论文名称:Polar Parametrization for Vision-based Surround-View 3D Detection
极坐标表示下的DETR,但是文章中没说用了多少query
Related Work 作者的其他工作:
《Vision-based Uneven BEV Representation Learning with Polar Rasterization and Surface Estimation》
《Efficient and Robust 2D-to-BEV Representation Learning via Geometry-guided Kernel Transformer》
Intro
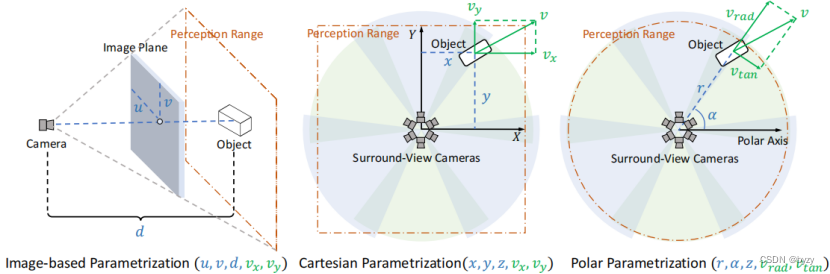
- 基于图像的位置参数化: 估计物体在图像中的像素索引和深度(u,v,d),再使用相机的内外参将该坐标转移到3D空间。通常用于单目图像。对于环视图像,该方法独立地在每个视角图像中回归边界框位置,然后投影到公共的3D空间。最后使用跨视图后处理如NMS滤除重复检测。缺点是深度估计误差较大,且多视图方法中相邻视图重叠区域提供的额外信息未被利用;跨视图后处理方法困难而不稳定。
- 基于笛卡尔坐标的位置参数化:bev视角下的感知范围是个矩形,问题在于(1)忽视了视图对称性(2)矩形检测范围给label assignment带来问题。
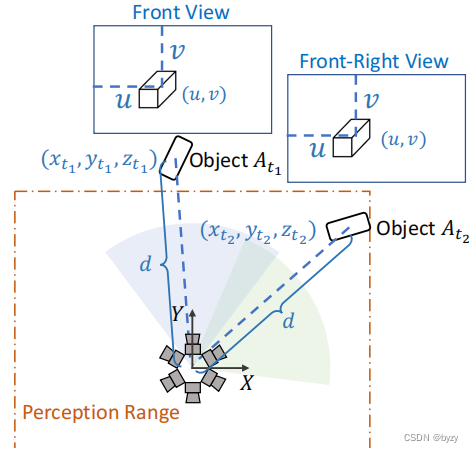
- 作者举了一个极端例子,同一个物体在不同的timestamp被不同的camera捕捉到,并且两次uvd相同。
- 由于检测范围为矩形(即只有检测范围内的物体会被标注),训练时仅考虑A_{t_1},而A_{t_2}被丢弃(即两个视图没有被同等对待),这对网络的收敛性有不利影响。
- 同时忽视了视图对称性。上图产生的两张图像,若用基于图像的参数化,学到的模型仅需要预测相同的位置(u,v,d);而使用笛卡尔参数化学到的模型需要预测不同的3D坐标,无疑会增加模型的复杂度,且优化模型更加困难。
- 这里引用了两篇文章《Bevdet: High-performance multi-camera 3d object detection in bird-eye-view》和《DETR3d: 3d object detection from multi-view images via 3d-to-2d queries》
- 作者举了一个极端例子,同一个物体在不同的timestamp被不同的camera捕捉到,并且两次uvd相同。
Method
各个关键组件的消融实验,baseline是DETR3D,极坐标表示真的行:

Box编码

也会编码速度估计 v_{rad} 和 v_{tan}
Decoder网络
过 Linear+MHSA 得到 center points,这里 follow 的是 deformable DETR 的做法
消融实验发现采4个context points就好

提出了一个 projection & sampling 的模块:通过相机内外参把3d center points投影到每个view,生成2d center points
然后在每个view上生成offset points

Pixel Ray as 3D spatial priors
将 pixel ray d_{ray} 沿 channel 轴加在所有 feature 后面,一种显式的位置编码
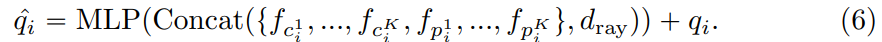
那么如何得到的 pixel ray?作者原文: pixel ray travels from camera’s optical center through the pixel to the corresponding 3D point。上图:

损失函数
GT 分配的代价函数:分类是交叉熵,损失是L1距离,k是scalar(后续实验设置k=20)

损失函数是分类focal loss加上回归L1损失
如何引入时间信息做速度估计
做法是把当前帧的3d points通过pose transformation matrix映射到过去帧的某个点,从而抽取过去帧的特征
pose transformation matrix which reflects the movement of the ego-vehicle in the time interval [t-n, t].
把当前帧的特征和过去帧的特征粗暴concat,更新query
文档信息
- 本文作者:Mengqi Cao
- 本文链接:https://rogercmq.github.io//2022/10/04/Polar_DETR/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)