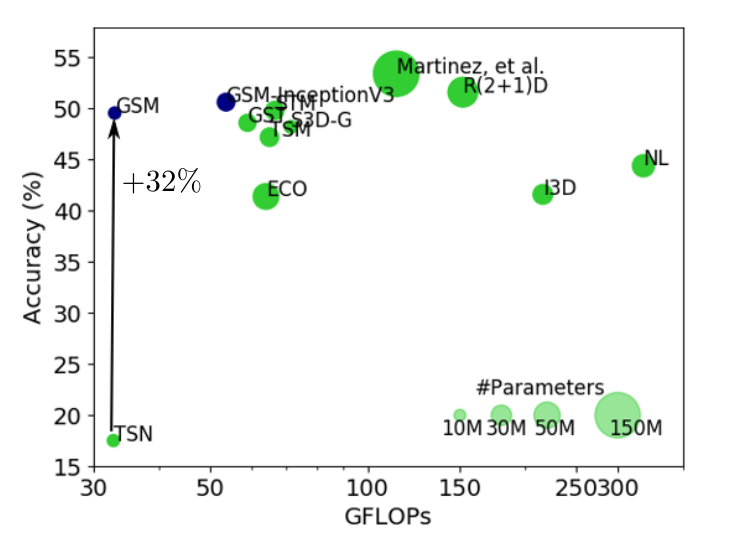
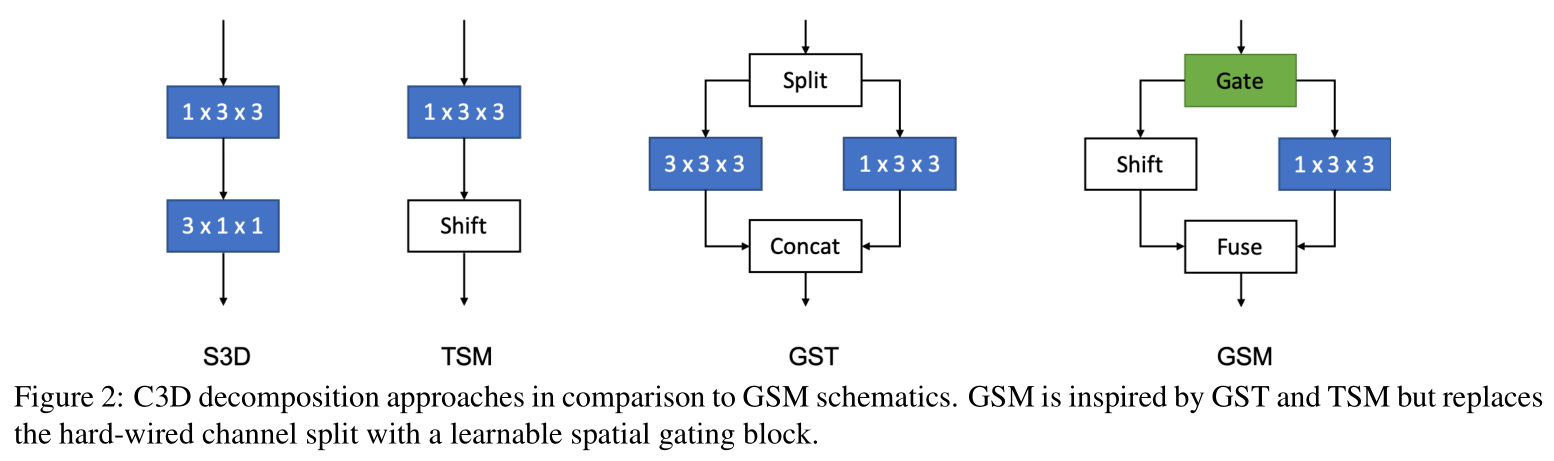
作者提出了一个轻量级模块 Gate-Shift Module (GSM),将 2D 卷积替换为高效的 spatio-temporal feature extractor。并且相较于 hardwired 的 channel-wise 拆分方案(具体工作见本笔记第二章关于 ST Modeling 的介绍), 本工作提出的 data-dependent gate 机制更 dynamic。 本人认为该工作过于 empirical,是 Han Song 课题组 TSM 的改良版,用一个3x3x3卷积去选择 temporal shift 的 pattern。

1. Introduction
视频领域依然无法像图像领域一样有突破性进展,主要原因依然在于如何获取数据的时空信息。文中提到了一个词语叫做时序推理 (temporal reasoning),之后可以调研一下 NLP 领域是否有类似的动机。
A key challenge lies in the space-time nature of the video medium that requires temporal reasoning for fine-grained recognition.
UCF101 和 Kinetics 数据集并不太需要 temporal reasoning,因为大多数类别通过静态场景和物体就可以识别,甚至打乱帧顺序得到的识别结果也差不多。
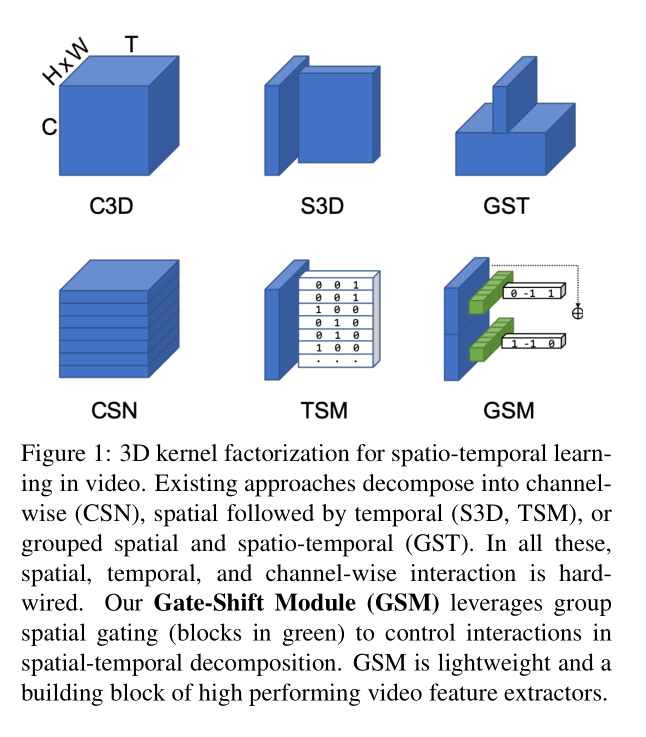
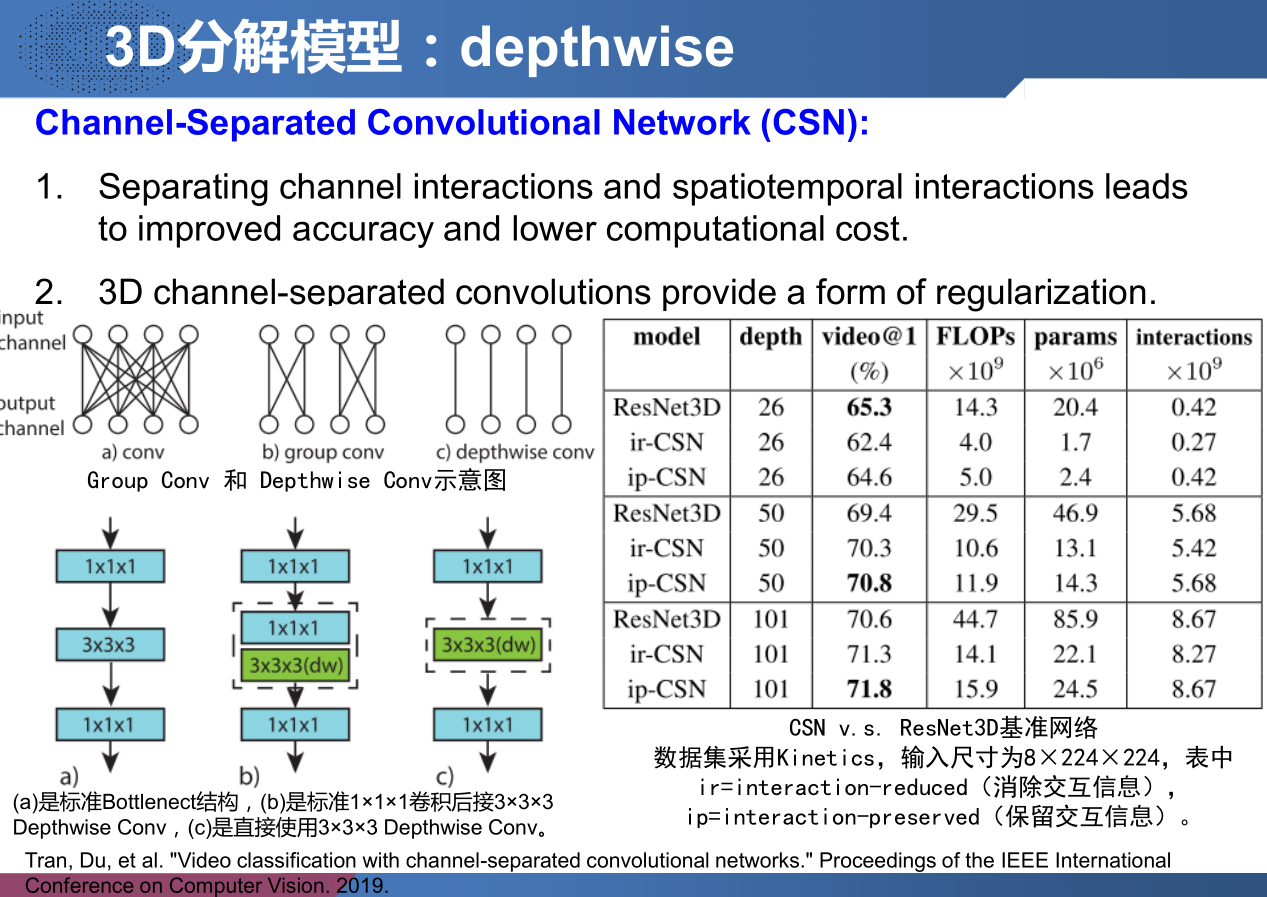
Figure 1 描述了几种3D卷积神经网络解耦方案。方案 1-5 的架构设计都是在模型训练以前硬性规定的,原文称 “ There is no data dependent decision taken at any point in the network to route features selectively through different branches.”
A most intuitive approach is to factorize 3D spatio-temporal kernels into 2D spatial plus 1D temporal, resulting in a structural decomposition that disentangles spatial from temporal interactions (P3D[31], R(2+1)D[40], S3D [46]).
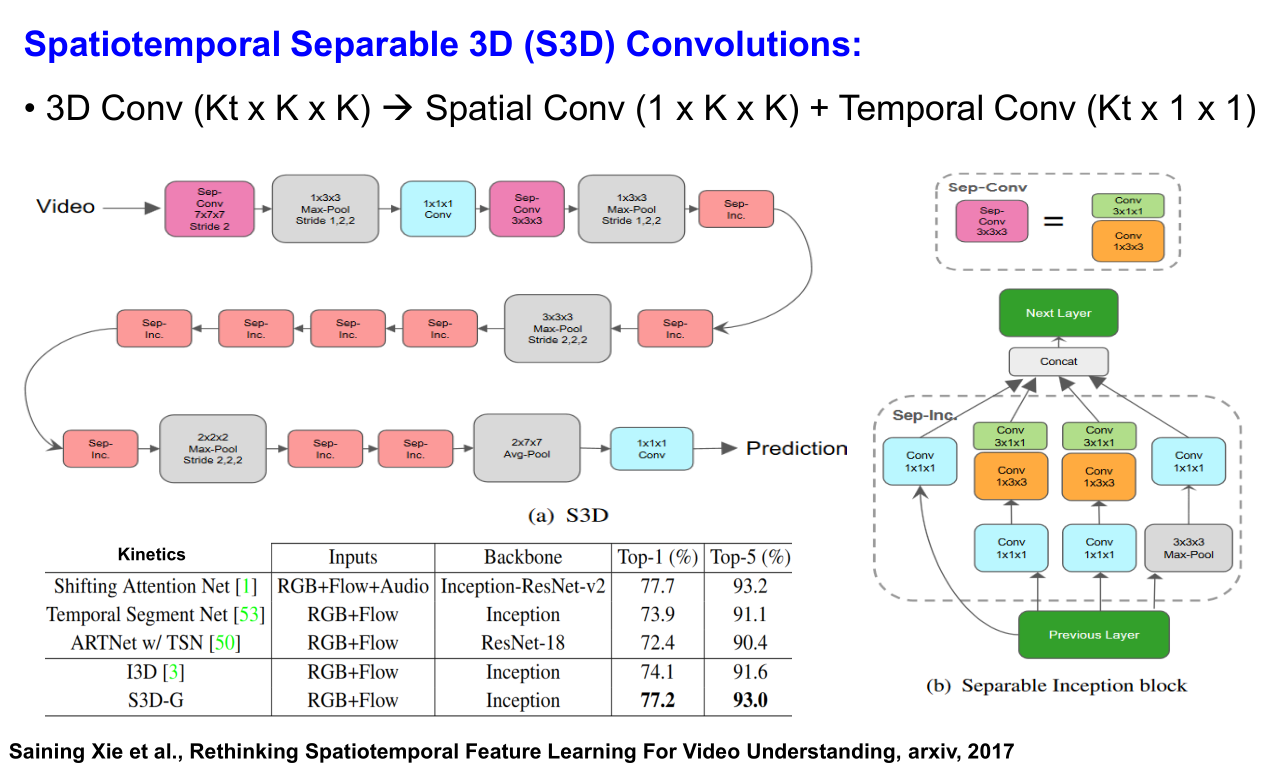
[46] Rethinking spatio-temporal feature learning: Speed-accuracy trade-offs in video classification. (ECCV2018) 本工作在 我的讲座笔记 2d+1d 代替所有 3d 卷积; 2) 参考 SENet 的思想提出了 3d 的 feature gating mechanism。
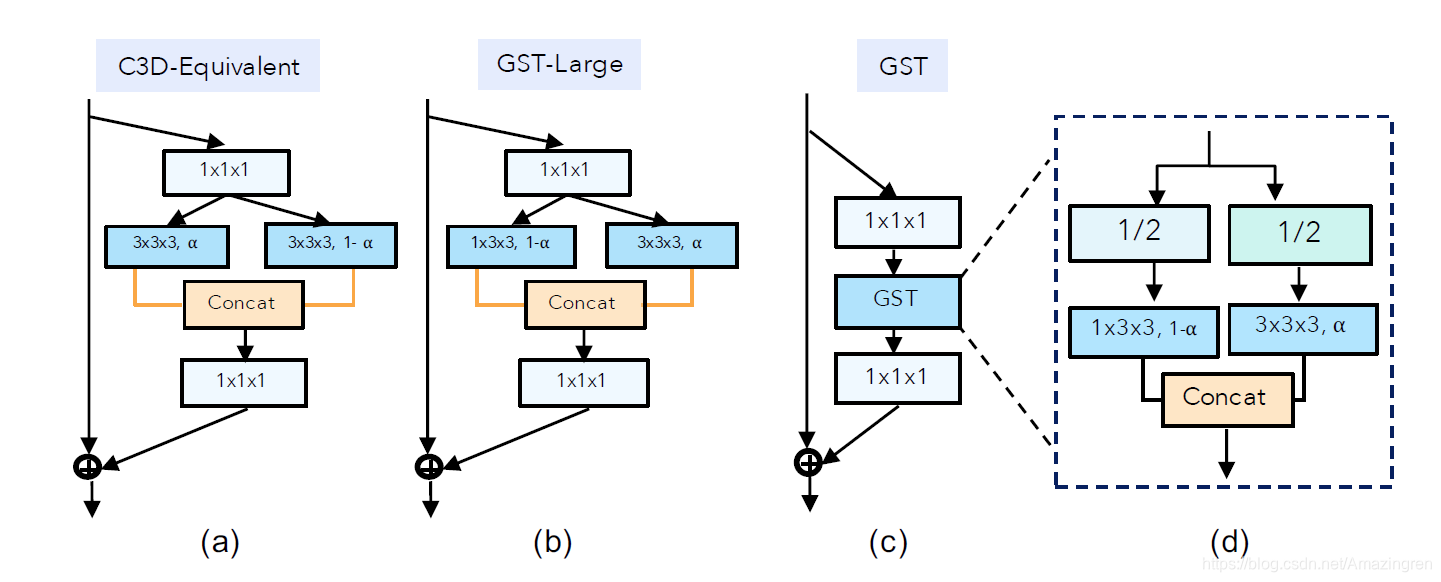
An alternative design is separating channel interactions and spatio-temporal interactions via group convolution (CSN [39]), or modeling both spatial and spatio-temporal interactions in parallel with 2D and 3D convolution on separated channel groups (GST [27]).
[39] Video Classification With Channel-Separated Convolutional Networks. (ICCV2019) 本工作在 我的讲座笔记 分解3D卷积通过分开通道间相互作用和时空域信息的交互将对于提高准确率和节省计算量有很好的帮助; 2) 将3D卷积进行 depthwise 这种方法从某种程度上说可以等效成一种正则化,虽然在训练集上的准确率不高,但在测试集上表现出高准确率。
[27] Grouped Spatial-Temporal Aggregation for Efficient Action Recognition. (ICCV2019) 本工作硬核地将特征 channel-wise 拆分为用3D卷积建模的 Temporal feature 和用2D卷积建模的 Spatial feature,然后 concatenate 所有特征。似乎与上一篇CSN深度可分离卷积解耦方案思路一致。
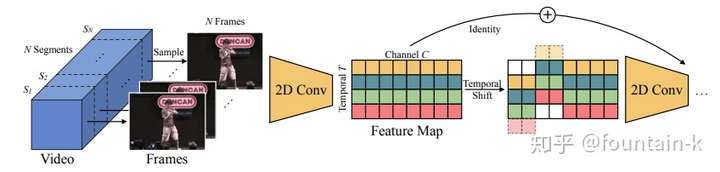
Temporal convolution can be constrained to hard-coded time-shifts that move some of the channels forward in time or backward (TSM [25]).
[25] Temporal Shift Module for Efficient Video Understanding. (ICCV2019) 本工作在 [我的讲座笔记](https://rogercmq.github.io//2020/06/19/%E8%AE%B2%E5%BA%A7%E7%AC%94%E8%AE%B0-VALSE-Action-Recognition(3)/ 中有所记录。
本段内容来自 知乎笔记 : 在图2a中,我们描述了一个包含C通道和T帧的张量。不同时间戳的特征在每行中表示为不同的颜色。传统的二维CNN在不同的信道间进行操作,即在不进行时间融合的情况下,沿每一行单独进行操作。在时间维度上,我们将1 / 4通道移动了- 1个单位,将另一个单位移动了+1个单位,剩下的一半没有移动(图2b)。“四分之一”是我们将在消融研究中讨论的超参数(3.3节)。哪一1/4shift并不重要,因为下一层的权重会在训练中适应。因此,我们将帧t - 1、t和t + 1的时间信息混合在一起,类似于核大小为3的一维卷积,但计算成本为零。乘法累加被推到下一层。利用二维卷积的信道间融合能力,实现了原始的时域间融合。
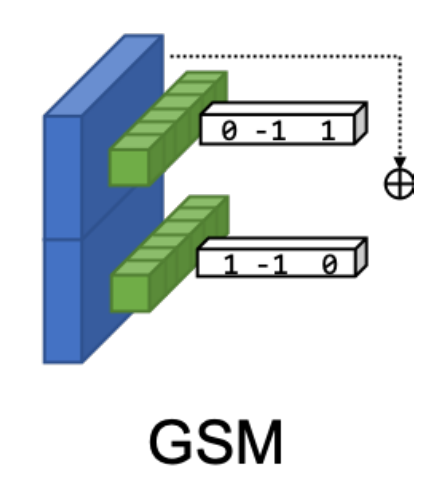
本工作提出的 Gate-Shift Module (GSM):
2. Related Work
Fusing appearance and flow
介绍了双流网络(单帧RGB图片 + 光流图)。
Video as a set or sequence of frames
将视频理解为多图分类问题,提取每一帧的特征,并在2D CNNs后面添加fusion模块,将不同帧得到的特征融合在一起,最后输出预测action的概率。
Modeling short-term temporal dependencies
研究帧与帧之间的短期时序依赖性。
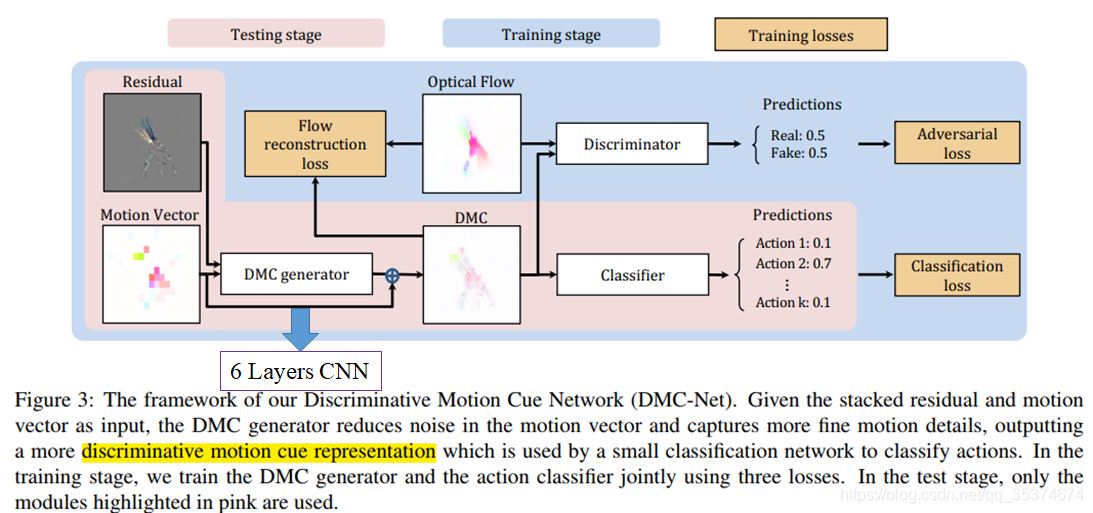
Other research has investigated the middle ground between late aggregation (of frame features) and early temporal processing (to get optical flow), by modeling short-term dependencies. This includes differencing of intermediate features [29] and combining Sobel filtering with feature differencing [36]. Other works [6, 30] develop a differentiable network that performsTV-L1[47], a popular optical flow extraction technique. The work of [21] instead uses a set of fixed filters for extracting motion features, thereby greatly reducing the number of parameters. DMC-Nets [32] leverage motion vectors in the compressed video to synthesize discriminative motion cues for two-stream action recognition at low computational cost compared to raw flow extraction.
[21] Motion feature network: Fixed motion filter for action recognition. (ECCV2018)
本段内容来自 CSDN博客 : 之前为了抓取motion信息,使用的是光流作为CNN的输入。而本文作者的目标是基于光流算法来表示去寻找能够帮助分类动作识别任务的temporal特征,而不是去寻找光流的最优解。
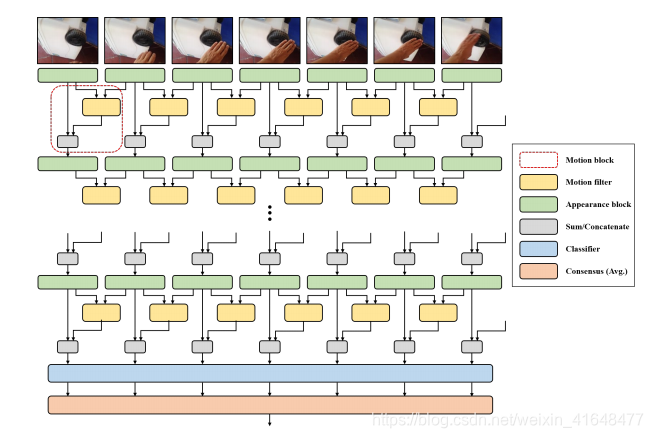
本段内容来自 知乎 : 本工作基于 Limin Wang 的 TSN (Temporal Segment Networks) 提出了 motion blocks 编码 spatial-temporal 信息.上图中也可以看到,帧先过base_cnn,文章称为appearance block.之后联立两帧的feature计算运动特征,再sum/concatenate 两个特征.此为一个完整的motion block.迭代多个motion block构成文章的模型.
[32] DMC-Net: Generating discriminative motion cues for fast compressed video action recognition. (CVPR2019)
与 Motion Vector 相比, DMC 生成的特征噪声更少更有效。

Video as a space-time volume
介绍 3D/2D+1D CNNs,在网络架构上进行修改,既提高了精度又减少了模型计算复杂度。
[22] Collaborative Spatiotem-poral Feature Learning for Video Action Recognition (CVPR2019)
以下内容来自: 知乎笔记
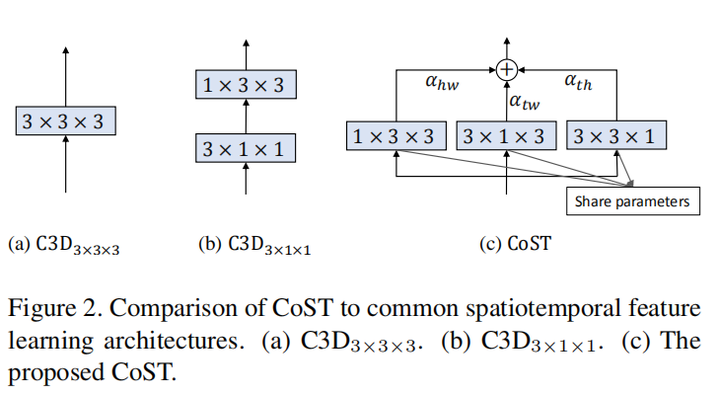
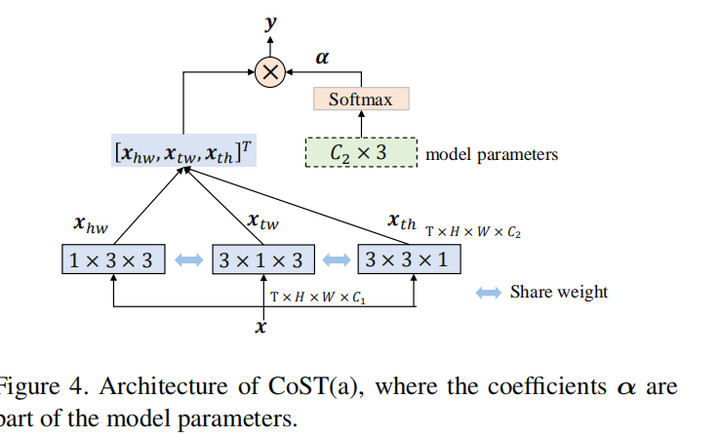
为了更好建模时序关系,给出视频序列的3D向量 TxHxW,作者首先从不同的视角把它分解成3个2D图像集合,然后用卷积操作分别对三个图像集合进行卷积。从三个视角得到的视频序列分别是
- H-W视角,就是把H-W看作一个平面,T作为单独的一个维度把平面扩充。
- T-W视角,就是把T-W看做一个平面,H作为单独的一个维度把平面扩充。
- T-H视角,就是把T-H看做一个平面,W作为一个单独的维度把平面扩充。
这样的设计可以让每一帧都包含丰富的动作信息,而不是在两帧之间有动作信息,使用2D卷积可以直接捕捉时序动作线索,另外可以使用2D卷积学习时空特征而不用3D特征。 得到三个视角的特征后,对其进行加权求和得到该层的最终输出:

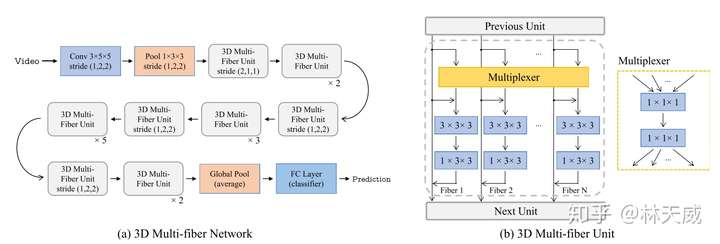
[3] Multi-fiber networks for video recognition (ECCV2018)
以下内容来自: 知乎笔记
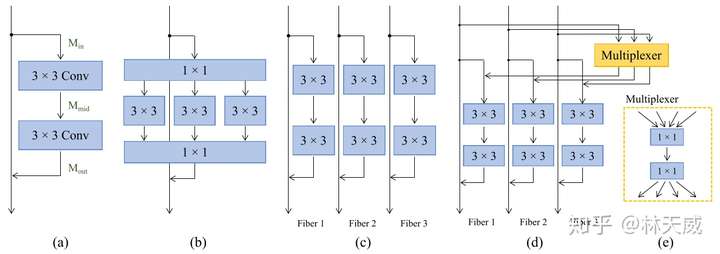
这张图介绍了从resnet到多纤维模块的变化过程。(a) 中的结构即是一个简单的残差模块;(b) 中的则为Multi-Path类型的bottleneck模块,比如ResNeXt就采用了该结构。在该结构中,前后均为一个1x1的卷积进行降维和升维,中间则将通道进行分组,分别用几个3x3卷积核进行处理。这样的处理可以大大降低中间层的计算量,但是1x1卷积层依旧有很大的计算量。所以这篇文章提出进行更加彻底的分组,即将整个残差模块按照通道切片成多个平行且独立的分支(称为fiber,纤维),如(c)所示。c中的结构在输入和输出通道数量一致的情况下,可以将理论计算量降低到N分之一,此处N为分支或者说是纤维的数量。这种更加彻底分组的加速思路和去年的ShuffleNet其实也有些像,区别在于ShuffleNet中还提出了channel shuffle的模块,且在中间层采用了depth-wise conv。 如(c)所示的结构虽然效率提高了很多,但通道间缺乏信息交换,可能会损害效果。所以该文进一步提出了一个Multiplexer模块用来以残差连接的形式结合纤维之间的信息。该模块实际上是一个两层的1x1卷积。
从2D拓展到3D:
Spatial-temporal modeling
以下文章 [35] , [52] 和 [18] (包括Han Song组的 TSM [25], 以及本笔记第一章提到的 GST [27] ) 都是对视频的空间时序进行 channel-wise 建模,在采样上使用了一些技巧,抽取了部分帧作为模型输入。
文章 [18] 是2D与1D卷积的并行设计,将2D特征 channel-wise 拆分,CMM和CSTM都是即插即用的模块。
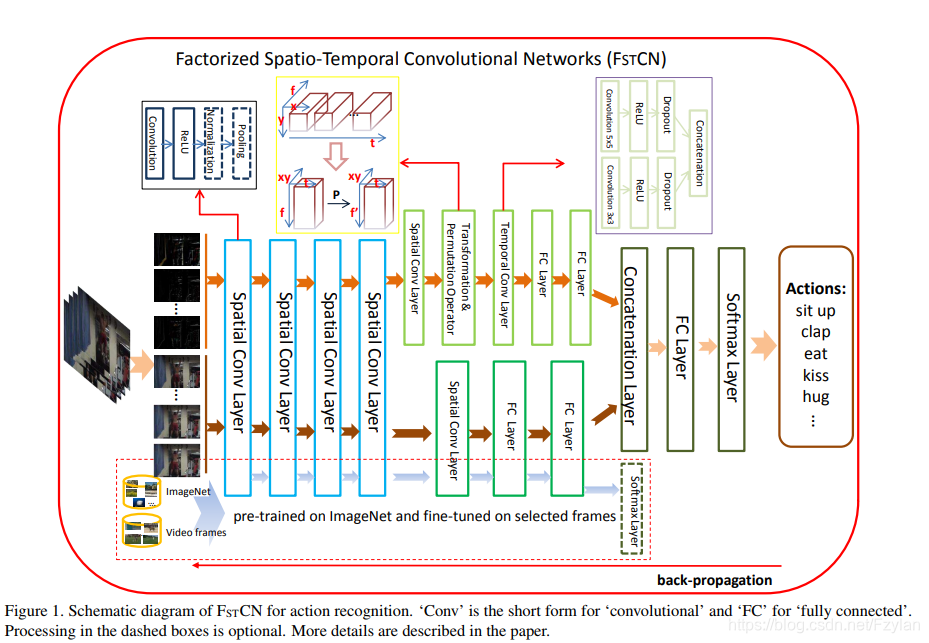
[35] Human action recognition using factorized spatio-temporal convolutional networks (ICCV2015)
这里 有别人的论文笔记。网络底层对应靠近输入侧,顶层对应模型输出侧。
[52] ECO: Efficient Convolutional Network for Online Video Understanding (ECCV2018)
以下内容来自: 知乎笔记
使用单帧的图像,在很多情况下已经可以获得一个不错的初始分类结果了,而相邻帧间的很多信息都是冗余的。因此,ECO中在一个时序邻域内仅使用单帧图像。为了获得长时程的图像帧间的上下文关系,仅仅使用简单的分数融合(aggregation) 是不足够的。因此,ECO中对较远帧之间采取对 feature map 进行3D 卷积的方式进行end-2-end的融合。在ECO中,作者先将一个视频等分为N份,再在每份中随机选取一帧作为输入(均匀采样)。作者认为这样的随机采样策略可以在训练中引入更多的多样性,并提高泛化能力。
[18] STM: Spatio-Temporal and Motion Encoding for Action Recognition (ICCV2019)
以下内容来自: 知乎
第一个1x1的2D卷积是用来减少通道维度,压缩之后的feature map输入到CSTM和CMM中来提取响应的特征,这里组合不同类型信息的方法有两种:求和和串接,实验中发现第一种方法效果优于第二种,所以在CSTM和CMM之后使用element-wise的和来集成信息,然后使用1x1的2D卷积来通道的维度,并且添加输入到输出的identity shortcut。整个STM网络的结构如上图的上半部分所示,使用ResNet-50作为backbone,将残差块都替换成STM block。
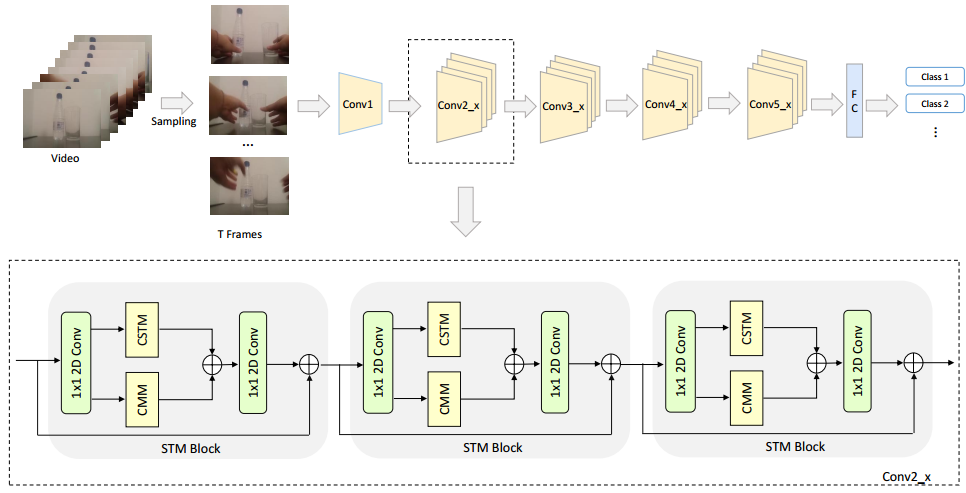
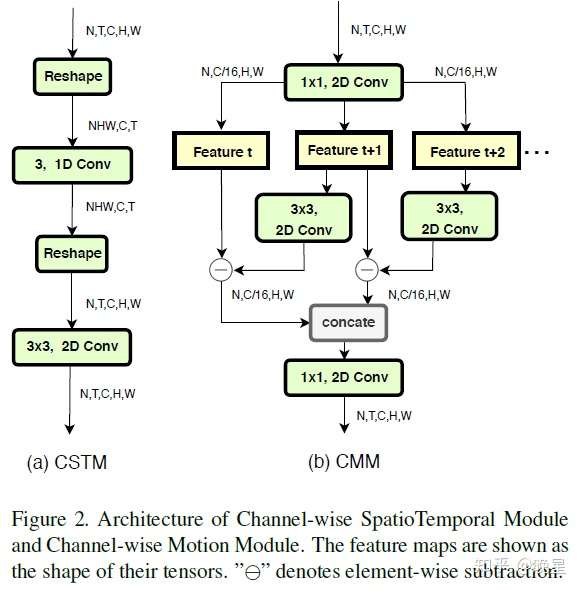
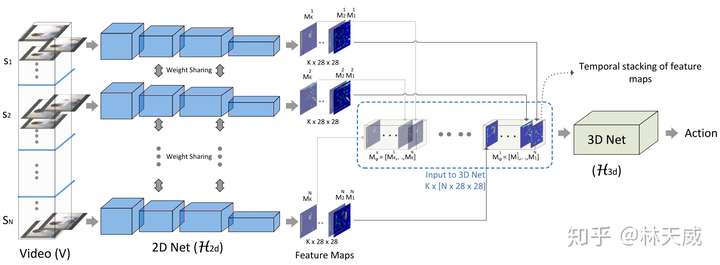
文章 [50] 是2D与3D卷积的并行设计,连续帧输入到3D卷积中,只采样”关键“帧输入到2D卷积中。如果将视频拆分为多帧做图像分类,2D的任务已经可以做出一定的精度了,所以在空间特征提取上没有必要使用3D卷积。
[50] Mixed 3d/2d convolutional tube for human action recognition (CVPR2018)

3. Gate-Shift Networks
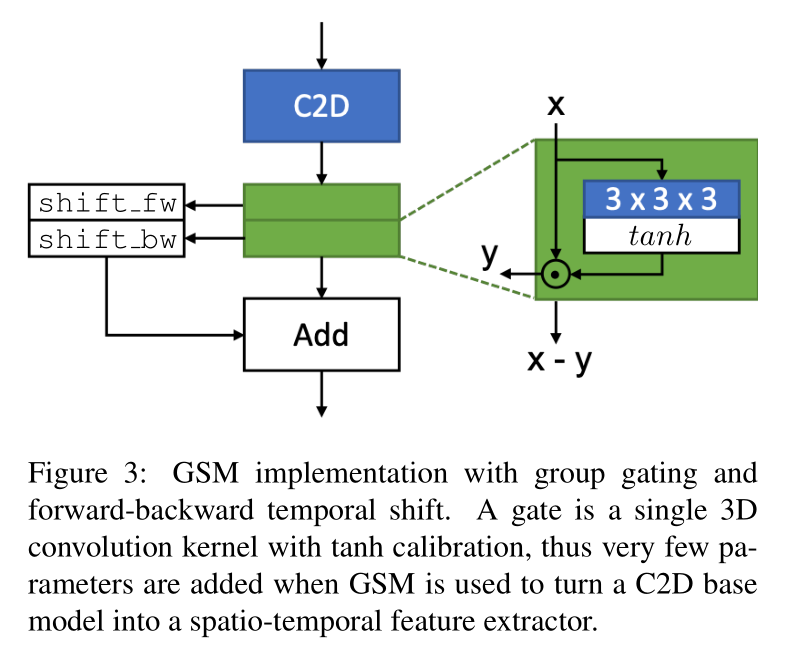
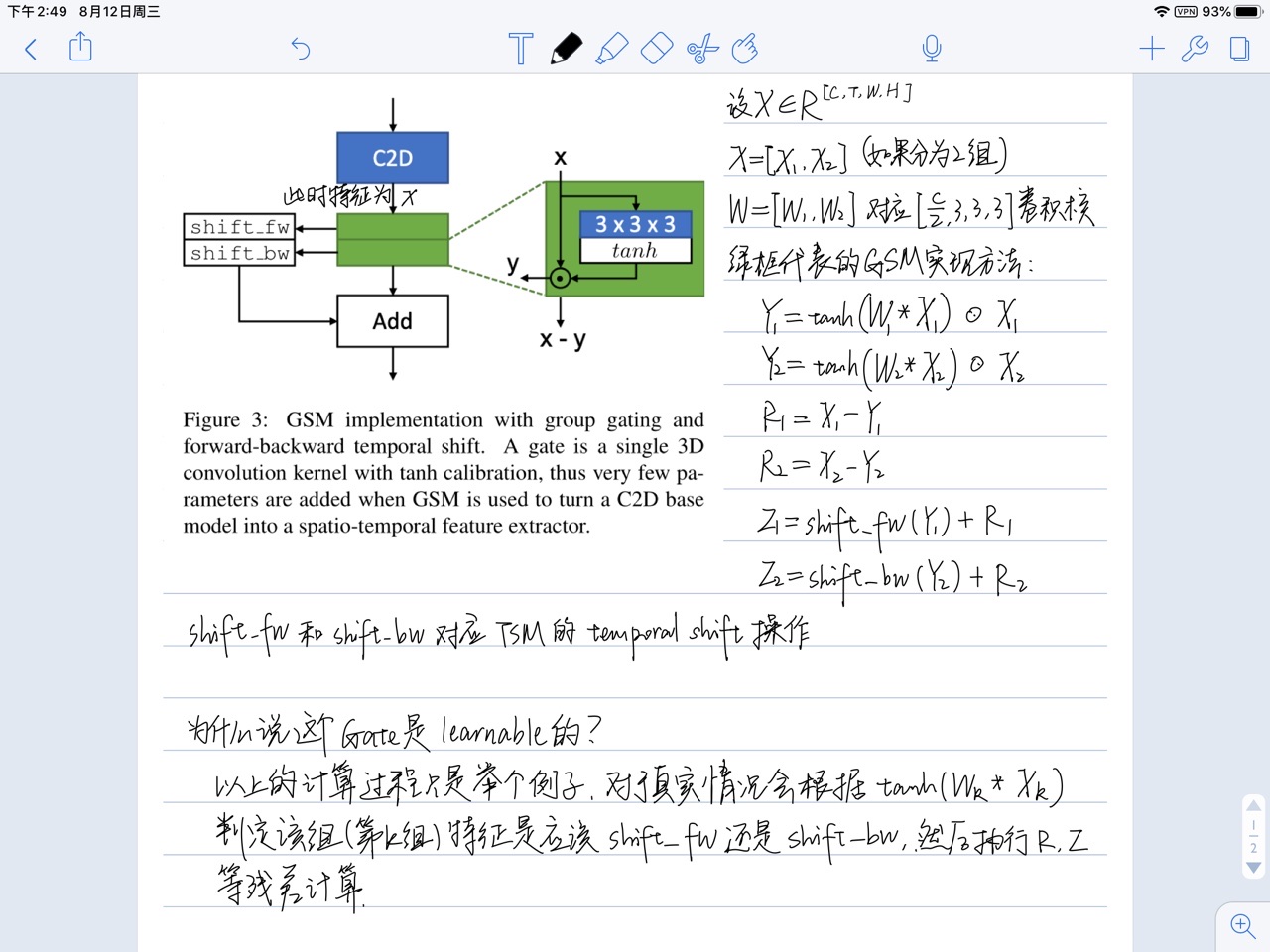
- RGB输入先通过C2D卷积
- 绿色的Gate模块
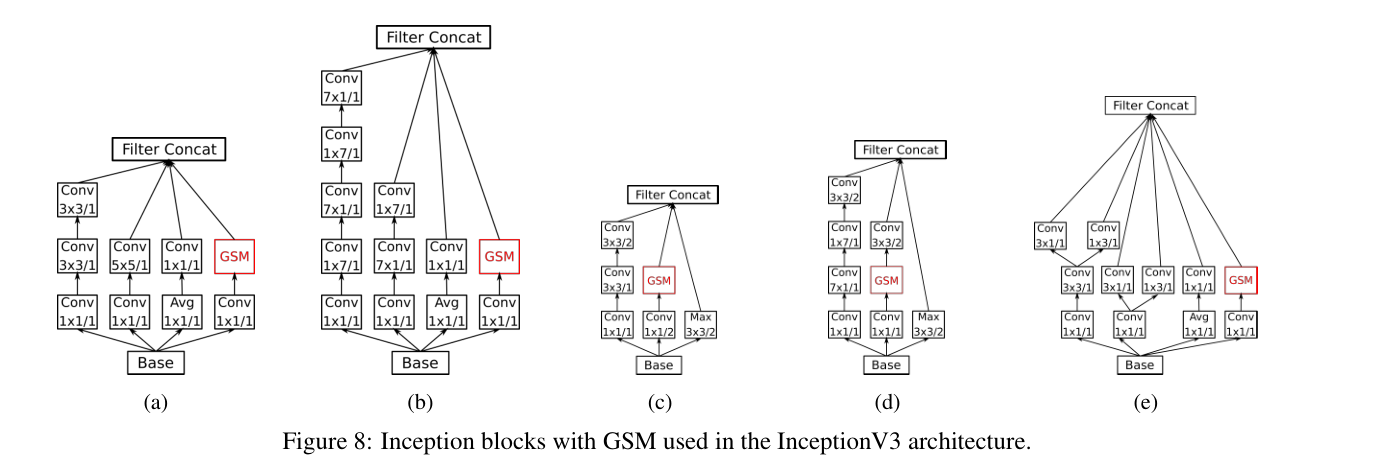
backbone 网络用的是王利民老师的 TSN 方法,也就是全2D网络,但是输入不再是双流,而是一组连续帧,最后 predict the action by average pooling the frame level (now spatio-temporal) scores。
本来认为会在 tanh 这里设置阈值,比如L1范数绝对值超过 0.5 就根据正负号进行 temporal shift,但是我好像想多了,因为本工作在整个BN-Inception block上只修改了其中某一个卷积层。。。
为什么用tanh不用sigmoid(二者都是激活在[-1,1]区间的非线性函数)?作者在4.3节消融实验发现tanh更好。
为什么把GSM加在图中标记的位置?作者在4.3节做了消融实验发现 GSM is most suited to be added inside the branch which contains the least number of convolutions.
4. Experiments and Results
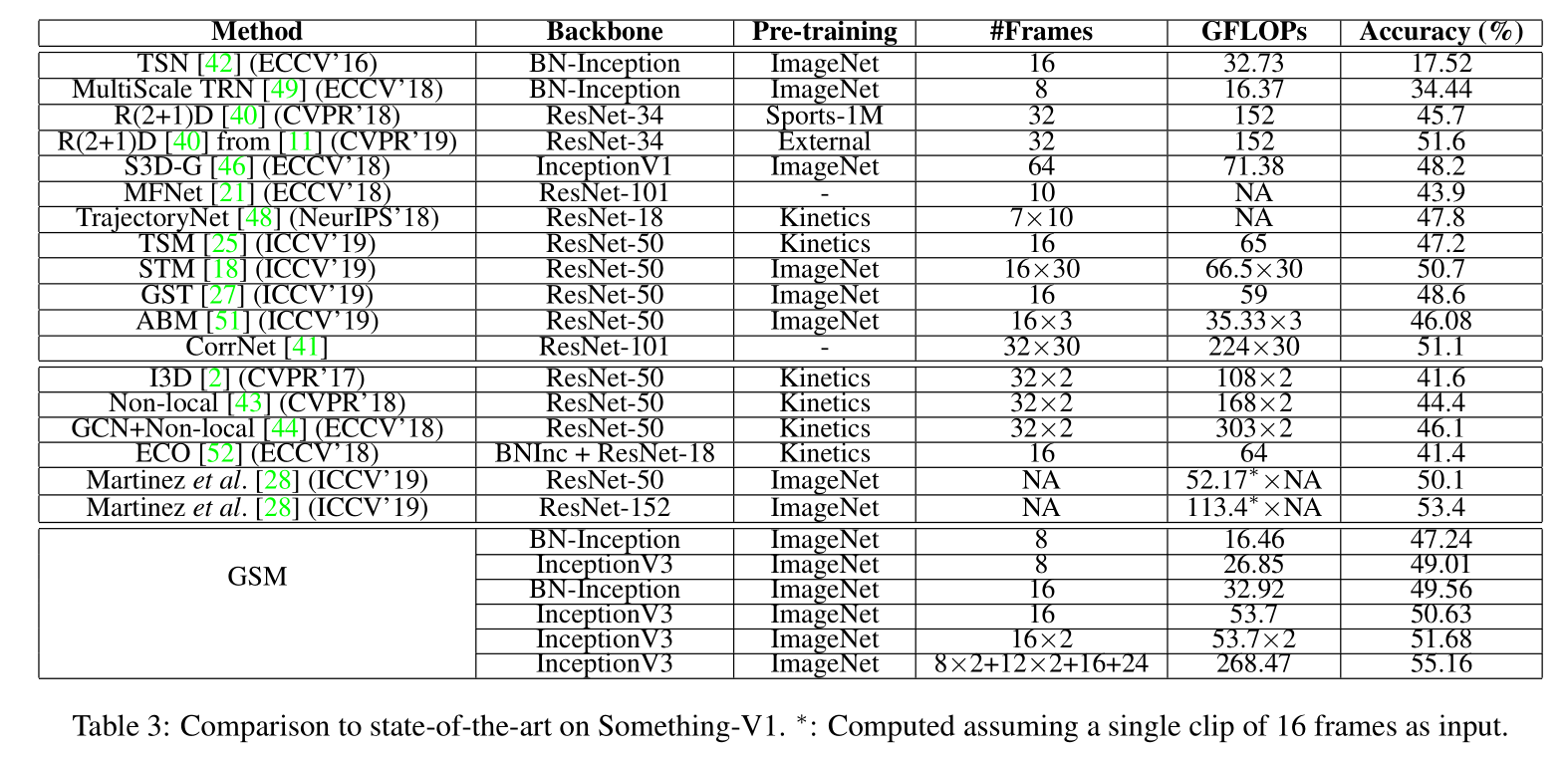
- Something-Something-V1
Diving48
- EPIC-Kitchens
4.5. Discussion

From the figure, it can be seen that the network has enhanced its ability to distinguish between action classes that are similar in appearance, such as Unfolding something and Folding something, Putting something infront of something and Removing something, revealing something behind, etc.
Baseline TSN 方法失败的地方是一旦出现 “Folding something” 和 “Unfolding something” 这种内容相似但是顺序相反的 action 就不行。在测试数据集上,故意地将视频帧按照相反的顺序输入到模型内,TSN 精度几乎不变但是 GSM 精度掉点严重。